Nikos Karampatziakis retweetledi

A new version of 🤗 transformers has landed 🛬 v4.44 ended up being a performance-oriented upgrade for LLM users: faster compiled models, lower GPU memory requirements, and even support for mobile devices!
Let's dive 🤿 (resources in a comment)
1️⃣ `torch.compile()` updates
We've been working to expand and improve our compilation support! Recent upgrades include:
- `model.generate()` can be compiled! This is very experimental, and slightly faster than compiling the forward pass alone. More importantly, it opens the door to export the whole generate function into a single graph we can export, to be used in other devices ⚡️
- 3-5x faster compilation time of `model.forward()`, when used in `model.generate()`. tl;dr we now prepate a static-shape attention mask in generate. In essence, the same speed up, but less wait time the first time you run it ⌛️
- support for Whisper! Well, this was actually available since v4.43, released two weeks ago, but we haven't communicated much about it 🤫
2️⃣ CPU-offloaded KV cache
When you're using an LLM with a large context window, you'll notice that your GPU RAM quickly gets devoured by the KV cache. You had to spin up more/larger GPUs just to use the same model, or rely on CPU computations.
Not anymore! v4.44 includes a CPU-offloaded KV cache that only keeps in memory what it needs. In essence, while computing layer N, it moves to the CPU the KV cache for layer N-1, while prefetching to the GPU layer N+1. All computations happen on GPU. This is useful for large context windows or large batch sizes -- it allows you to run larger settings without upgrading your GPU, at a minimal speed penalty. Perfect for the GPU poor team 💛
This was kindly added to our library by @eigenikos 🤗
3️⃣ `torch.export()` support for generation
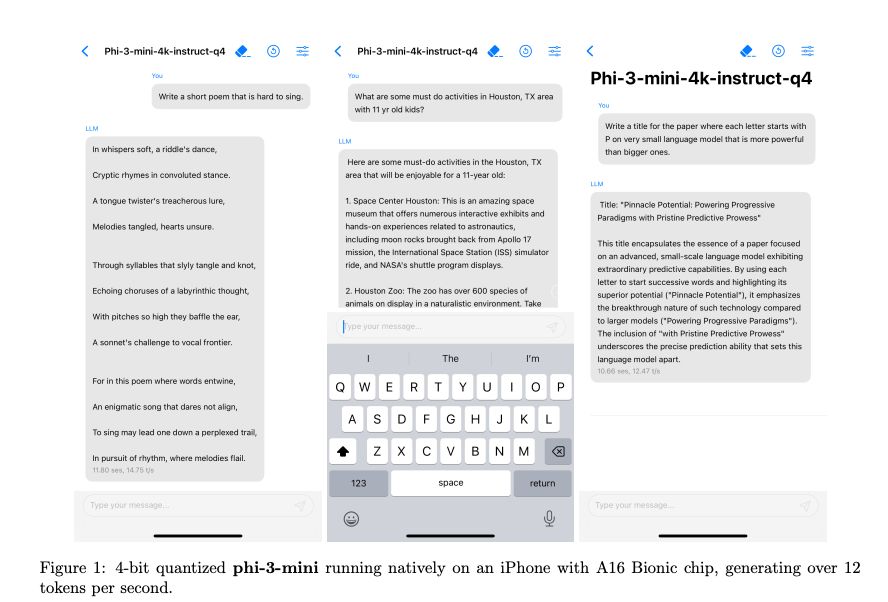
The PyTorch team is working on `torch.export()` -- in a nutshell, ahead of time compilation to enable multiple downstream uses. You can then use the exported graph with ExecuTorch in e.g. a mobile device!
We can now export LLMs with `torch.export()`. Support was kindly enabled by Guang Yang from the PyTorch team 🤗
And that's it for now! See you next release 🛫

English