Sabitlenmiş Tweet
Eric Alcaide
1.4K posts


Eric Alcaide
@eric_alcaide
Design is not finished. Common prosperity. LLMaxxing @poolsideai
LLMaxxing Katılım Eylül 2016
1.2K Takip Edilen1.9K Takipçiler

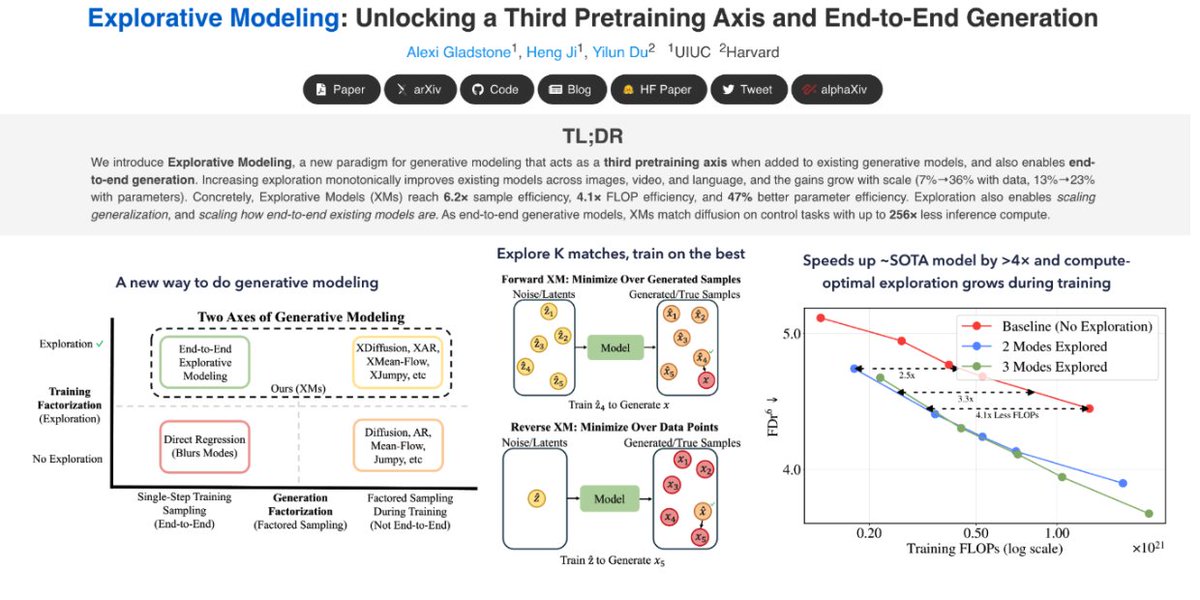
We discovered a third pretraining axis beyond parameters and data: exploration.
Scaling exploration monotonically improves existing models across images/video/language, and unlocks end-to-end generation.
In the simplest case, it's just a for loop.
Introducing Explorative Modeling.
TLDR:
- Gains from exploration grow with scale: 7%→36% as data scales, 13%→23% as parameters scale, and gains double at 3× the compute
- Adding exploration to ~SOTA baselines improves data efficiency by 6.2×, FLOP efficiency by 4.1×, parameter efficiency by 47%, and hits a near-SOTA 1.43 unguided FID on ImageNet
- Exploration lets you trade training compute for generalization, and scales how end-to-end your generative model is
- End-to-end Explorative Models (XMs) match diffusion performance on control tasks with up to 256× less inference compute
🧵Thread:
English

Inkling-Small looks better on paper than DeepSeek v4 Flash and MiMo-V2.5 and supports audio and images.
Please let this model be good...
In progress

Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English

Tilde seems like such an underrated neolab (purely judging by seeming quality of work vs valuation order of magnitude bracket)
Tilde@tilderesearch
Introducing Online KL Shampoo (OKLS), an optimizer that brings a KL-optimal approximation of full-matrix AdaGrad to language-model training. Diagonal optimizers ignore correlations between gradient coordinates. Full-matrix AdaGrad captures this geometry but requires quadratic state. Muon considers correlations but not their history. OKLS closes this gap using KL-optimal Kronecker factors, whitening matrix gradients across both row and column directions while remaining naturally scale-invariant. The main challenge is computing fresh inverse-square-root preconditioners at every step. Even one-step staleness can destabilize training. We make zero-staleness preconditioning practical with Scaled CANS Coupled Newton–Schulz: 10 iterations, 27 FP16 GEMMs, and FP32 accumulation. OKLS achieves 1.45× the parameter efficiency of Muon while retaining 98% of its training throughput. Across 200M–1B models, an OKLS model matches a Muon model roughly 1.5× larger.
English

