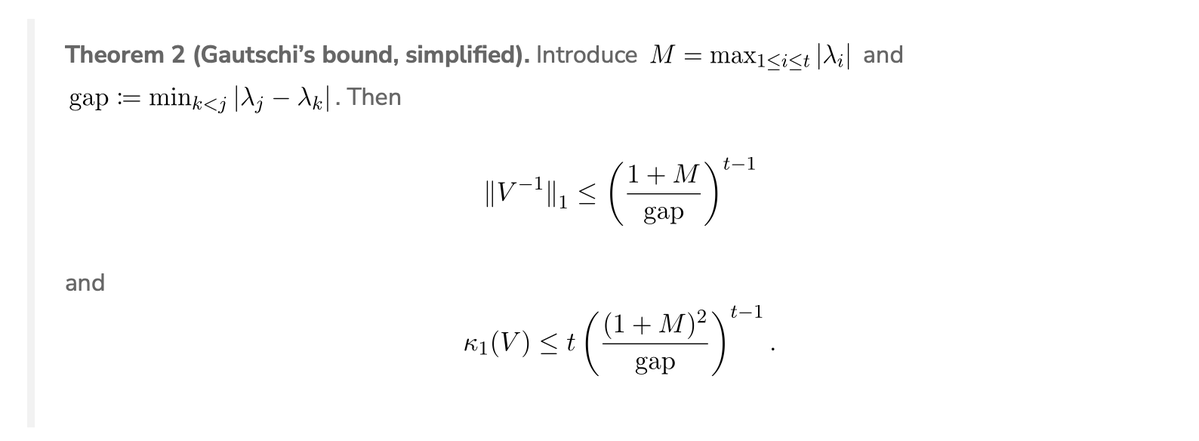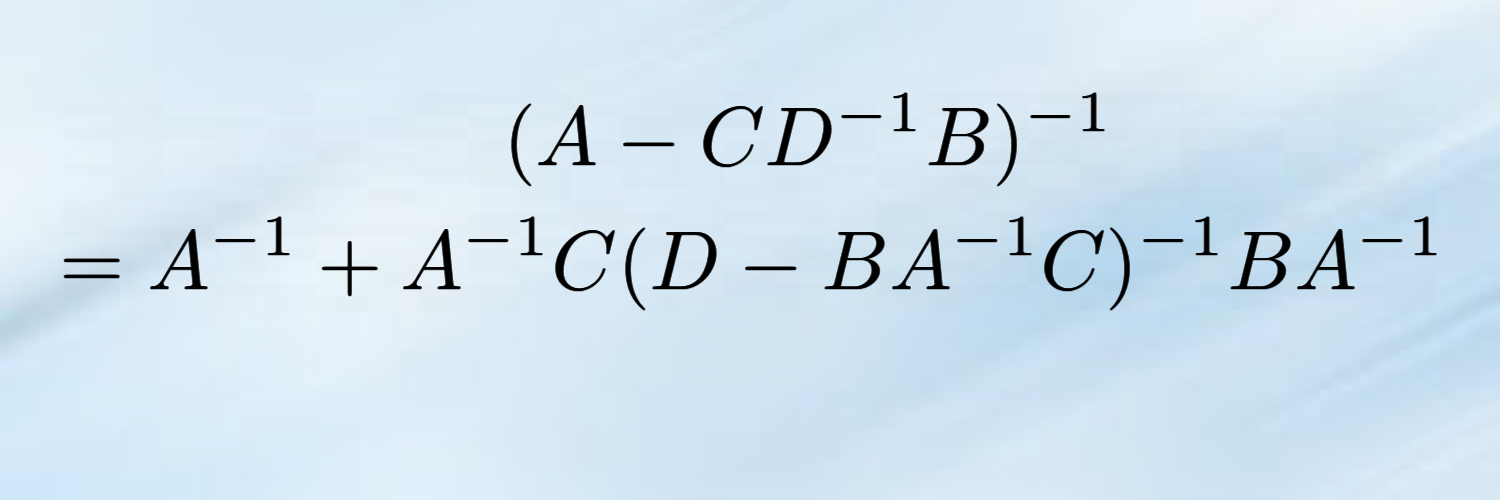
Sabitlenmiş Tweet

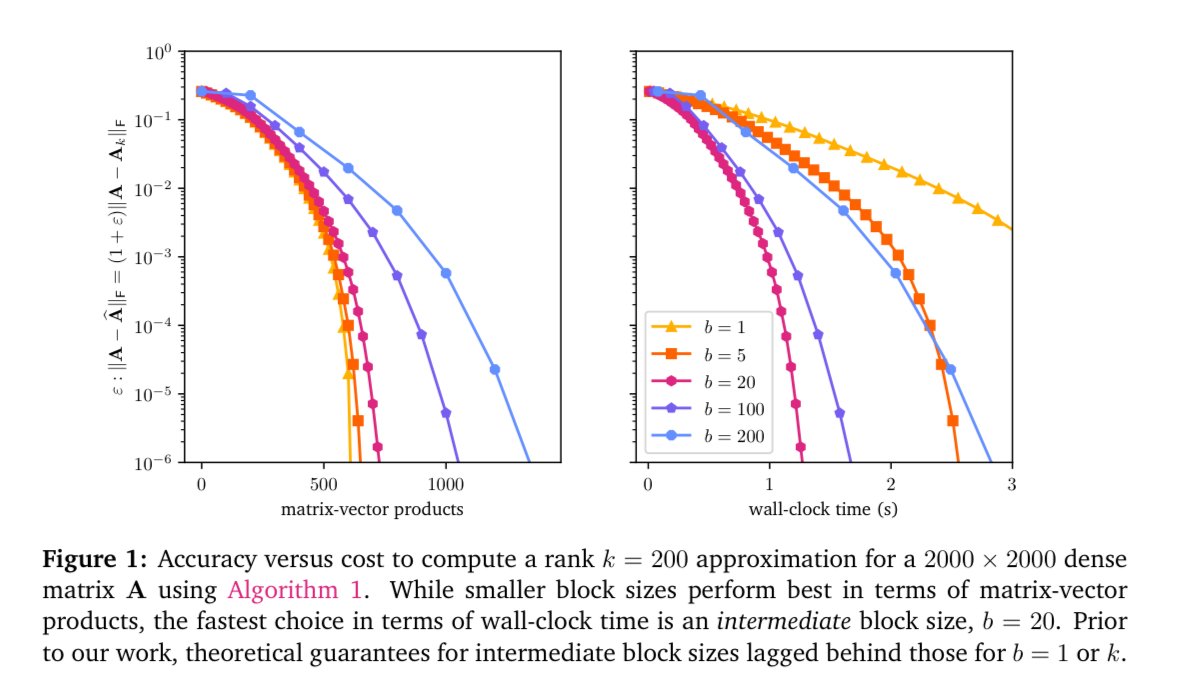
Randomized block Krylov is great at low-rank approximation. But existing analysis gives good results for only large and small block sizes, even though the best block size in practice tends to be in the middle. We resolve this theory-practice gap in arxiv.org/abs/2508.06486
English