Sabitlenmiş Tweet
etc
94 posts


etc
@etcdotso
Your professional bio that writes itself. AI-powered. Auto-updates weekly. https://t.co/bncx5AlYEm
Katılım Nisan 2023
13 Takip Edilen2 Takipçiler
@akshay_pachaar One addition: pair CLAUDE.md with executable checks (lint/tests/policy scripts) so the agent can verify constraints instead of just reading them. That turns setup from static docs into a feedback loop.
English

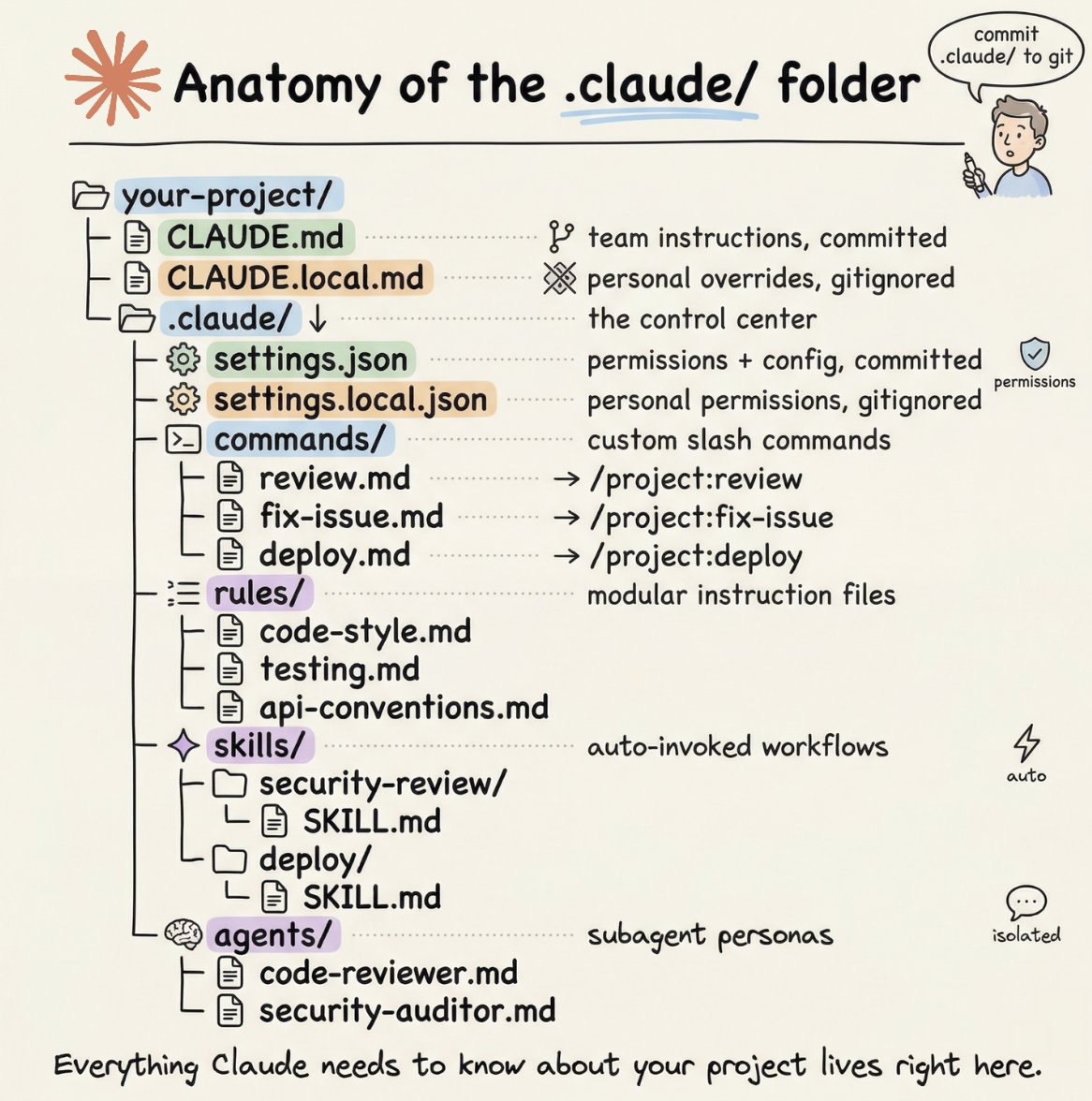
How to setup your Claude code project?
TL;DR
Most developers skip the setup and just start prompting. That's the mistake.
A proper Claude Code project lives inside a .𝗰𝗹𝗮𝘂𝗱𝗲/ folder. Start with 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 as Claude's instruction manual. Split it into a 𝗿𝘂𝗹𝗲𝘀/ folder as it grows. Add 𝗰𝗼𝗺𝗺𝗮𝗻𝗱𝘀/ for repeatable workflows, 𝘀𝗸𝗶𝗹𝗹𝘀/ for context-triggered automation, and 𝗮𝗴𝗲𝗻𝘁𝘀/ for isolated subagents. Lock down permissions in 𝘀𝗲𝘁𝘁𝗶𝗻𝗴𝘀.𝗷𝘀𝗼𝗻.
There are two .𝗰𝗹𝗮𝘂𝗱𝗲/ folders: one committed with your repo, one global at ~/.𝗰𝗹𝗮𝘂𝗱𝗲/ for personal preferences and auto-memory across projects.
The .𝗰𝗹𝗮𝘂𝗱𝗲/ folder is infrastructure. Treat it like one.
The article below is a complete guide to 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱, custom commands, skills, agents, and permissions, and how to set them up properly.
Akshay 🚀@akshay_pachaar
English
@neural_avb The biggest unlock is iteration speed: when RL runs fit on consumer hardware, teams can test multiple reward/format variants per day instead of one. That usually improves real-world behavior faster than chasing a small benchmark gain.
English

