Felix Dangel retweetledi
Felix Dangel
18 posts

Felix Dangel
@f_dangel
Assistant professor at @Concordia and @Mila_Quebec.
Toronto Katılım Ağustos 2021
83 Takip Edilen220 Takipçiler


Felix Dangel retweetledi

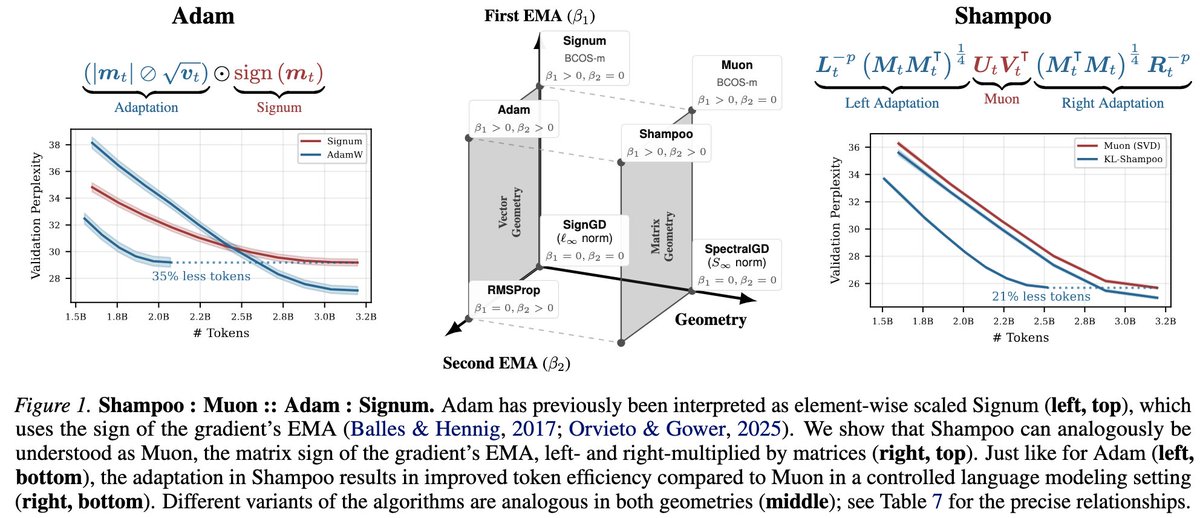
1/14 Is Muon “better” than Shampoo?
We argue that their relationship parallels Adam's relationship with Signum. Analogous to @lukas_balles and Hennig’s (2018) decomposition of Adam into element-wise scaled Signum, we can decompose Shampoo as left- and right-adapted Muon.
English
We found a simple trick to accelerate the computation of PDE operators like the Laplacian via Taylor mode autodiff.
Poster #3401, today @NeurIPS2025's evening session in San Diego.
📜 Paper: openreview.net/pdf?id=XgQVL1u…
🧪 Code: github.com/f-dangel/torch…

English
Want to learn how to train PINNs faster?
Come to our @NeurIPS2025 poster (#2209) today in San Diego (second session)!
📜 Paper: openreview.net/pdf?id=5YMZfuf…
🧪 Code: github.com/andresguzco/rl…
Led by @AndresGuzco.

