erenup
27 posts



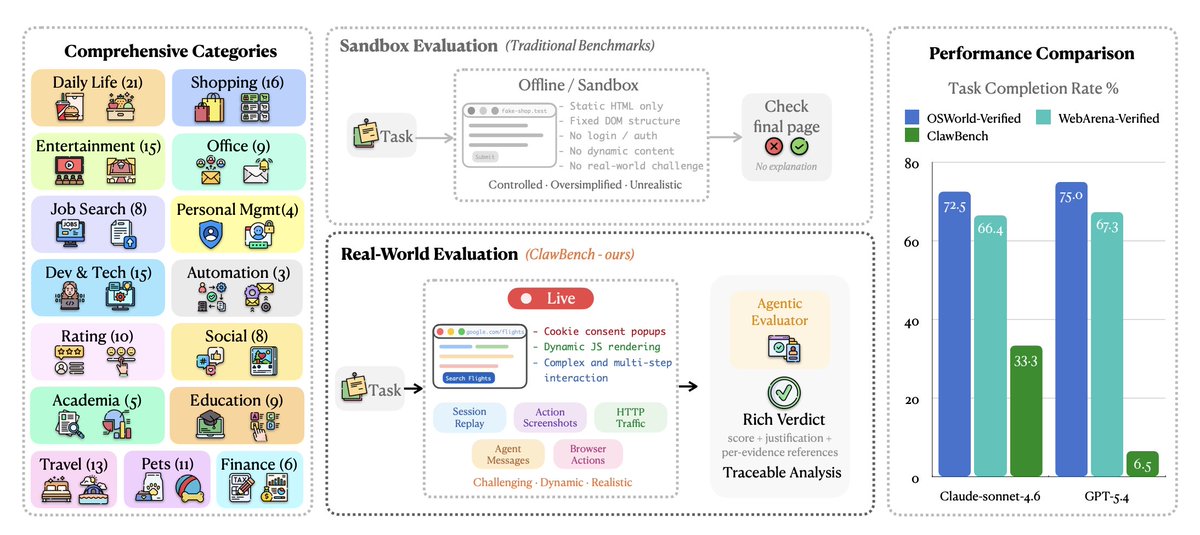

ClawBench: Can AI Agents Complete Everyday Online Tasks? A real-world benchmark for AI agents: 153 everyday online tasks across live websites (shopping, booking, job apps). Even top models struggle—dropping from ~70% on sandbox benchmarks to as low as 6.5% here.



