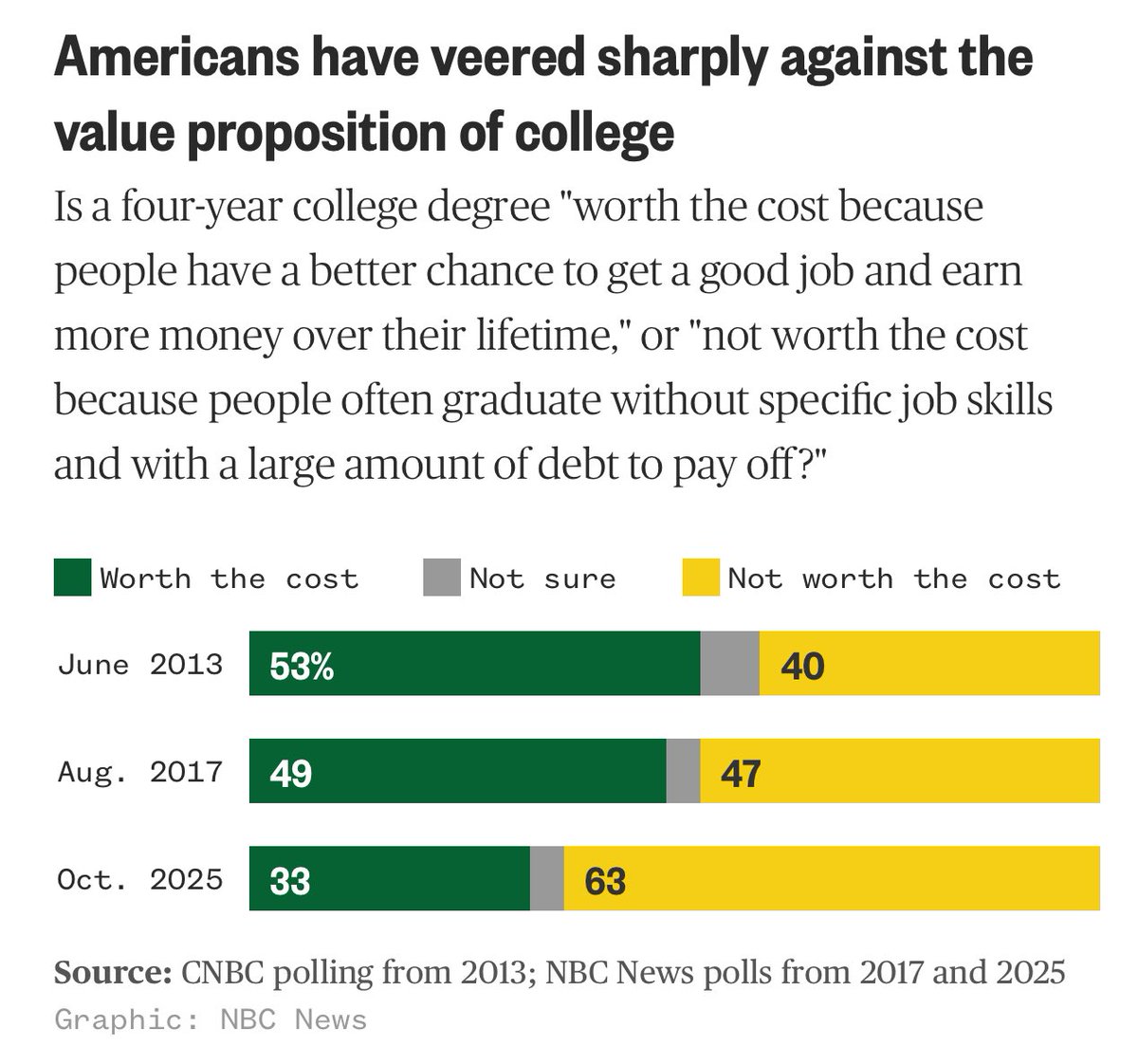
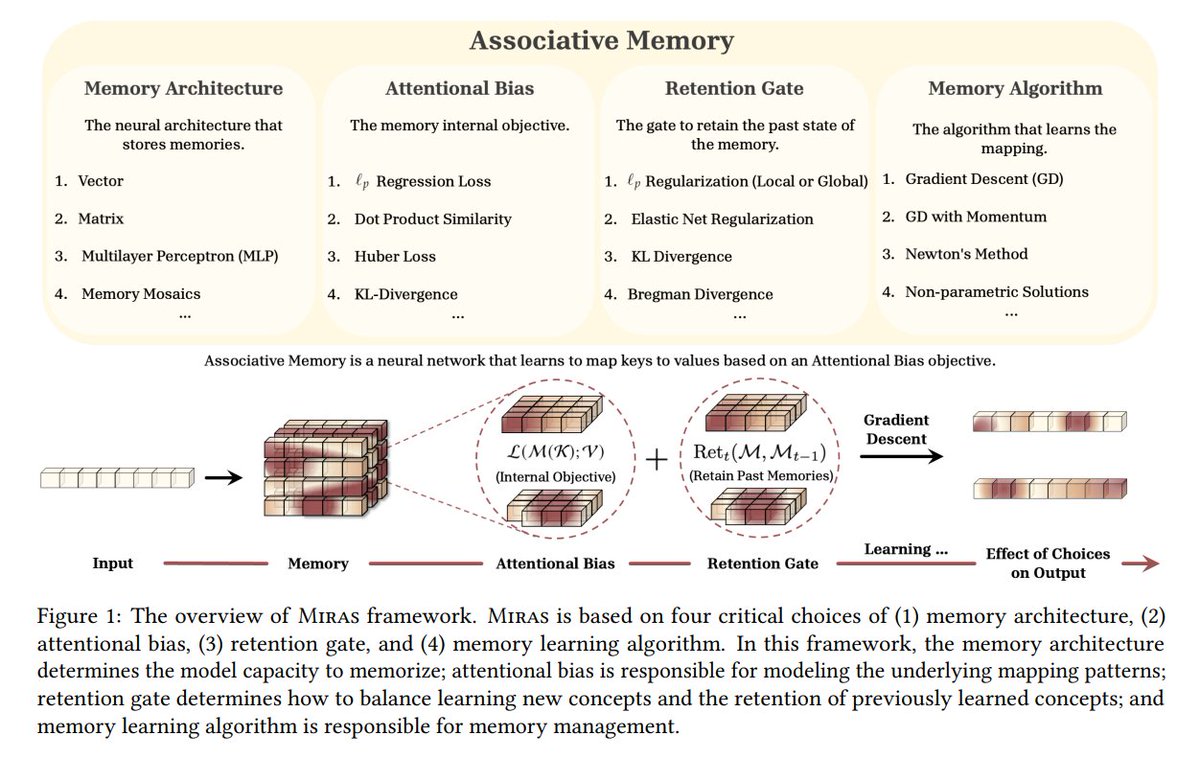
Sabitlenmiş Tweet

My Ph.D. dissertation on "Unsupervised sound separation" is online ideals.illinois.edu/items/127515 😎 If you are interested in self-supervised, multi-modal, efficient and federated learning aspects for sound separation, feel free to take a look 👀
English