English
Felix Dangel retweetledi

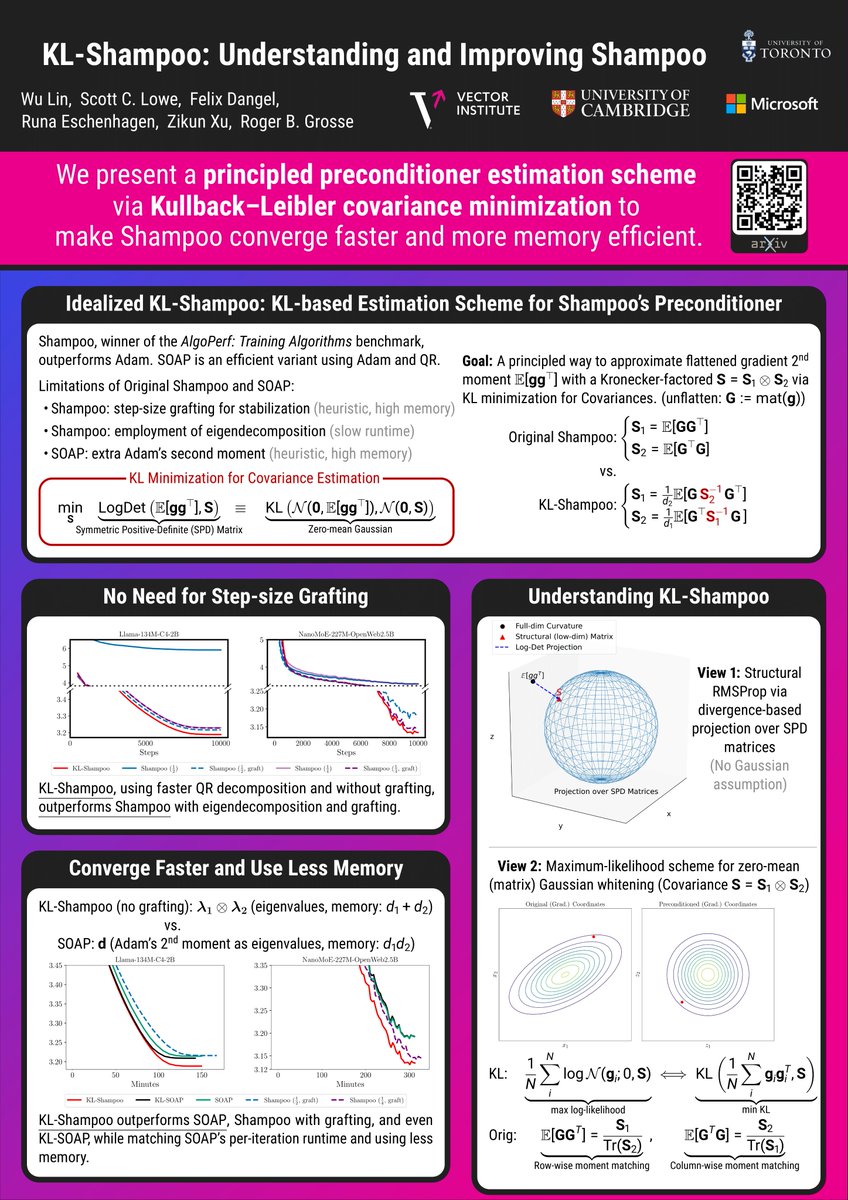
Within an information-geometric framework, we reconnect Shampoo/SOAP with both classical quasi-Newton ideas and Gaussian whitening, and develop practical methods that naturally handle tensor-valued weights in language model pre-training. arxiv.org/abs/2509.03378 opt-ml workshop
English
🚀 [NeurIPS 2025] jet-for-pytorch (github.com/f-dangel/torch…) is live!
From our paper "Collapsing Taylor Mode AD":
🔹 Implements Taylor mode for PyTorch
🔹 Adds collapsing → speedup and memory reduction for PDE operators like the Laplacian
Talk to me #NeurIPS or Tim #EurIPS!
English
🎓 Looking for MSc or PhD opportunities in Machine Learning for Fall 2026?
Join my group at @Concordia and @Mila_Quebec!
🔍 Focus: autodiff, second-order optimization, and Hessian-based methods for LLMs & scientific ML.
📅 Apply by Dec 1: mila.quebec/en/prospective…
English
Felix Dangel retweetledi

I would highly recommend using this library for any research on influence functions.
Implementing scalable IFs (usually ≡ K-FAC) is a massive pain, especially for modern architectures. With curvlinops, getting plots like the below for diffusion models is relatively easy

Runa Eschenhagen@runame_
1/6 Hessian approximations are ubiquitous in deep learning, but working with them can get quite involved. We argue for using a linear operator interface for neural network curvature matrices and implement this in PyTorch in our library curvlinops. arxiv.org/abs/2501.19183/
English
Felix Dangel retweetledi
1/6 Hessian approximations are ubiquitous in deep learning, but working with them can get quite involved.
We argue for using a linear operator interface for neural network curvature matrices and implement this in PyTorch in our library curvlinops.
arxiv.org/abs/2501.19183/

English
KFAC is everywhere—from optimization to influence functions. While the intuition is simple, implementation is tricky.
We (@BalintMucsanyi, @2bys2 ,@runame_) wrote a ground-up intro with code to help you get it right.
📖 arxiv.org/abs/2507.05127
💻 github.com/f-dangel/kfac-…
English
Felix Dangel retweetledi