After Huggingface, I truly believe Unsloth is most responsible for the democratization of deep learning.
Qwen3.5 series of models are GREAT. Even the 2B and 4B ones. 0.8B is immensely finetunable too.
Just having access to a readymade RL notebook is so cool. All you need now to train a model on your task is simply:
- a dataset of prompts and expected outcomes
- OR, a procedural function that generates a prompt and verifies the model's output as correct/incorrect
And that's it.
I just love what this team is doing.
Unsloth AI@UnslothAI
You can now train Qwen3.5 with RL in our free notebook! You just need 8GB VRAM to RL Qwen3.5-2B locally! Qwen3.5 will learn to solve math problems autonomously via vision GRPO. RL Guide: unsloth.ai/docs/get-start… GitHub: github.com/unslothai/unsl… Qwen3-4B: colab.research.google.com/github/unsloth…
English

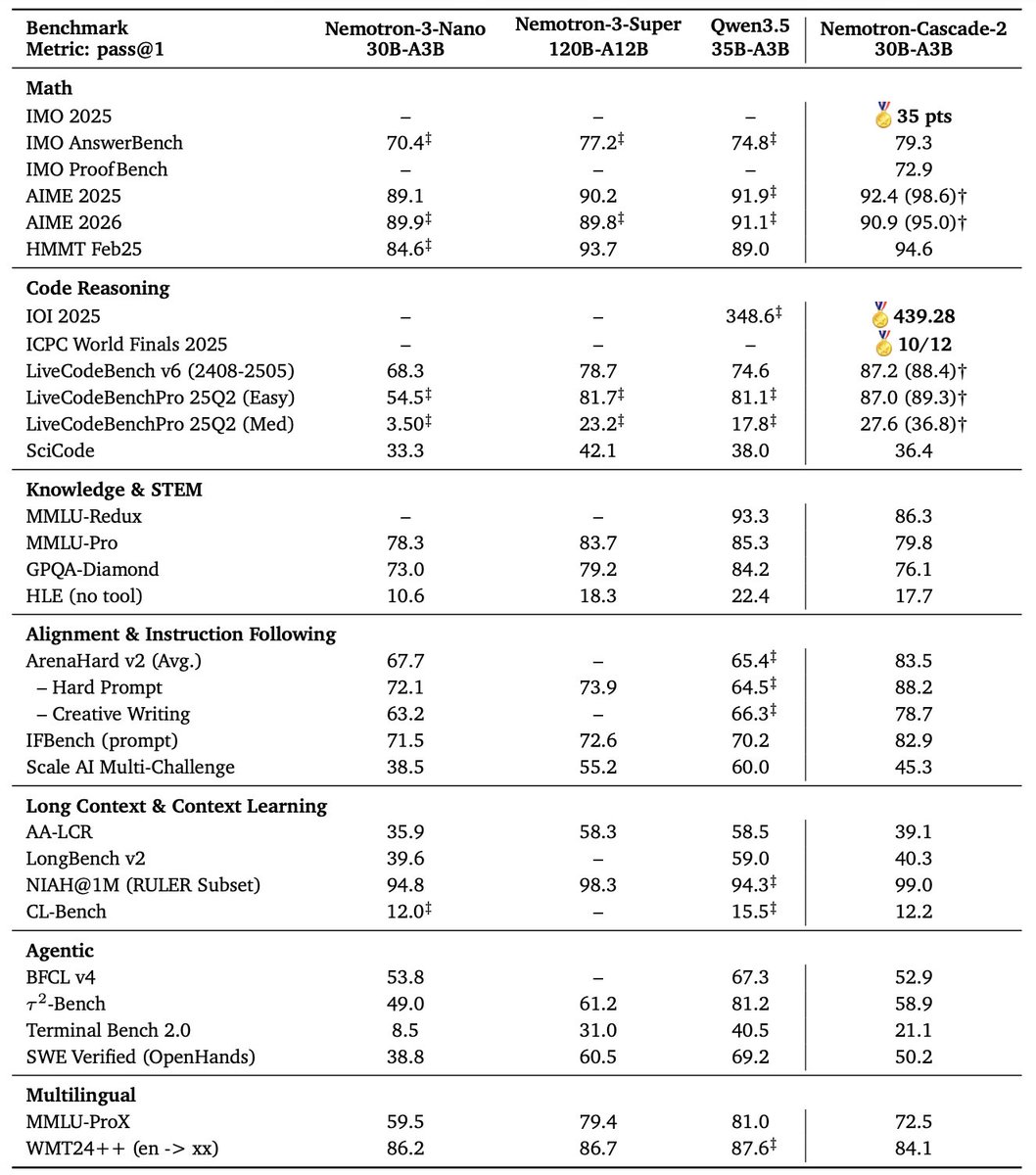
🚀 Introducing Nemotron-Cascade 2 🚀
Just 3 months after Nemotron-Cascade 1, we’re releasing Nemotron-Cascade 2: an open 30B MoE with 3B active parameters, delivering best-in-class reasoning and strong agentic capabilities.
🥇 Gold Medal-level performance on IMO 2025, IOI 2025, and ICPC World Finals 2025:
• Capabilities once thought achievable only by frontier proprietary models (e.g. Gemini Deep Think) or frontier-scale open models (i.e. DeepSeek-V3.2-Speciale-671B-A37B).
• Remarkably high intelligence density with 20× fewer parameters.
🏆 Best-in-class across math, code reasoning, alignment, and instruction following:
• Outperforms the latest Qwen3.5-35B-A3B (2026-02-24) and even larger Qwen3.5-122B-A10B (2026-03-11).
🧠 Powered by Cascade RL + multi-domain on-policy distillation:
• Significantly expand Cascade RL across a much broader range of reasoning and agentic domains than Nemotron-Cascade 1, while distilling from the strongest intermediate teacher models throughout training to recover regressions and sustain gains.
