Sabitlenmiş Tweet

XTTS is still being downloaded almost 5m times every month and 2.1m only on HF.
It is greater than many recent hyped models.
Hope people use it well for that to worth to my burnout that I’m still recovering from.
Coqui has been one of the most successful broke startups
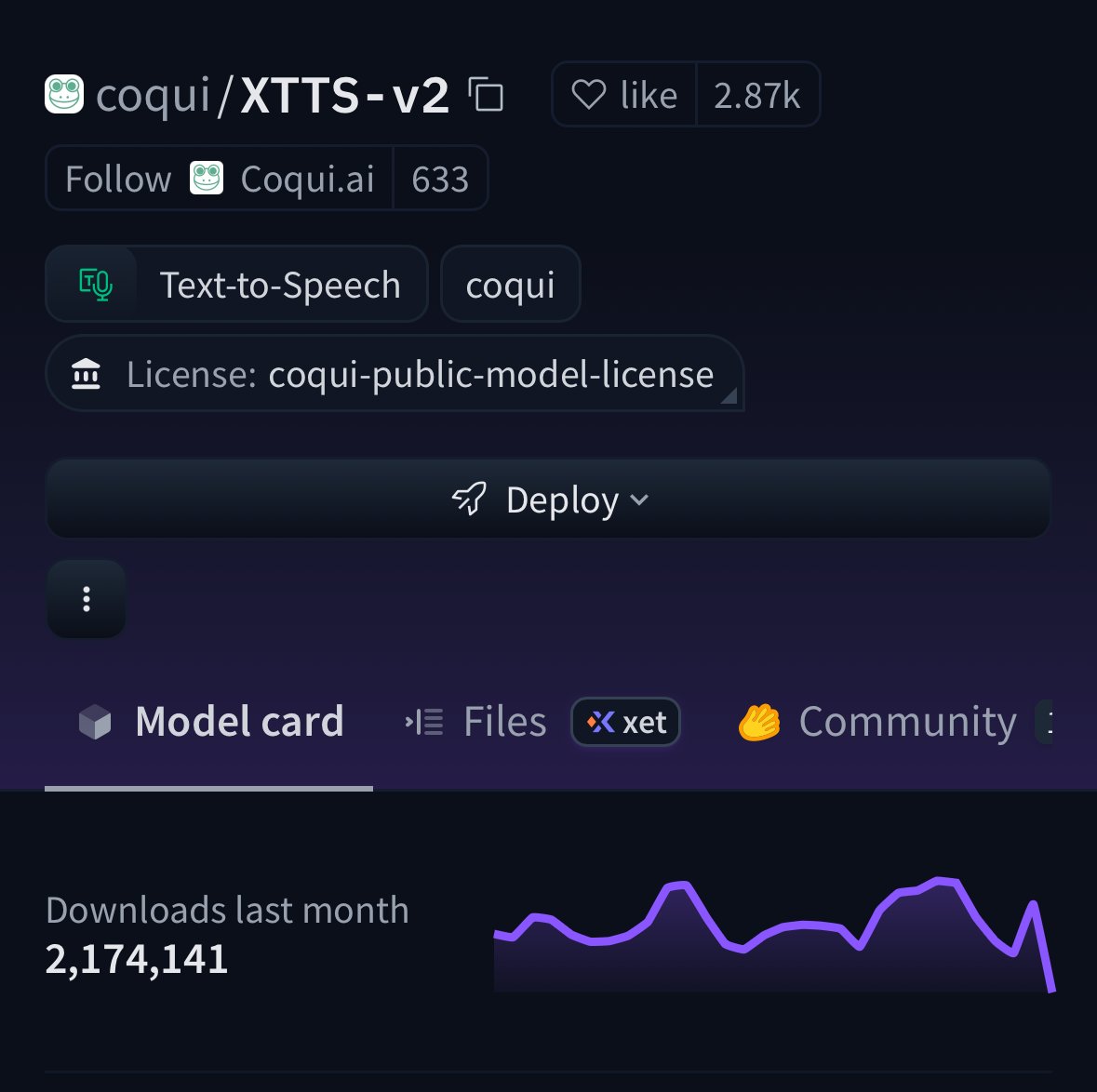
English