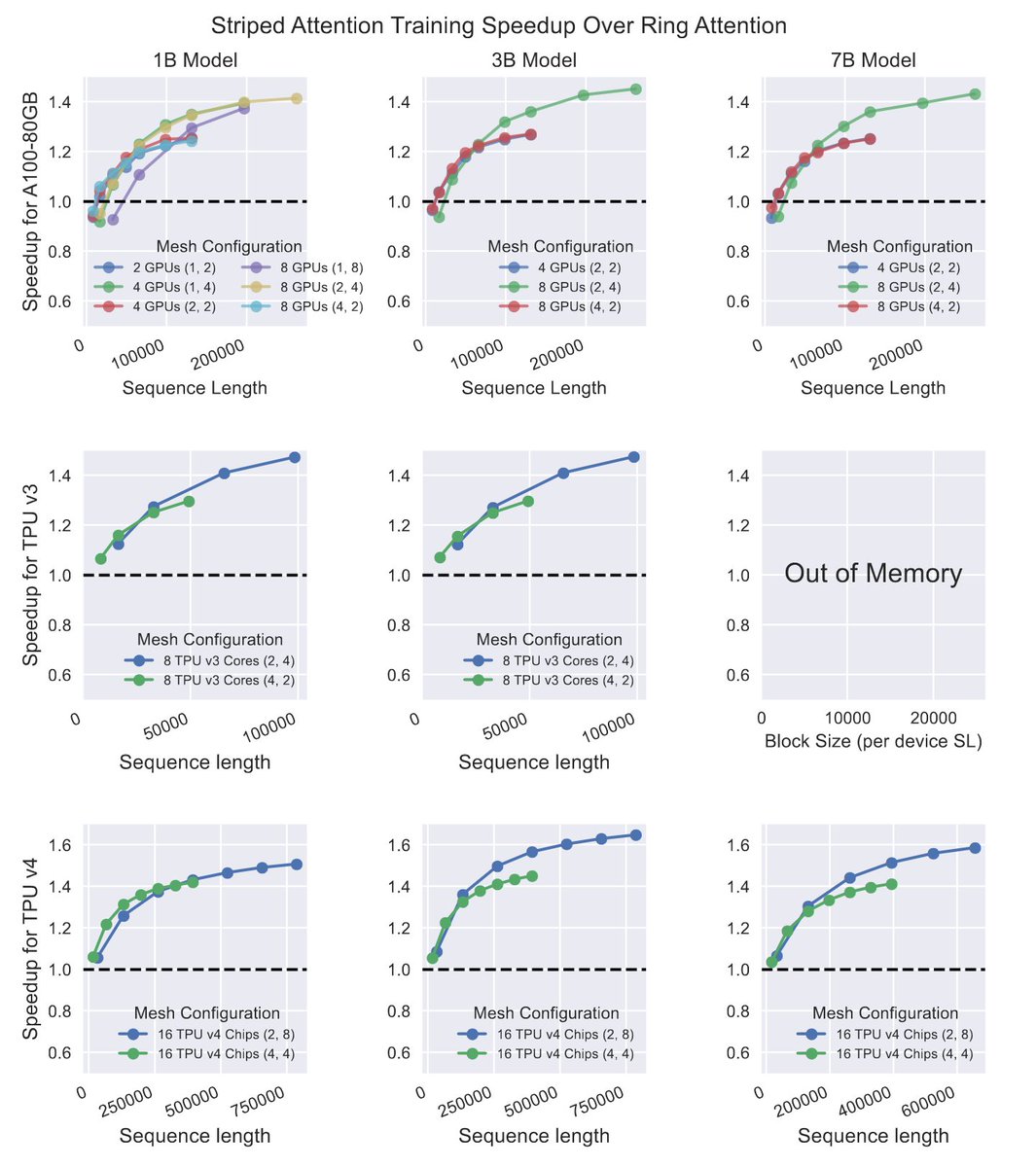
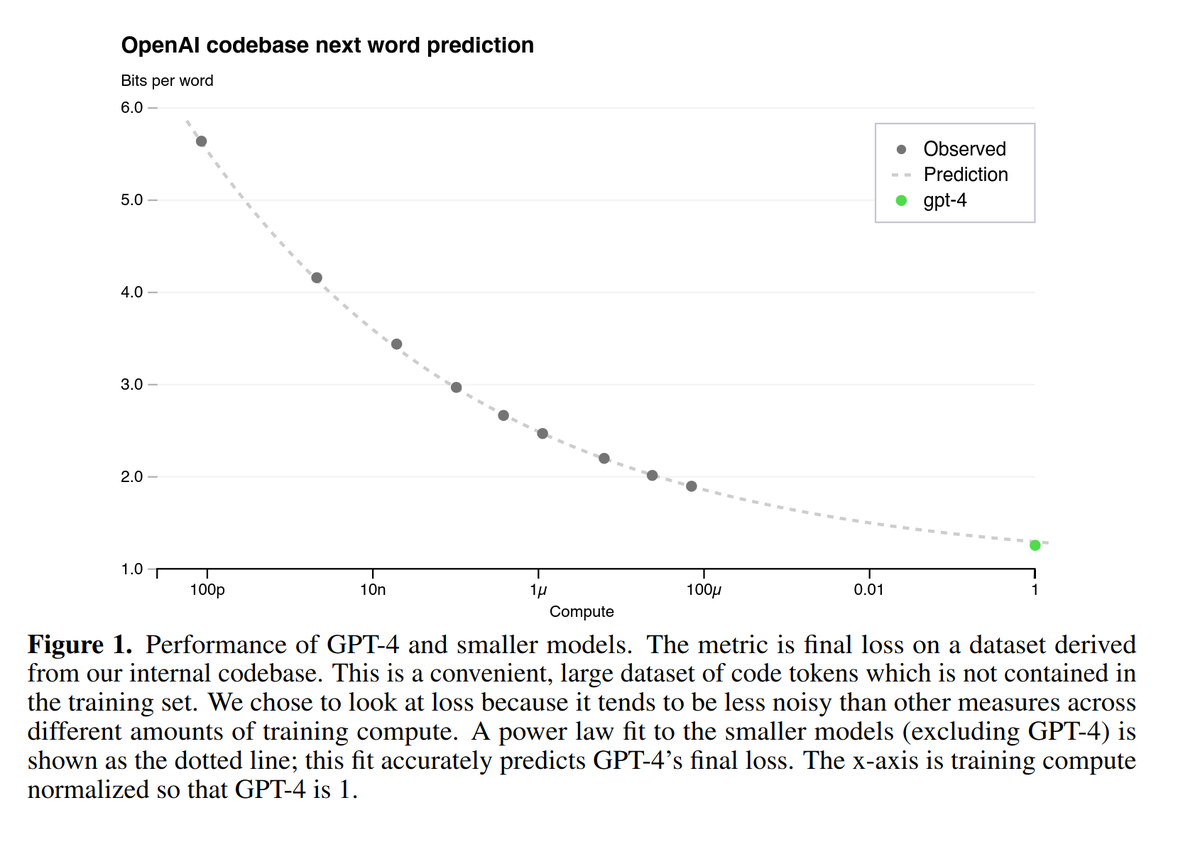
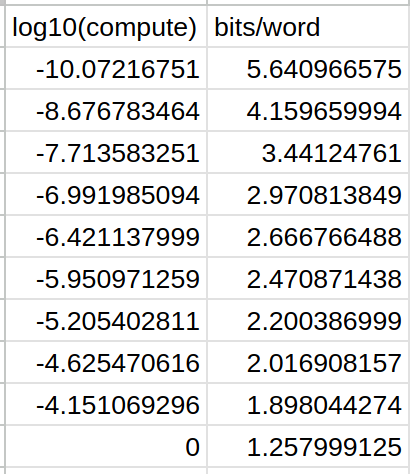
Sabitlenmiş Tweet

If any of you ever manage to find another line of code as beautiful as this one, I want to see it.
inform dreams 📚@inform_dreams
A thing can be seen or unseen. A thing is usually unseen. Carry out examining: now the noun is seen.
English