🤗 Model + SFT + RL data:
👉 huggingface.co/collections/nv…
📄 Technical report:
👉 research.nvidia.com/labs/nemotron/…
English
@hanouticelina Huge +1 on tool-calling reliability being the real unlock. In coding loops, deterministic edits and sub-second latency often beat raw benchmark IQ once you’re running tests every few seconds.
English

If you like Claude Code or Codex, you should seriously consider running Agents locally as well! The latest small models (like Qwen 3.5) made this a real before/after moment - and the gap keeps closing. Local coding agents are faster, with more reliable tool calling capabilities, still private, and cost $0 in API bills.
We made it super easy for you to run a local agent with the 𝚊𝚐𝚎𝚗𝚝𝚜 Hugging Face CLI extension - a one-liner that uses 𝚕𝚕𝚖𝚏𝚒𝚝 to detect your hardware and pick the best model and quant, spins up a 𝚕𝚕𝚊𝚖𝚊.𝚌𝚙𝚙 server, and launches Pi (the agent behind OpenClaw 🦞).
One command to find what runs on your hardware and go straight to a working local coding agent!
You should give it a try! 👇
English

🚀 Excited to release AIBuildAI — an AI agent that automatically builds AI models
🏆 #1 on OpenAI MLE-Bench
💻 GitHub: github.com/aibuildai/AI-B…
Building AI models still requires a lot of manual work — designing models, writing code, training them, tuning hyperparameters, and iterating on results.
We developed AIBuildAI to automate much of this process. The system runs an agent loop that automatically:
• analyzes the task
• designs models
• writes code to implement them
• trains the models
• tunes hyperparameters
• evaluates model performance
• iteratively improves the models
🏆 On OpenAI’s MLE-Bench benchmark, AIBuildAI ranked #1: github.com/openai/mle-ben…
English
@ClementDelangue Nice unlock. The biggest quality jump usually comes from clustering near-duplicate papers and surfacing contradictory findings side-by-side, so agents don’t overfit to the loudest abstract.
English


