Sabitlenmiş Tweet
eraera
2K posts

eraera
@eraera
A blackbox is a network of blackboxes, the world is one such blackbox.
Seattle Katılım Aralık 2006
226 Takip Edilen1.2K Takipçiler
我做公司去中国出差,找中国分公司财务报销。财务甩我一句:我听吴总的。(吴总是我合伙人)我:你知不知道你们吴总是美国人,他把我身份证拿去办中国公司法人,理论上我是你老板。财务:我听吴总的。我:吴总你把身份证还给我,另外让财务给我一份完整中国公司收支流水,我找审计。
须影吟者🕊️@Phoenix_AlphaX
公司有个采购是真狠。 领导让他三天内搞定一批急用设备, 为了赶进度,他连夜联系供应商, 请人吃饭、送样品、跑仓库,最后总算把事情办成了。 结果回公司报销时, 财务一句话: “打车费超标,夜宵不给报,加急费用不符合流程。” 一共卡下来两千多,他一句没吵。 第二天,供应商来公司准备签长期合作, 他当着对方的面笑着说: “以后你们报价记得往高了报,我们公司流程比较复杂,很多费用员工得自己垫。” 供应商当场愣住。 原本谈好的低价合作, 当天直接涨了15%。 老板后来知道这句话是他说的, 气得差点拍桌子。 但最扎心的是, 他说的其实全是真话。
中文
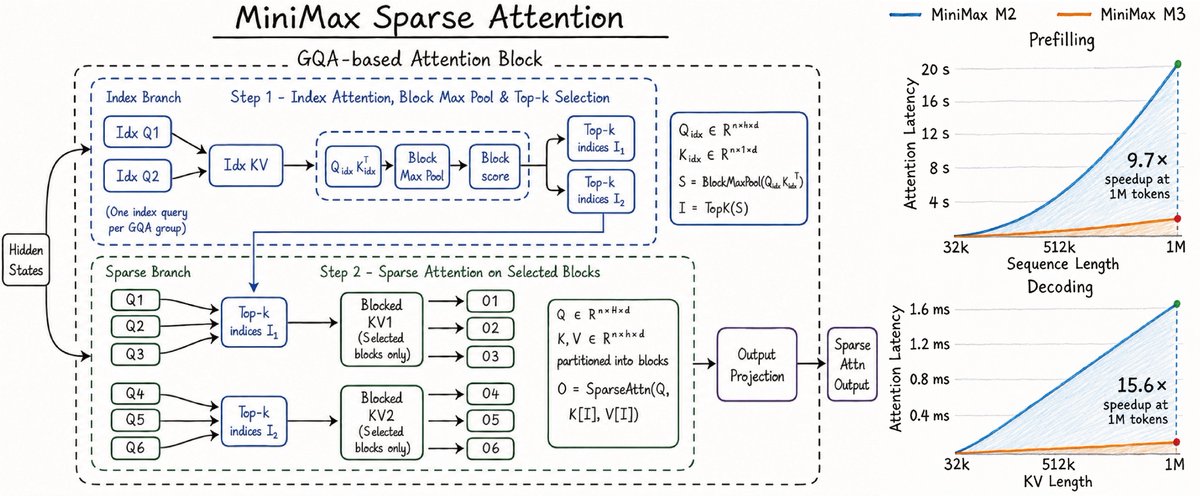
@SkylerMiao7 if I read your graph correctly, the speedup came from utilizing the sparsity of the model, rather than from reduced KV size?
English


印度也是牛B的,居然想对苹果罚380亿美元,这次印度专门为了罚款修改法律,把基数改成全球营业额,这种操作闻所未闻
苹果2025年在印度营收才90亿美元,净利润仅3.6亿美元,却面临380亿的罚单,相当于要白干105年才能赚回来
苹果被指控的”苹果税”问题在欧盟、美国、韩国同样面临类似指控,并非印度独有的打压,印度这次借势收割属实牛B plus~
中文

那段岁月好的地方我都写在博客里面了,今天给你们讲一讲为什么叫做一腔热血喂了狗
那8年,我真的是把我的青春和我的所有一切都投入进去了,每天工作16个小时以上
但是后面换来的是什么呢?
