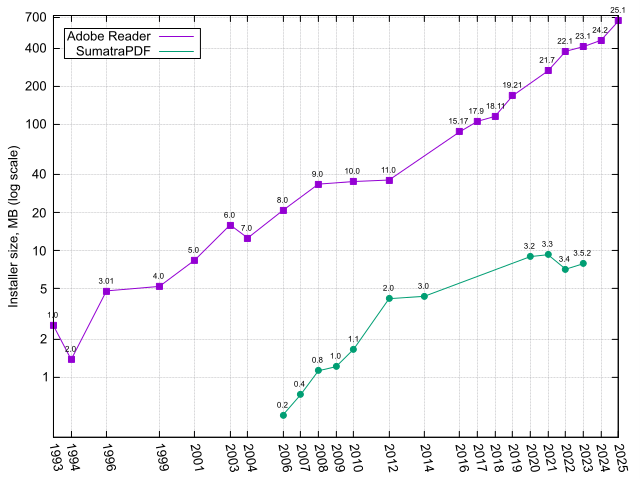
70% of new software engineering papers on arxiv cs:SE are llm related shape-of-code.com/2026/03/22/70-…

English
Evidence-based SE
1.1K posts
@evidenceSE
Evidence-based researcher trying to understand software engineering processes: https://t.co/Li90Xb9gqV






Soon, vol 2
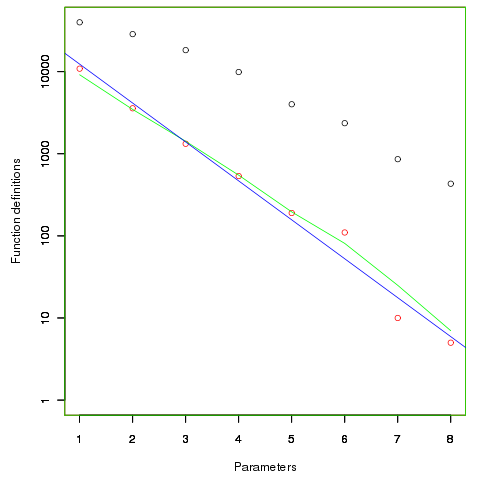
If GPT is to be trusted: "In fact, empirical software engineering research suggests: ~50% of functions take ≤2 parameters ~80–90% take ≤4 Only a small fraction (>1%) take more than 6–7"