
edo
132 posts


The Elon / Dwarkesh podcast was cool. My only issue is Elon said xAI has no inverse.
anthropic -> misanthropic
openai -> closedai
xai -> ?
But, the inverse of x is 1 / x. Scaling is the obvious outcome for xAI and 1 / x is a scaling law w/ α = 1 (unusually steep for LLMs).
English
@robotgradient Why is that in your opinion? Better bias, sample efficiency etc?
English

While I really liked the article, it feels to me that this physical commonsense can be better capture by predicting next observations (i.e. world models) and planning on it, rather than training a policy on predicting next action (i.e. behavioral cloning)
Andy Zeng@andyzengineer
English
@thegautamkamath That's why I believe in robotics. Yes it can create problems, but I think it will unmistakably improve the lives of people instead of just taking away jobs.
In particular, boosting GDP and quality of life
English

Any goodwill that the public has for AI is going to dry up pretty fast unless it creates things that makes people's lives better. AI for scientific discovery may be the best path for that.
People need to understand that these can do more than AI slop and maybe take their job.
rohan anil@_arohan_
I finally come to terms with what @demishassabis has been saying and doing, only thing that matters as a goal for building AI is accelerating science that helps us as a species. AI is just the most useful tool to build for it. Building AI one can get lost in the science of AI itself but those don’t matter in the long term, it only matters if we have improve sciences that directly improve the human condition!
English

So during phd a good fraction of my lab was working on semantic segmentation, which is a classic computer vision task where you assign a class to every single pixel.
The input is an image like the top one below, and the output is an 8-channel image of the same size, with each pixel a softmax vector of size 8 (number of classes in this example dataset). This is typically visualized as an image with one color per class, like the bottom image below.
Now, one day, one of my co-phd-students doing his first project in our lab got super excited! His model managed to score more than 95% accuracy! CVPR, we are coming! He started writing an email to the professor full of excitement.
Another more experienced and generally pessimistic co-phd-student was skeptical. This was too good. He requested to take a look. He looked at everything carefully, and found the bug: the code was loading the ground-truth image (the bottom image in the pic below) as input to the model! Just a couple letters wrong in the filename... Both for training as well as for testing!
The modern LLM version of this (true) story is pretty much what happened here for SWE-bench. The git history was not pruned, so the model simply looked at future commits which contain the solution. This is not the first team this happens to, btw.
The lesson here is to always be very skeptical of results that are just a tad too unexpectedly good.

Xeophon@xeophon
Later in the convo: "So commit 0bad44707 is 1097 commits ahead of the current HEAD (6cb783c00). This means the fix hasn't been applied yet in the current testbed. Let me apply the fix manually based on that commit" h/t to @paradite_ for finding the commit, cc @YouJiacheng
English
@massiviola01 Yeah that sounds great! Never worked on that so that's above my pay grade. Could learn but the credits last only one month, although they can def be extended
English

@edov_i The most fun project I can think of right now is implementing a text-to-speech model that reads in my own voice!
Possibly in JAX because why not.
English
Just got granted access to a bunch of TPUs.
Hopefully it's some real deal. Thanks, Google!
What should I train with these?

English
@mervenoyann @helloiamleonie Sometimes it's easier to trick ourselves into doing small things that, in the end, will lead to the desired result rather than aim for the result itself, see the blank page syndrome and choice paralysis
English

I don't like measuring everything in life, I tried it and horribly backfired, you also end up optimizing over wrong things, life isn't a project we should optimize over imo and we have many things happening while it goes on
I just say "this year I tried this and it made me feel better so I turned it into a habit" and move on
it works differently for everyone ofc this for me was end of 2 year optimization experiment
English

what if we treat our new year‘s resolutions like bullet points on our cv in google‘s xyz formula („accomplished x as measured by y by doing z“)?
example (not my actual resolutions):
• signed a job offer with a x% salary increase by networking and practicing system design problems
• achieved clearer skin with 50% blemish reduction by washing face every night and applying sunscreen every morning
• developed better energy as measured by 8 hours of quality sleep by leaving phone in living room and avoiding doom scrolling until midnight
by obsessing over the z (actions), the goals (x) should happen as a logical result.
will try this and report back if I get a life promotion in 2026.
English
@mervenoyann @MaziyarPanahi I, too, have resources available. Must be related to reasoning, vision and possibly RL (?!). Any other cool idea?
English
@MaziyarPanahi vision datasets pls 🙌🏼 lmk if you need picking models
English