每天,CEO住在北京,跑来武汉,每个月都要批判我,跟我说我不适合当总经理。整个团队是我从0开始建的,我遇到了技术大佬,我都说大佬,我们开不起你的工资,所以我不骗你,你不用来了。我为公司付出了一切,这个老板却听信这些在北京喝茶的人,每天污蔑我
然后每次去北京开会,都像岳飞去朝廷开会一样的,欲加之罪,何患无辞。我每天工作16个小时,最后换来的就是什么呢?奸臣当道。每天换着法子恶心我。我一个研发的负责人、产品的负责人,然后有时候还跑销售和售前喝酒,一天喝三场,扣无数次喉咙,你们相信吗?最后被这帮人整的,说图标怎么画,都要跟总经办汇报,当时我是性情中人,我说去你妈的,我直接从总经办的群退了,我说你们爱怎么办怎么办吧
我记得2016年,有一个项目是全公司努力的项目。做操作系统的移植,工作量巨大。传统的企业不做个三年都做不出来,然后甲方只有半年。我们拼尽了一年,每天16个小时加班。做到最后,兄弟们都跟我说一句话,他说老王不要提加班费了,我不要了,我只想休息。就是这样一堆拿着白菜的钱,做白粉生意的兄弟,在坚持理想。然后CFO有一天跑到行政的前台说,定了一个规矩,晚于10点钟加班的不算加班。当时我路过。我直接停下来说,你说什么?你再说一遍,你敢不敢再说一遍?我说我们这帮人为了公司浴血奋战,你们在北京天天喝茶的人,定的什么狗屁规矩!?
我记得武汉发大水那一年,我每天出差,然后一个月被偷了三辆电动车。那天下大雨,我记得特别清楚。那时候没有车,也打不了车,我的电动车也没有。我就推着自行车和我老婆把我小孩推了两公里到幼儿园。我们仨淋得全湿,然后到幼儿园以后,我从书包里面拿的干净的衣服跟小孩换的衣服。我当时特别的悲伤,我就觉得我跟公司奋斗了这么多年,连保护家庭的基本条件都没有。所以当时我跟公司离职。然后这个狗屁的CEO跑来武汉我们家楼下的麦当劳,骗我老婆说,因为我是公司的核心高管和创始人,投资人规定公司的核心高管不能涨工资。我当时真他妈的善良啊,我和我老婆都相信了,哭着相信了,因为我们真的走投无路了,每个月都月光,每一个月呀。然后我现在出来创业,我发现只要你想给你同事涨薪水、发奖金,你有一万种方法,一万种方法可以给他们钱
这个CEO干的事情还没有完,我记得2017年,我依然去朝廷开会。他约我谈,说我的综合评价是50%,所以不涨工资。我说,我作为创始已经习惯了,这个不涨工资没关系,我能理解公司难处。但是你这个50%,你跟我说一说怎么来的,他说,你做产品是200%,但是你跟同级的沟通是30%,所以综合评价50% 我说,我跟哪个同级的沟通是30%?那些奸臣吗?那些每天在北京坐着喝茶,每天只会诋毁我,每天不知道干活,每天不知道服务客户,每天跟客户扯皮的人吗?我为什么要跟这些不是创业者的人好好沟通?我作为创始人,我就应该监督他们,他们都是我招聘的,现在你作为CEO,你不去看真实的情况,北京那帮渣渣每天在你耳朵边子嚼我坏话,你就相信了吗?
最后我走是什么原因?我可以给你们今天爆料一下,2018年1月份到3月份,我为了支持全国的销售,整整60天没有休息。有一天突然就发高烧了,烧到39度多,人都烧迷糊了。然后我周六爬起来,我说,哎呀,这个星期睡了两三天,没给公司干活。我说我周末起来加个班。然后就看到公司扣了我2000块钱,我为公司奋斗了8年呀,创始人呐,你们都不知道,那时候我的税前工资都不到1万5,每个月都月光,扣了2000块钱。我就去问行政,我说这2000块钱为什么要扣我的,行政的小姑娘不敢跟我说,她让我去问财务总监。我就去问财务总监,我说你为什么扣我2000块钱。财务总监说,因为你没有写周报。我当时就火大了,第一周报机器人是我开发的,第二,周报机器人,我没有勾我自己,我每周都写周报,只是周报机器人没勾我。然后你是总经办的群,我每次写周报都会自动通知你们。你每天都可以看到,你都可以看到,即使机器人没有发邮件,你每天都可以看到,你来恶心我。你最恶心的是,你上个月的总经办的PPT还写的是,作为创始团队,大家要互相信任,这就是你的信任吗?
