
@ZimingLiu11 Feel that we put a lot of efforts to study architecture and optimization algorithms but focus much less on understanding data itself
English
Fusheng Liu
60 posts
@mathlfs
PhD student @ National University of Singapore [email protected]

Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…





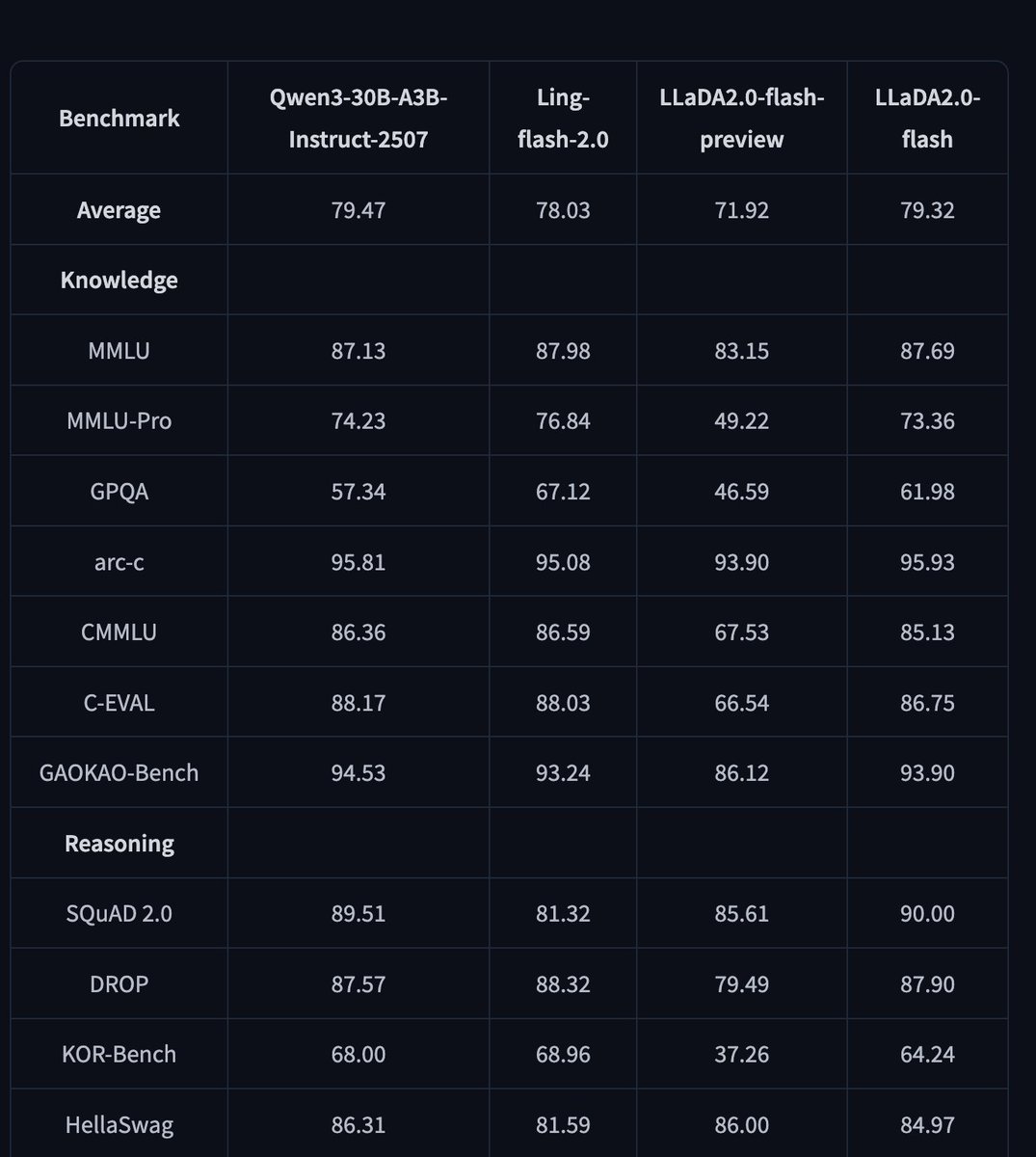
🧬 Introducing LLaDA2.0, for the first time scaled to 100B, as a Discrete Diffusion LLMs (dLLM)! Featuring 16B (mini) and 100B (flash) MoE versions. With 2.1x faster inference than AR models and superior performance in Code, Math, and Agentic tasks, we prove that at scale, Diffusion is not just feasible—it's stronger and faster. 🌊 #AI #LLaDA #Diffusion #OpenSource #dllm