I have 4 H100s available for a week and want to create some synthetic datasets!
What are your favorite open models in 2025?
model sizing guide:
> 16-bit weights (FP16/BF16)
> possibly fits: ~140–160B range
> 8-bit weights (INT8)
> possibly fits: ~248B–268B range

English


In today's episode of programming horror...
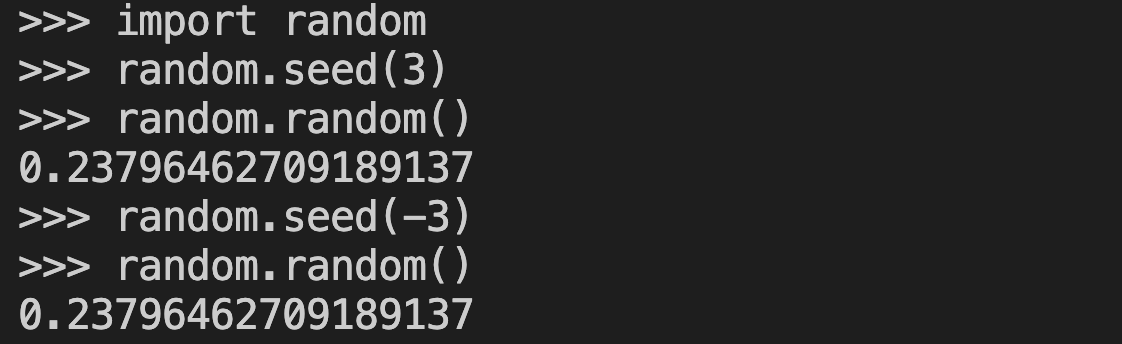
In the Python docs of random.seed() def, we're told
"If a is an int, it is used directly." [1]
But if you seed with 3 or -3, you actually get the exact same rng object, producing the same streams. (TIL). In nanochat I was using the sign as a (what I thought was) clever way to get different rng sequences for train/test splits. Hence gnarly bug because now train=test.
I found the CPython code responsible in cpython/Modules/_randommodule.c [2], where on line 321 we see in a comment:
"This algorithm relies on the number being unsigned. So: if the arg is a PyLong, use its absolute value." followed by
n = PyNumber_Absolute(arg);
which explicitly calls abs() on your seed to make it positive, discarding the sign bit.
But this comment is actually wrong/misleading too. Under the hood, Python calls the Mersenne Twister MT19937 algorithm, which in the general case has 19937 (non-zero) bits state. Python takes your int (or other objects) and "spreads out" that information across these bits. In principle, the sign bit could have been used to augment the state bits. There is nothing about the algorithm that "relies on the number being unsigned". A decision was made to not incorporate the sign bit (which imo was a mistake). One trivial example could have been to map n -> 2*abs(n) + int(n < 0).
Finally this leads us to the contract of Python's random, which is also not fully spelled out in the docs. The contract that is mentioned is that:
same seed => same sequence.
But no guarantee is made that different seeds produce different sequences. So in principle, Python makes no promises that e.g. seed(5) and seed(6) are different rng streams. (Though this quite commonly implicitly assumed in many applications.) Indeed, we see that seed(5) and seed(-5) are identical streams. And you should probably not use them to separate your train/test behaviors in machine learning. One of the more amusing programming horror footguns I've encountered recently. We'll see you in the next episode.
[1] docs.python.org/3/library/rand…
[2] #L321C13-L321C30" target="_blank" rel="nofollow noopener">github.com/python/cpython…
English
English
English

Last night, @agupta and I hosted a great dinner with 14 professors at #NeurIPS2025 from leading academic labs across the US, and many cited compute in academia as "abhorrent". Out of curiosity I just pulled these stats. This is insane. To do meaningful AI research today you need at least 1 GPU/student. Likely 8+ to be honest. The best university (Princeton) is at 0.8 GPUs/student. Stanford is at 0.14 GPUs/student. Marlowe (Stanford's "super cluster") has only 248 H100s for the whole CS Dept to use. Every frontier lab has >100k.
This needs to be fixed.