那一天是2018年的春天,我大病初愈,我真的被这个总经办团队恶心透了。我觉得这个总经办团队赚钱能力不行,恶心人能力一流,关键CEO就是一个糊涂蛋,CTMD
所以那天我跟公司发了一个邮件,我说第一,我离职不干了,净身出户。第二,我今天就发一个邮政快递,算是正式通知你们,不管你们同不同意,一个月后我滚蛋
我走之前没有说过任何话,只是请大家吃了顿饭,也没说我要走,只是伪装成一次普普通通的团建。我走之前把所有兄弟们都安顿好了,保证我走了不会影响他们的工作。等一个月以后,我就突然就走了
马上快超出推特大V的篇幅限制了,最后一句话,一腔热血喂了狗
Mutse Young@mutse_young
@manateelazycat 老板,开播客讲讲那段岁月
中文



现在还有个零阶,因为上网久了你会发现大部分人就是阅读障碍,想让他们做“看到什么就信什么”的传声筒,你的内容不能写的太复杂,最好就是一两句口号式的表达,否则阅读障碍根本看不完理解不了
Pangyu 胖鱼 🐠@pangyusio
人和人认知的差距,本质是思维阶数的差距。 只有一阶思维的人,看到什么就信什么,听到什么就传什么。这是大多数普通人的状态,他们一辈子都活在别人给的叙事里。 有二阶思维的人,会追问一句"为什么"。他们能看到表象背后的机制、利益和动机。这类人通常是知识分子,能写文章、能分析问题、能在饭桌上让人觉得"有点东西"。 而真正的智者和哲学家,拥有三阶、甚至四阶思维。他们不仅能看穿机制,还能反思自己看穿机制的这个过程本身——自己的立场是怎么形成的,自己的认知有什么盲区,人类的理性本身又有什么边界。 阶数越高,世界越复杂,但人也越自由。 绝大多数人终其一生卡在第一阶,连第二阶的门都没摸到。
中文
权游,指环王这些是基于欧洲历史的玄幻,比较好写历史演化。爽文没有历史框架就很难写,写了也不好卖。爽文都不能仔细想,仔细想了全是漏洞
Tinyfool@tinyfool
你看基督山伯爵,其实就是个爽文框架,被冤枉的人,获得超现实级别的资源,然后回来让所有害过他的人一个个付出代价。肖申克的救赎其实也是。
中文
@Necokeine @IctyeP JIT的bytecode还是比较好看的,hotspot以后的优化会稍微难一点,也不是特别难。GC这个事情跟语言代码生成关系不是很大,属于附加的
中文








补充说明一下,关于AI涌现出来的那些现象,scaling law、emergence、双重下降、表征几何,目前相关讨论的论文已经汗牛充栋。但这里有一个很大的问题:他们都在用计算机科学家的方式思考,而不是物理学家的方式思考。
什么是计算机科学家的思维方式?看到一个现象,挑一组数学工具,做一个小实验,去凑解释,可能抓到一点,也可能没抓到。然后再换一个工具,换一组数据,再凑一次。你问他们什么叫做充分必要条件,他们是不管的。这不是科学,这是建模。
物理学的方法完全不同。从一堆纷乱的现象里,提炼出你认为最fundamental的那一组,把它理想化,建立一个孤立的、几乎不存在但概念上清晰的"理想系统"。然后在这个理想系统里把规律彻底搞清楚,最后才一步一步扩张到真实世界。
牛顿第一定律就是这样建立的:"不受力的物体永远保持匀速直线运动。"但这条定律不是随便在哪里都成立的。地球上不行,因为地球在自转;太阳系里也不行,因为整个太阳系在绕银河系中心运动;你在跑步、在转椅上、在加速车里,都不是好的参考系,因为它们都在加速。牛顿的处理方式是:只有相对于无限远的恒星天空,才存在一个"绝对参考系",定律在这里才严格成立。这是一个悬在半空的理想态,现实中无法到达,但概念上必须存在。所有真实的力学问题都是"相对于这个理想态的偏离",重力,离心力、科里奥利力、摩擦力,都是因为我们所在的参考系不是惯性系才产生的。
没有这个悬在半空的理想态,整个经典力学就建立不起来。
这就是为什么我要引入Cyber Space这个概念。把AI现象放在Cyber Space这个独立世界里,我们才能用物理学家的方式问问题:Cyber Space的"惯性参考系"是什么?什么是它的"理想气体"?什么是它的理想态,那个Space中几乎不存在、但概念上必须首先确立的起点?
