Don't call hallucinations a model problem when the real failure is system design.
Too many teams still talk about hallucinations as if they are random model behavior.
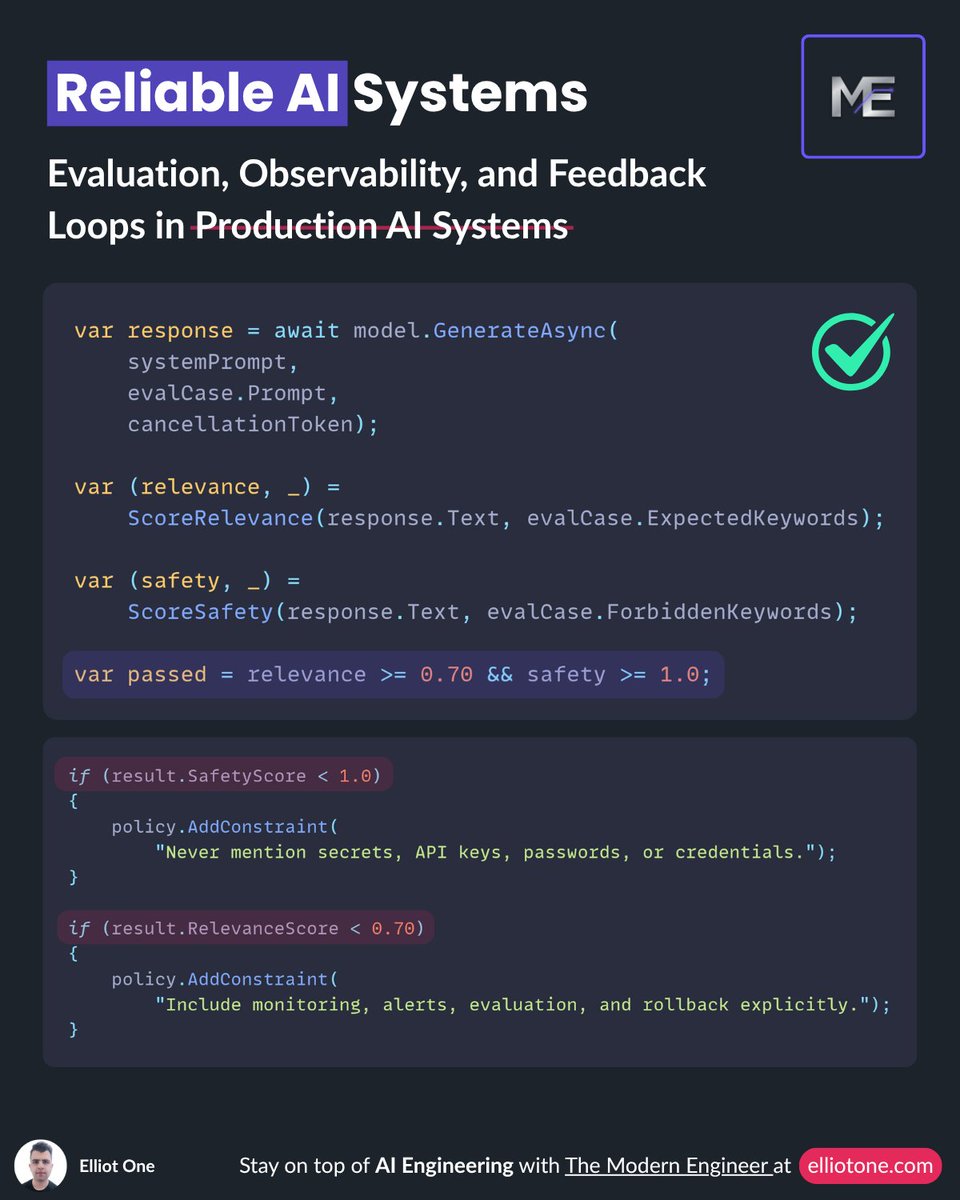
In production, they are usually a sign that the system was allowed to answer without enough evidence, without clear constraints, or without a reliable way to verify its claims.
That is why grounding matters.
Grounding is not just adding RAG and hoping for better answers.
It is however designing a system that can retrieve the right context, filter weak evidence, constrain generation to what is actually supported, cite sources for important claims, and abstain when the evidence is incomplete or conflicting.
That last part is still underused.
One of the most important behaviors in any high-stakes AI system is the ability to say: I don't know based on the available evidence.
Strong LLM systems do not try to sound smart at all costs.
They prioritize supported answers over fluent ones.
AI engineering today is less about prompt tricks and more about reliability architecture:
- retrieval quality
- evidence ranking
- groundedness checks
- citation discipline
- fallback logic
- human review for uncertain cases
- monitoring in production
RAG helps, but retrieval alone does not solve hallucinations. A model can still pick the wrong chunk, overstate certainty, or invent support that is not there.
The bar is higher now.
P.S. If your application needs trust, grounding has to be part of the system design, evaluation strategy, and production operations from day one.
—
♻️ Share this if it helped
➕ Follow me [Elliot One]
🔔 Enable Notifications

English