Same architecture, same size as the preview — Terminal Bench 61.8 → 82.7, DeepSWE 7.3 → 54.4.
All of it from post-training. Very impressive. Congrats! 👏
DeepSeek@deepseek_ai
🚀 DeepSeek-V4-Flash Official API is now LIVE in public beta! 🔷 We’ve massively upgraded its Agent capabilities—benchmark scores are now far surpassing the V4-Pro-Preview. Check out the massive performance leap below! 👇 🔷 The official V4-Flash now natively supports the Responses API format and is fully adapted for Codex! Check out the configuration details in our official API docs: api-docs.deepseek.com/quick_start/ag…
English
@ziv_ravid Would like to see comparisons to Laguna S2.1 on agentic coding 👀
English

Thinking machines releasing Inkling-Small. 276B total parameters with only 12B active (a quarter of the original one) with open source weights. I'm bullish on them. They are one of the best neolab
Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English
Eric Alcaide retweetledi


This *actually* beats DeepSeek v4 Flash in just about everything
I think we have a new 2 Spark daily driver ⚡️⚡️
Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English
@soumithchintala Nice release Soumith ! And congrats on the cadence 🔥 Let's compare it to Laguna S 2.1 on agentic coding 👀
English

Inkling-small. 2 weeks after inkling
Nearly as good as Inkling but 4x smaller.
We're just getting started...🔥
Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English
@LiTianleli Nice one ! Congrats on the release ! How does it compare to Laguna S2.1 in agentic coding ?
English

Two weeks later, as promised, Lil Ink is here! And it outperforms its bigger sibling, Inkling, on many benchmarks at just 1/4 the size.
Inkling-Small sits on the open-weight Pareto frontier, particularly strong in agentic tasks and reasoning. It outperforms strong peers in its class, including DeepSeek V4 Flash on many benchmarks. We hope the community finds it useful and it should be compact enough to run on a DGX Spark.

Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English
@tessybarton Nice one ! Compare to Laguna S2.1 on agentic coding ;)
English

Inkling-Small is here!!

Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English

GLM > Kimi > Deepseek > Qwen > MiniMax > Gemma > Laguna > Nemotron > Nex > MiMo > HY3 > Inkling > GPT-OSS > Ling
My honest opinion having run every single one of these (except inkling which I’ve tried via api)
I would say the top 10 here are going far if they keep publishing
English
@miramurati Great launch Mira ! And congrats on the cadence as well ⚡️
Curious on how it compares to Laguna S2.1 on agentic coding 👀
English

Inkling-Small is comparable to Inkling at a quarter the size. Weights are open, fine-tunable on Tinker today. Look forward to seeing what people make with it.
Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English
@cHHillee Congrats on the release, and the process behind it ! Let's compare it to Laguna S2.1 😉
English

Whereas I felt like it took a village to release inkling, inkling-small felt much more routine 😆 We just took the pipeline used for Inkling, passed in a smaller model, and voila - new model! Inkling small benefited quite a bit vs Inkling from some minor improvements, but there's still so much more left in the tank...
Thinking Machines@thinkymachines
Today, we are releasing Inkling-Small. Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available. thinkingmachines.ai/news/inkling-s… Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English
@thinkymachines Congrats on the release ! How does it compare to Laguna S2.1 on agentic coding ?
English

Today, we are releasing Inkling-Small.
Inkling-Small achieves comparable performance to Inkling at a quarter of its size. It features 276B total parameters, 12B active. We are making the full weights available.
thinkingmachines.ai/news/inkling-s…
Fine-tune it on Tinker today, or chat with it in text, image, and audio on Tinker Playground.
English

@eric_alcaide but this isn't a training issue, is it? The search engine's role is to find reputable sources and then see what they say and report correctly. In the reputable pages it says that seeking black doctors is valid and that seeking white doctors is problematic.
English





@eric_alcaide This isn't the AI's fault. That problem is present in all of the data sources (see its citations). This is just not an AI problem and is the wrong layer to solve it at IMO. The AI did its job perfectly here (reading sources and giving the answer the sources point to)
English



@eric_alcaide Next up is porting this to Darkbloom so we can service Laguna for all OpenRouter users!
English
Laguna XS now has "FAST" mode on Apple machines.
Overnight, we've doubled our previous improvement over the benchmark. For the first time, we are at more than 140 decode TPS, the generally perceived "fast" threshold for users.

Kydo@0xkydo
We just passed 100 tokens per second. Once we have MTP/SD in the testing suite, we should see another massive jump.
English