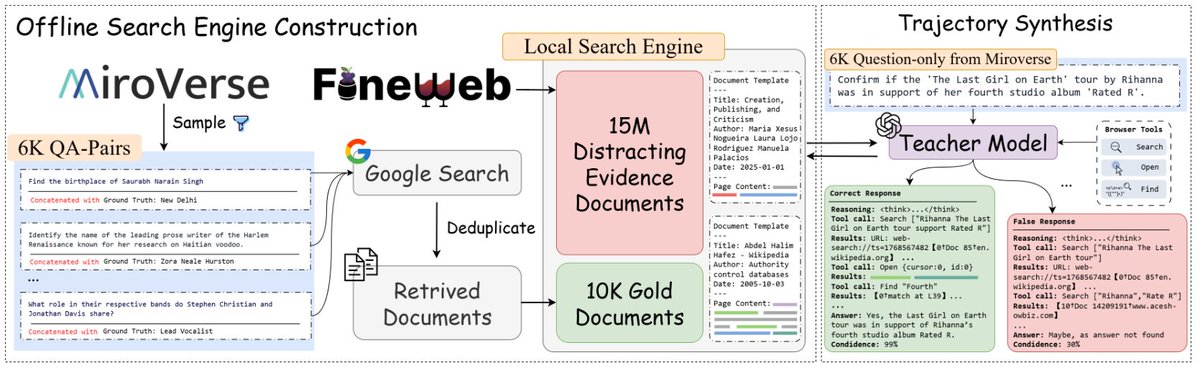
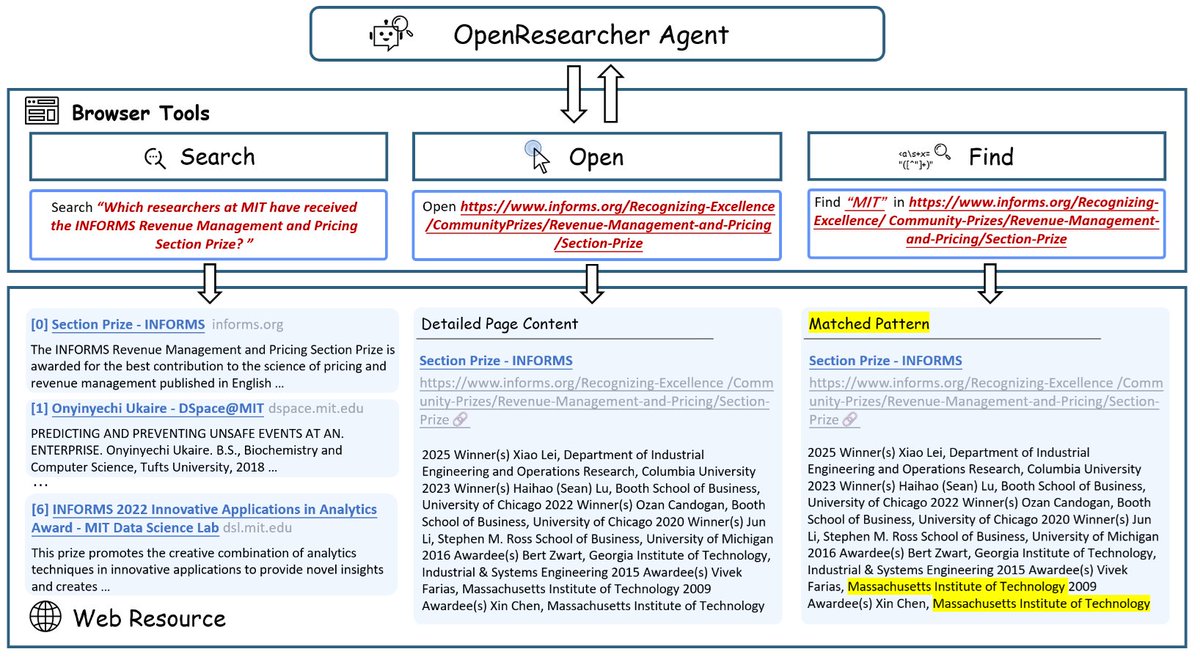
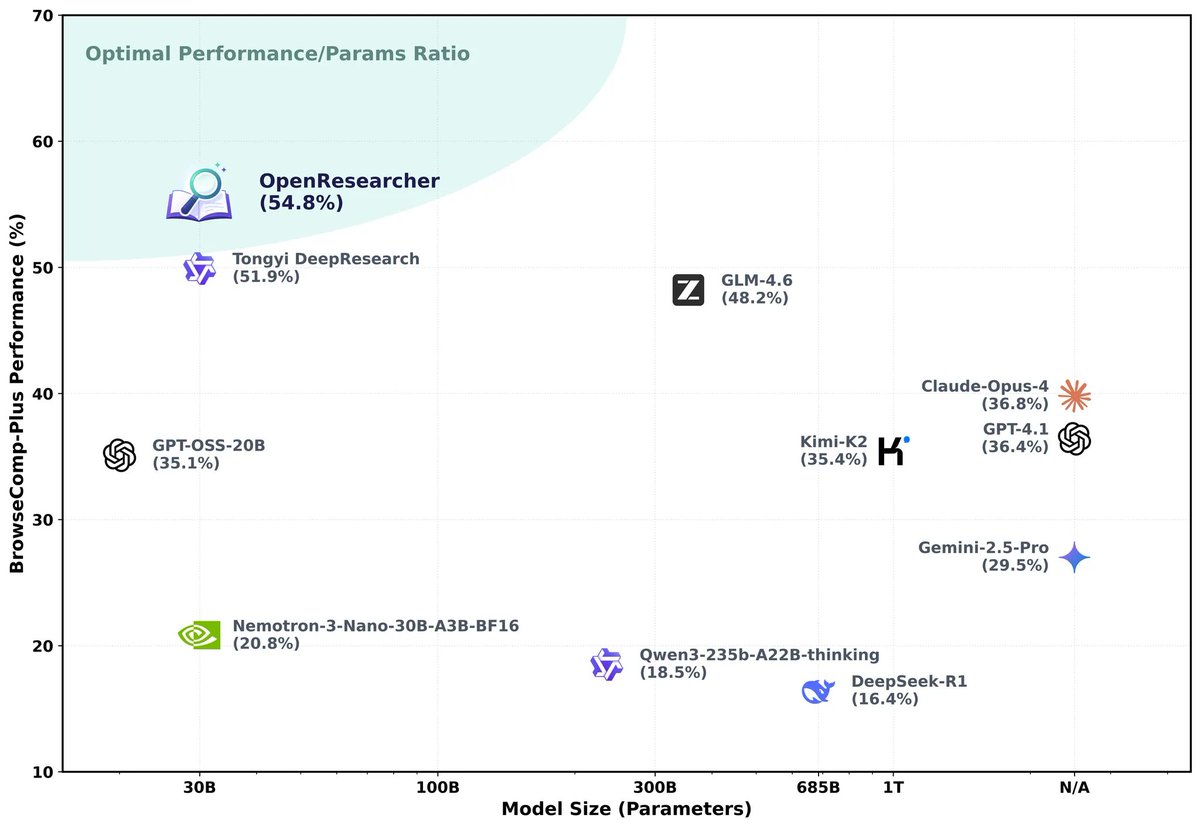
🚀 Introducing OpenResearcher: a fully offline pipeline for synthesizing 100+ turn deep-research trajectories—no search/scrape APIs, no rate limits, no nondeterminism. 💡 We use GPT-OSS-120B + a local retriever + a 10T-token corpus to generate long-horizon tool-use traces (search → open → find) that look like real browsing, but are free + reproducible. 📈 The payoff: SFT on these trajectories turns Nemotron-3-Nano-30B-A3B from 20.8% → 54.8% accuracy on BrowseComp-Plus (+34.0). 🧩 What makes it work? 🔎 Offline corpus = 15M FineWeb docs + 10K “gold” passages (bootstrapped once) 🧰 Explicit browsing primitives = better evidence-finding than “retrieve-and-read” 🎯 Reject sampling = keep only successful long-horizon traces 🧵 And we’re releasing