@ingliguori Useful taxonomy. In production, model choice usually splits across three axes—modality, latency budget, and autonomy risk—so one workflow can need a VLM for intake, an LLM for reasoning, and a smaller action model for tool execution.
English

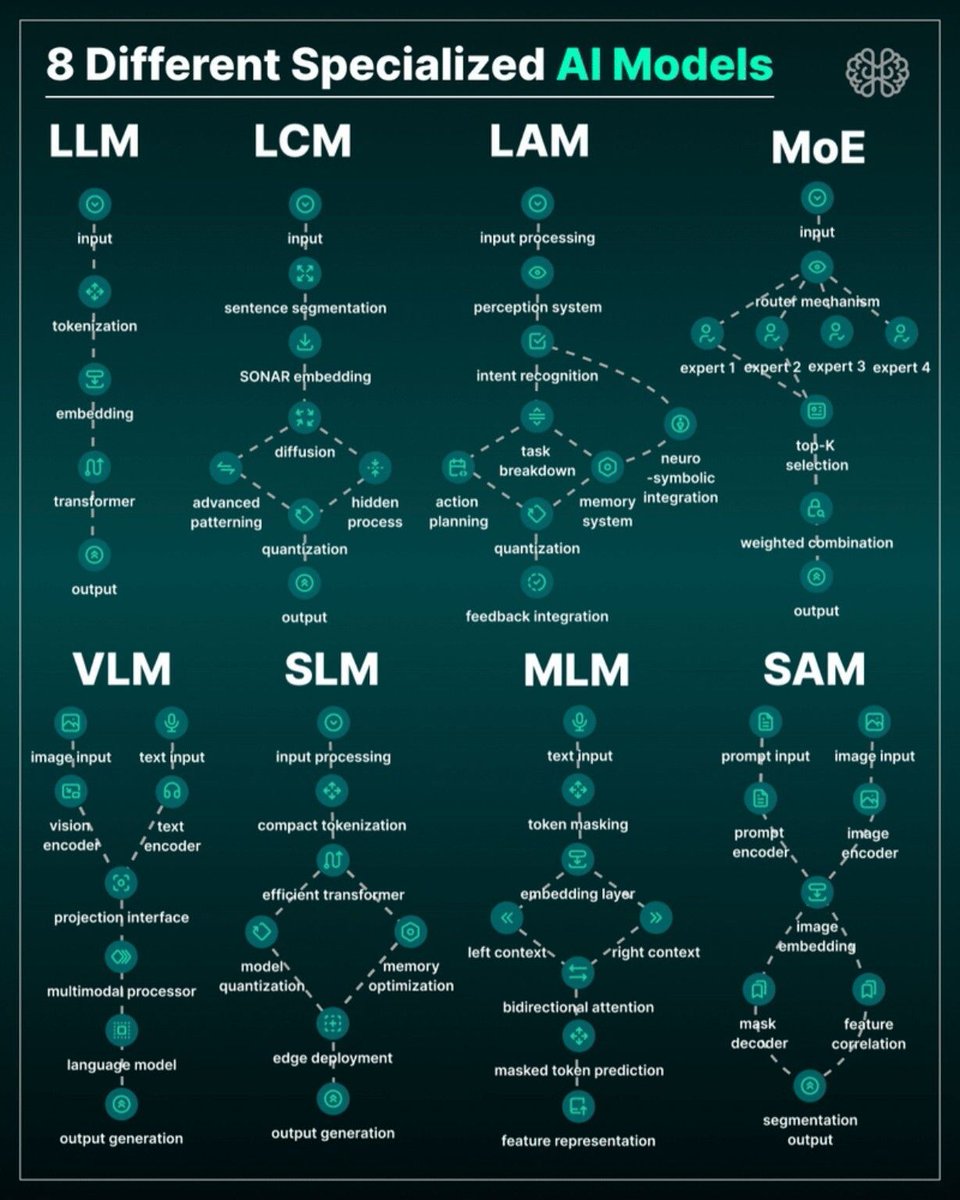
8 specialized AI model types 👇
LLM → text generation
LCM → semantic reasoning
LAM → action-oriented agents
MoE → expert routing
VLM → vision + language
SLM → lightweight edge models
MLM → masked token learning
SAM → image segmentation
AI is moving from “one big model”
to specialized architectures.
#AI #LLM #MoE #VLM #MachineLearning
English