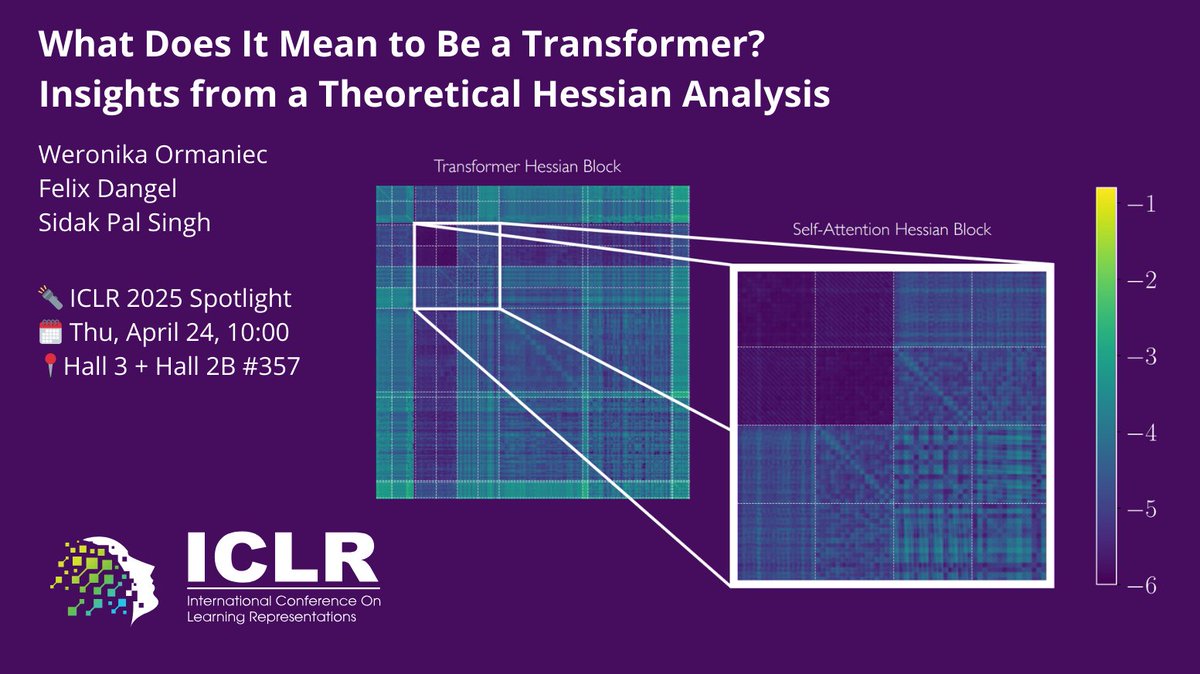
Ever wondered how the loss landscape of Transformers differs from that of other architectures? Or which Transformer components make its loss landscape unique?
With @unregularized & @f_dangel, we explore this via the Hessian in our #ICLR2025 spotlight paper!
Key insights👇 1/8
English
Felix Dangel retweetledi
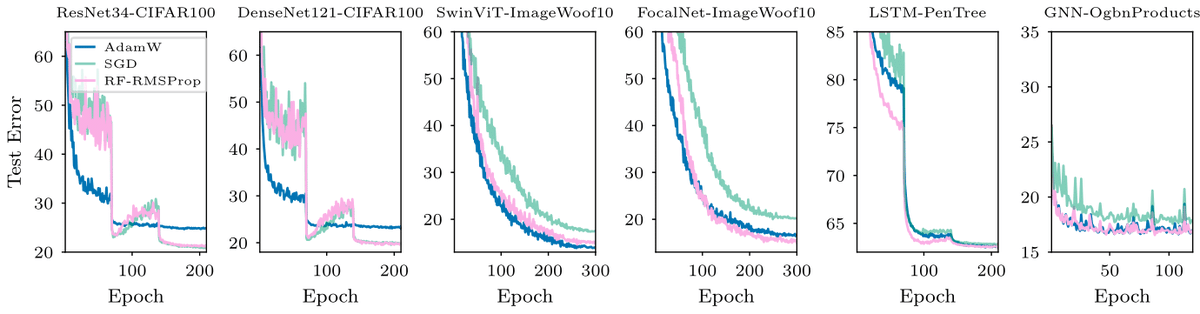
#ICML2024
Can We Remove the Square-Root in Adaptive Methods?
arxiv.org/abs/2402.03496
Root-free (RF) methods are better on CNNs and competitive on Transformers compared to root-based methods (AdamW)
Removing the root makes matrix methods faster: Root-free Shampoo in BFloat16 /1
English
Felix Dangel retweetledi
For the first time, we (with @f_dangel, @runame_, @k_neklyudov @akristiadi7, Richard E. Turner, @AliMakhzani) propose a sparse 2nd-order method for large NN training with BFloat16 and show its advantages over AdamW. also @NeurIPS workshop on Opt for ML arxiv.org/abs/2312.05705 /1