everything: ✅ code + search engine + corpus recipe ✅ 96K-ish trajectories + eval logs ✅ trained models + live demo 👨💻 GitHub: github.com/TIGER-AI-Lab/O… 🤗 Models & data: huggingface.co/collections/TI… 🚀 Demo: huggingface.co/spaces/OpenRes… 🔎 Eval logs: huggingface.co/datasets/OpenR… #llms #agentic #deepresearch #tooluse #opensource #retrieval #SFT





We spent a year developing cde-small-v1, the best BERT-sized text embedding model in the world. today, we're releasing the model on HuggingFace, along with the paper on ArXiv. I think our release marks a paradigm shift for text retrieval. let me tell you why👇




𝗛𝗼𝘄 𝗰𝗮𝗻 𝘄𝗲 𝗯𝘂𝗶𝗹𝗱 𝗺𝗼𝗿𝗲 𝗿𝗲𝗹𝗶𝗮𝗯𝗹𝗲 𝗟𝗠-𝗯𝗮𝘀𝗲𝗱 𝘀𝘆𝘀𝘁𝗲𝗺𝘀? Our new position paper advocates for retrieval-augmented LMs (RALMs) as the next gen. of LMs, exploring the promises, limitations, and a roadmap for wider adoption. arxiv.org/abs/2403.03187 🧵