这个问题目前没人在认真问。但只有问出这个问题,新的数学和新的理论才有出发点。否则我们就只能继续看着AI论文堆成山,每一篇都"差不多解释了一点",但永远建不起新的基础理论。
snowboat@snowboat84
今天讨论点硬核的。一个问题:AI用到了什么程度的数学? 从工具和模型本身看,AI用到的数学平均年龄150岁,绝大部分是19世纪中叶之前就有的:矩阵乘法、梯度下降、链式求导、傅里叶、内积、概率,大都是本科前两年的内容。 但AI涌现出的一些现象,目前最高深的数学都解释不了。我整理了几个排名靠前的: - Scaling Law:把模型做大、数据加多、算力堆够,模型的损失会沿着一条极其干净的幂律曲线下降,log-log 图上几乎是一条直线。一个有几千亿参数、内部高度非线性的庞然大物,宏观行为竟然如此有规律。为什么会这么规则,没人知道。 - Emergent Abilities:三位数加法、多步推理、写代码这些能力,小模型几乎无能为力,但是模型参数量越过某个阈值,模型变得足够大,模型突然就都会了。这在物理上和水变成水蒸气是同一类现象——相变。但水的相变有完整理论,AI 的“能力相变”什么模型都没有, - Double Descent:传统的统计学习理论告诉我们:模型越大越容易过拟合,测试误差应该先降后升。实际观察到的误差曲线是:先降、再升、然后继续往下降,最终掉到比经典理论的最优点更低的位置。一整套统计学习理论被大模型颠覆,为什么?没有公认解释。 - In-Context Learning:GPT-3之后出现的新现象。给模型几个例子,它不更新任何参数就能完成新任务。按理说"学习"必须改变参数,可大模型在推理过程中能现学现用。这意味着模型内部藏着某种我们看不见的"学习的学习"。数学上这是什么?也没人能说清楚。 - Representation Geometry:模型内部到底学到了什么?A社的可解释性研究发现了一个奇怪的现象:单个神经元同时编码了好几个互不相关的概念,比如同一个神经元既对"金门大桥"有反应,也对"日语"有反应,还对"DNA 序列"有反应。按理说一个维度只能表达一件事,但神经网络似乎找到了某种"叠加"技巧,在有限的维度里塞进了远超维度数的特征。 为什么会这样?没有数学能解释。 类比一下物理,十九世纪末的物理学主要靠微积分就够用了。但当时天空中飘着几朵"乌云":黑体辐射、光速实验,当时的理论解释不了。这几朵乌云后来炸出了量子力学和相对论,逼出了20世纪最新的数学(泛函分析、微分几何、数学结构化)。 AI现在的处境很像1900年的物理学:工具老得不能再老,结果好得超出预期,但留下了一堆解释不了的现象,现有的数学工具完全无能为力。 如果历史会押韵,这些“AI的乌云”很可能正是21世纪数学下一次大发展的引爆点。
中文



彼得·蒂尔表示,6 位 PayPal 创始人中有 4 位在小时候造过炸弹:
“我不在那几个造炸弹的人之列。”
“那是在深夜进行的一次十分离奇的对话。当时大家纷纷聊起,‘你上高中时都干了些什么?’‘我造了一颗炸弹。’‘我也造过。’”
“选择创业的人身上往往带有一种非常极端的特质。创办一家公司本身就是一件极其疯狂的事情。”
“但只要你迈出了创业这一步,你就绝不会希望把过度疯狂当成一种优良品质,因为这种疯狂同样也会毁掉你的事业。”
柴郡🔔|Crypto+AI Plus@0xCheshire
彼得·蒂尔表示,当他在 2008 年投资马斯克的 SpaceX 时,人们发邮件给他,庆幸自己没有投资 Founders Fund ,因为“任何投资像火箭这种疯狂事物的人,都不该涉足风险投资”。 “伟大的投资表面上看似疯狂,但实则不然。”
中文

