Sabitlenmiş Tweet
Elye
1.7K posts


Elye
@elye_project
Passionate about learning and sharing mobile development and its adjacent technology.
Katılım Mayıs 2016
228 Takip Edilen1.7K Takipçiler
What If Every Mass Layoff Required the CEO to Quit? 🤔
medium.com/tech-ai-chat/w… #SocialResponsibility #Workforce #AI #Trend
English

English
English
Generating a $0.10 customised tutorial programming lessons content! Customised knowledge is cheaper than ever!
medium.com/tech-ai-chat/w… #ArtificialIntelligence #Coding #Programming
English
Multiply your agentic coding potential even with just a single prompt.
medium.com/tech-ai-chat/s… #AgenticAI #Coding #AI #AgenticCoding
English
Expanding Your AI Coding Skills by Understanding How VS Code Copilot Works Under the Hood and How Its Context Window Is Structured
medium.com/tech-ai-chat/m…
#Copilot #VSCode
English
Custom Agent: Beyond VS Code Copilot Agent, Ask and Plan Mode
medium.com/tech-ai-chat/b… #VScode #Copilot
English
Claude Agent Skills - the Lazy Loading of AI Prompting
medium.com/tech-ai-chat/l… #VSCode #AgentSkills
English
Elye retweetledi

Why did we build Antigravity?
Our Head of Product Engineering @kevinhou22 breaks this down in his keynote from @aiDotEngineer
English
Stop Using Groups in Xcode! Seven Reasons Folders Are Better — Especially for Legacy Projects
medium.com/mobile-app-dev… #iOSDevelopment #Elye
English
Elye retweetledi
The reception to @antigravity has been absolutely incredible. We've filled with gratitude. Let's do a little show and tell with what the community has been building! 👇
English
Elye retweetledi

Google just dropped "Attention is all you need (V2)"
This paper could solve AI's biggest problem:
Catastrophic forgetting.
When AI models learn something new, they tend to forget what they previously learned. Humans don't work this way, and now Google Research has a solution.
Nested Learning.
This is a new machine learning paradigm that treats models as a system of interconnected optimization problems running at different speeds - just like how our brain processes information.
Here's why this matters:
LLMs don't learn from experiences; they remain limited to what they learned during training. They can't learn or improve over time without losing previous knowledge.
Nested Learning changes this by viewing the model's architecture and training algorithm as the same thing - just different "levels" of optimization.
The paper introduces Hope, a proof-of-concept architecture that demonstrates this approach:
↳ Hope outperforms modern recurrent models on language modeling tasks
↳ It handles long-context memory better than state-of-the-art models
↳ It achieves this through "continuum memory systems" that update at different frequencies
This is similar to how our brain manages short-term and long-term memory simultaneously.
We might finally be closing the gap between AI and the human brain's ability to continually learn.
I've shared link to the paper in the next tweet!

English
Elye retweetledi


Elye retweetledi

You went 🍌🍌 for Nano Banana. Now, meet Nano Banana Pro.
It’s SOTA for image generation + editing with more advanced world knowledge, text rendering, precision + controls. Built on Gemini 3, it’s really good at complex infographics - much like how engineers see the world:)
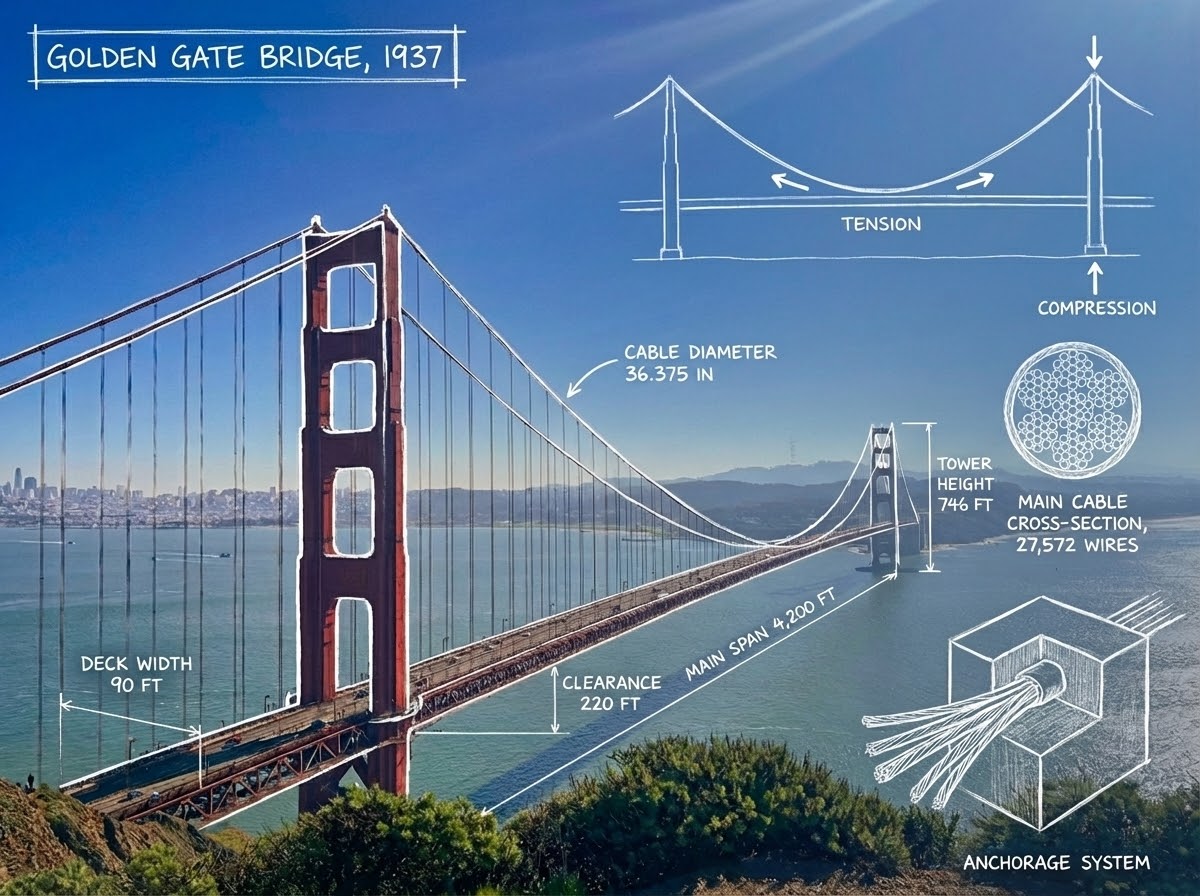
English
Elye retweetledi

My notes on Google's new Antigravity IDE - at first glance it looks like yet another VS Code fork but there are some interesting new ideas in there simonwillison.net/2025/Nov/18/go…
English
Elye retweetledi

Claude code is good
Codex is good
Cursor is good
Windsurf is good
Cline is good
Roo Code is good
Kilo is good
Amp is good
OpenCode is good
Aider is good
English
Elye retweetledi

Computer Science is not science, and it's not about computers. Got reminded about this gem from MIT the other day
English
