Fabio Salern retweetledi

Nice - my AI startup school talk is now up! Chapters:
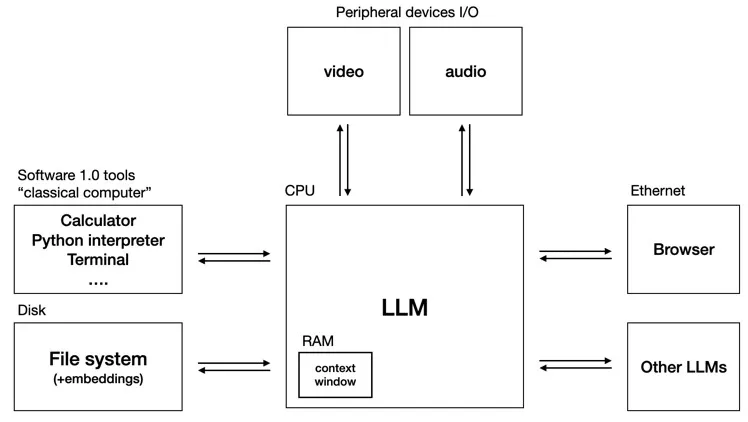
0:00 Imo fair to say that software is changing quite fundamentally again. LLMs are a new kind of computer, and you program them *in English*. Hence I think they are well deserving of a major version upgrade in terms of software.
6:06 LLMs have properties of utilities, of fabs, and of operating systems => New LLM OS, fabbed by labs, and distributed like utilities (for now). Many historical analogies apply - imo we are computing circa ~1960s.
14:39 LLM psychology: LLMs = "people spirits", stochastic simulations of people, where the simulator is an autoregressive Transformer. Since they are trained on human data, they have a kind of emergent psychology, and are simultaneously superhuman in some ways, but also fallible in many others. Given this, how do we productively work with them hand in hand?
Switching gears to opportunities...
18:16 LLMs are "people spirits" => can build partially autonomous products.
29:05 LLMs are programmed in English => make software highly accessible! (yes, vibe coding)
33:36 LLMs are new primary consumer/manipulator of digital information (adding to GUIs/humans and APIs/programs) => Build for agents!
Thank you again for the invite @ycombinator and congrats again on an awesome events! I'll post some links/references in the reply.
Y Combinator@ycombinator
Andrej Karpathy's (@karpathy) keynote yesterday at AI Startup School in San Francisco.
English