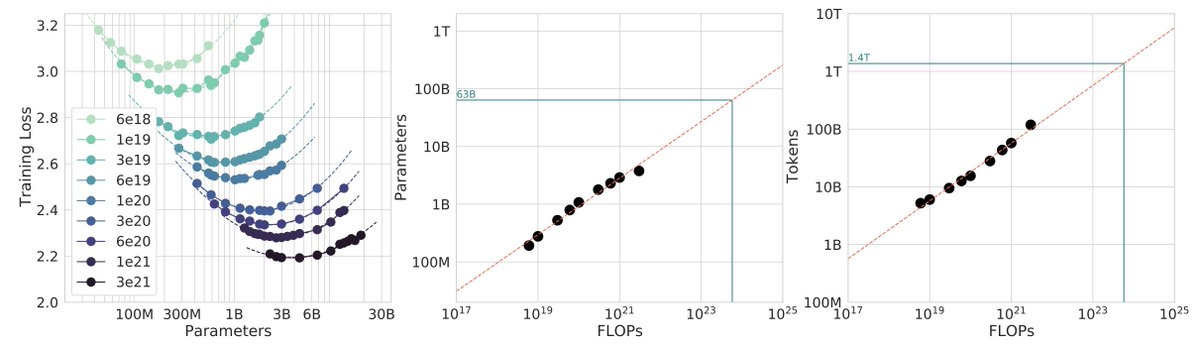
I enjoy getting NanoGPT training speed records. I’m also interested in making my formulation of NanoGPT speedrunning an accessible benchmark on which other people find it easy to try new ideas. To that end, I have tried to keep the code of the current record short, and minimize its installation time. Currently it’s 537 lines of code, and installs+runs in 20 minutes on a fresh 8xH100. That means the cost of a new record attempt is about $8. I’ve enjoyed seeing the records that other people have gotten. @vyasnikhil96 got a new sample-efficiency record using the SOAP optimizer, and I understand he’s currently working on reducing its overhead so that it can potentially compete with Muon on wallclock time in the future. @bozavlado discovered that Muon works better if the QKV weights are orthogonalized separately. And @Grad62304977 improved the record significantly using a wide range of architectural modernizations, including QK-norm. I was surprised to see that QK-norm, which from what I understand was invented to deal with instabilities that appear at large scale, also helps train faster at the small scale. I’ve seen some more interesting new ideas for the speedrun be posted recently, and I’d like to encourage the researchers who came up with those ideas to also be the ones to try them out empirically. I think this makes the benchmark more reliable, if the empirical experiments are distributed across the community, rather than only me doing them. I’m interested in two kinds of new results around this speedrun. First, of course, I’m interested in new records that improve the time to 3.28 val loss. The only rule is that you can’t use external data besides Fineweb10B, and you can’t use pretrained models. Beyond that, everything is fair game. Second, I’m interested in new trainings that match the current record, while being simpler. For example, if it can be shown that we can match the current record using standard AdamW instead of the Muon optimizer, then I think that would be a very interesting result. The log file produced by the current speedrun contains not just the timing and final loss, but also a copy of the code used to produce the run. Therefore, the only thing myself or anyone else needs to verify and reproduce a new record is its log file. Researchers have pointed out that we shouldn’t uncritically trust every result which is obtained at the 124M-parameter scale. I absolutely agree - we shouldn't blindly expect results to scale up. However, I still believe it’s valuable for the community to at least have one stable small-scale benchmark. Once an idea has been clearly proven to work at small scale, it becomes relatively simple to test it a larger scale. I think this is a better situation than the current status quo, where every LM training paper seems to use a different benchmark, making it challenging for the community to evaluate new ideas. The only exception to this evaluation system would be ideas that only work at large scale, so can’t be demonstrated in a small-scale benchmark. These do exist, but I believe they are less common in the recent literature than ideas which are also supposed to work at the 124M-parameter scale, which we should be able to efficiently evaluate using a stable and competitive small-scale benchmark. If the interest in this benchmark stays strong, I am hopeful that some very interesting things can come out of it. Thanks for your interest, Keller

