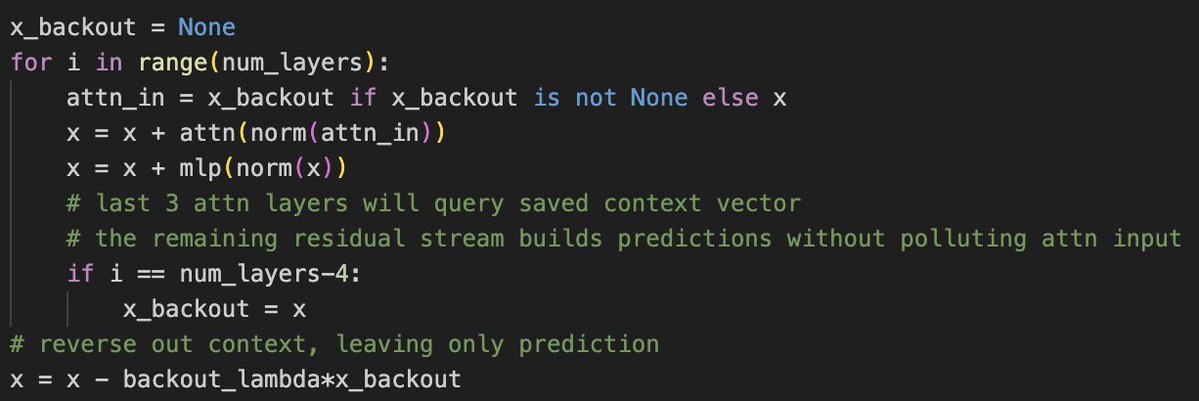
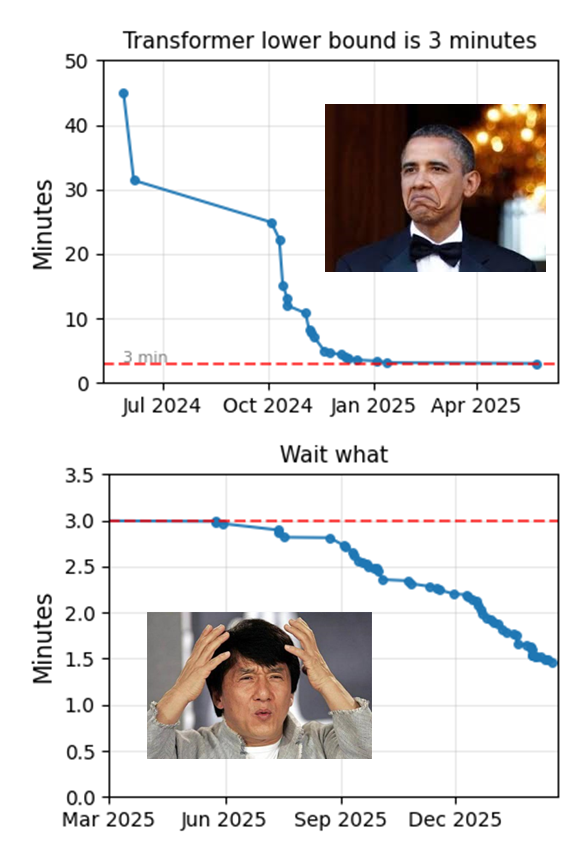
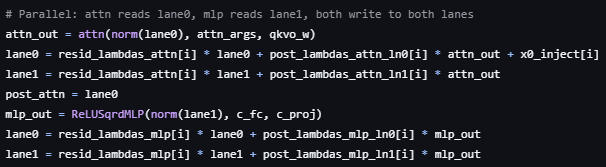
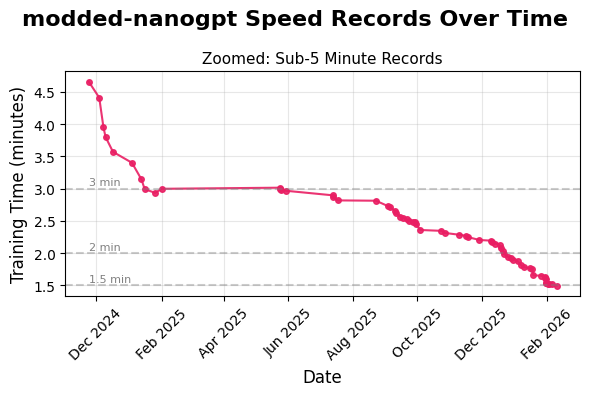
Very cool. My 2 cents for participants: most compute will be spent on undifferentiated hill climbing from people functioning as LLM vessels. Agents can climb hills, but humans are still superior at finding them. What paradigm can you introduce? Sparse circuit discovery and compression during training? Variable embedding sizing? Manifold-ultra-connections? Paired head attn on steroids? Decision tree distillation? The list is endless.
OpenAI@OpenAI
Are you up for a challenge? openai.com/parameter-golf
English