English
Felix Dangel retweetledi

The consensus in deep learning is that many quantities are not invariant under reparametrization. Our #NeurIPS2023 paper shows that they actually are if the implicitly assumed Riemannian metric is taken into account 🧵
arxiv.org/abs/2302.07384
w/ @f_dangel and @PhilippHennig5
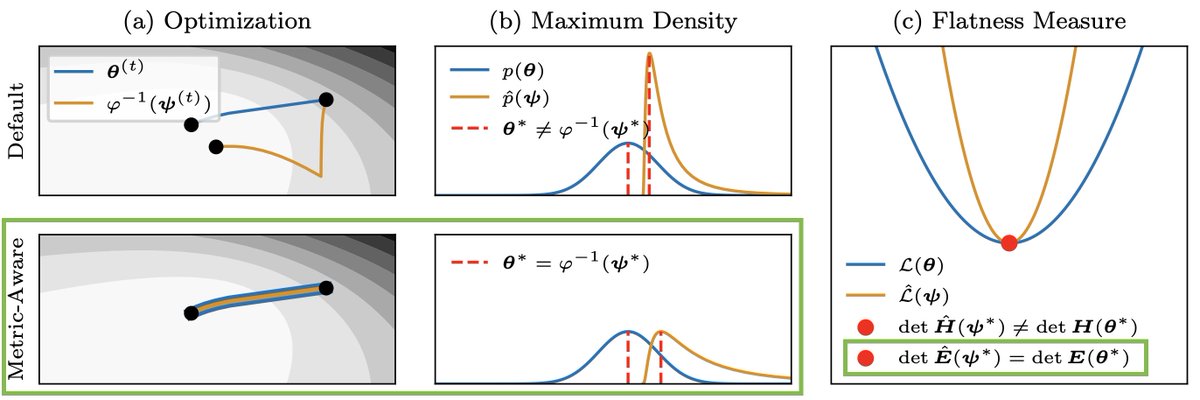
English

@nikosbosse @f_dangel please do share where/how you got it printed!
English

My personal hero at the Ellis Machine Learning Symposium printed his poster on a beach towel so he could keep using it afterwards. Absolute genius. PI material.
English
Which plane would you board?
[#NeurIPS2021] Cockpit: Practical trouble-shooting of DNN training.
Empowered by recent advances in autodiff.
In collaboration with @frankstefansch1 & @PhilippHennig5.

Frank Schneider@frankstefansch1
📣#NeurIPS2021📄 Why are we still debugging neural nets by staring at loss curves? We present Cockpit, a visual debugger for deep learning. Joint work with @f_dangel & @PhilippHennig5 Paper: arxiv.org/abs/2102.06604 Code: github.com/f-dangel/cockp… Video: youtu.be/wQsjgx3zfkQ 🧵
English
Felix Dangel retweetledi

In our #NeurIPS2021 paper (arxiv.org/abs/2106.14806), we introduce laplace-torch for effortless Bayesian deep learning. Despite their simplicity, we find that Laplace approximations are surprisingly competitive with more popular approaches. youtu.be/nMONiYLWWOU

YouTube
English
I'm excited to announce basic support for ResNets & RNNs in BackPACK 1.4 for @PyTorch! 🎉
Find out more in the tutorials:
📈 docs.backpack.pt/en/1.4.0/use_c…
📈 docs.backpack.pt/en/1.4.0/use_c…
Thanks to Tim Schäfer for his work on the library in the past months 🙏.
English