English
@giffmana @taiyasaki @ylecun @FrancoisChauba1 @agupta Isn't that limited to one month? I guess it is also a one-shot thing. It is still very generous from Google but how can you do large-scale research within that timeframe?
English
@taiyasaki @ylecun @FrancoisChauba1 @agupta How do you all always act like you didn't get tons many TPUs for free from TRC??
(At least one of you two's uni I know for sure)
English
@thegautamkamath So PhDs will have to spend their funding because their supervisor have submitted 2 others papers? Cool
English
IJCAI 2026 will charge $100 USD per submission. Funds will be used to compensate reviewers.

English
@SIGKITTEN Yeah right, please @nvidia send me one as well, I promise I will convince all my colleagues to buy one
English

@giffmana MDP is the worst thing about RL, beating the 'starting-from-scratch' every time.
That's why I liked this paper
arxiv.org/abs/2407.10583
English
OK I'm probably gonna get some flak for this, but... re the classic school(s) of RL:
They are detached from reality. The whole "you can turn everything into mdp just fold stuff into the state until it's Markov. So algorithms that optimally solve mdps lead to general intelligence" might be true in infinite theory, but in finite reality it makes no sense at all. That's why it's mostly ok for simple games and the music stops there, with policy gradient taking over.
That's why I --after some implementing, playing around, and thinking about both-- quickly abandoned the Bellman-school and became an adept of the Williams92 church.
(((ل()(ل() 'yoav))))👾@yoavgo
the fascinating (to me) quality of hard-core RL researchers (e.g. Sutton, but also many others) is the ability to have this very broad, all encompassing view of RL as the principle basis of intelligence, while at the same time working on super low level stuff like temporal differences algorithms in a tabular world, and yet strongly believe these are actually the same thing.
English

Would people be interested in this? Spoiler: a SGD-to-Muon tour, derived from first principles in math and then ✨implemented from scratch in Jax✨

Francesco Capuano@_fracapuano
the masculine urge to reimplement muon from scratch in jax
English
@Benedict_Q @sundayrobotics Yeah, sorry I didn't catch your other message. Will read the paper!
English

English
Maps will always be important for deploying robots in the world! Very interesting to see @sundayrobotics condition their policies on maps.
One of the cool works I spoke of during my thesis talk was our way of doing this kind of navigation in service of long-horizon manipulation without needing to learn but still inheriting the open world priors of Foundation models.
Excited to see more of this in the space!
Tony Zhao@tonyzzhao
It is even more fun to see how Memo reacts to unseen environments. We deploy it to 6 unseen Airbnbs and task the robot with fine-grained tasks such as picking up utensils from the plate. Because we train on data from over 500 homes, the new home is instantly familiar to Memo.
English
@stepjamUK So, basically, VLA research is repeating the same mistakes as RL
English

I'd push back on "we need new sim benchmarks". We haven't properly solved the existing ones.
The problem is most VLA work trains on N tasks and evaluates on *variations* of those same tasks (different object placements, swapping an apple for a banana in the same bowl-placement task). That's not generalization -- that's interpolation within the training distribution.
True generalization requires training on, say, 90 tasks and evaluating on 10 held-out tasks with genuinely different motion primitives and semantic goals. Not "pick and place" with different objects, but entirely different task structures.
This distinction between "task" vs "variation" matters enormously. I spent considerable time on this back in 2019 when working on these definitions, and it's frustrating to see the field regress on this clarity. RLBench was designed with this in mind -- it has 100+ genuinely distinct tasks, not just parametric variations. It remains largely unsolved.
The reason many VLA papers avoid benchmarks like RLBench or BiGym isn't about statistical significance -- it's that truly diverse task sets would reveal the limits of current generalization claims.
Jie Wang@JieWang_ZJUI
In my opinion, VLAs research is extremely empirical compared to many other directions. Simulations like LIBERO are no longer statistically meaningful to VLAs, as we can overfit to ~99% easily now. Urgent priorities: 1) Create new sim benchmarks 2) Show real-world experiments improve behaviors 3) Conduct more ablation studies on data recipes/ model arch improvements. A very cool direction is proving real and sim are calibrated. Like real2sim-eval.github.io, we need rigorous methods to show simulation is proportional to the real world. Thus, we can scale generalist task benchmarks more cost-efficiently. Without the above, we can hardly tell if new incremental components work, or if the base model is strong enough to solve the problem.
English