@gargighosh Hi! Is there still space available for the ICLR networking event? I’d love to register if spots are still open. Thanks!
English
Sun Fei
101 posts
@fei__sun
Associate Professor @UCAS1978, working on RecSys, NLP, AI safety. My tweets are my own.







Another great @GoogleDeepMind paper. Shows how to speed up LLM agents while cutting cost and keeping answers unchanged. 30% lower total cost and 60% less wasted cost at comparable acceleration. Agents plan step by step, so each call waits for the previous one, which drags latency. Speculative planning fixes that by having a cheap draft agent guess next steps while a stronger agent checks them in parallel. Fixed guess lengths backfire, small guesses barely help, big guesses waste tokens when a check disagrees. Dynamic Speculative Planning learns how far to guess, then stops early to avoid wasted calls. A tiny online predictor learns how many steps will be right using reinforcement learning. 1 knob lets teams bias for speed or cost, either by skewing training or adding a small offset. If a guess is wrong, extra threads stop and execution resumes from the verified step. Across OpenAGI and TravelPlanner, the dynamic policy matches the fastest fixed policy while spending fewer tokens The result is clear, faster responses, lower bills, and 0 loss in task quality.

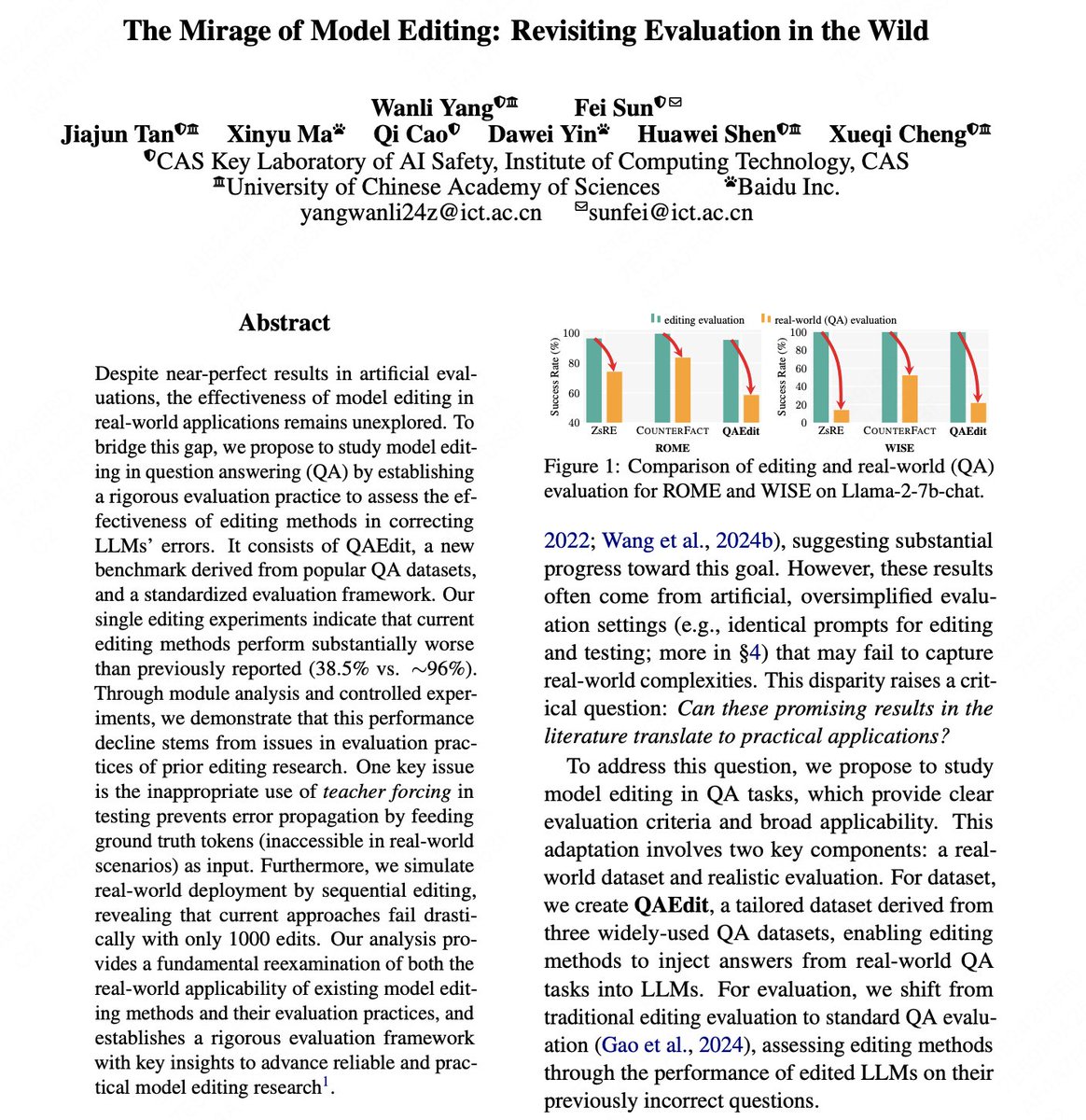
🛑 Stop using teacher forcing to evaluate model editing! Our ACL 2025 poster shows why past evaluations mislead progress & how to test editing in the wild. 📍 July 30, 11:00 AM – come chat! #ModelEditing #LLM #ACL2025NLP

🎉 Excited to share that our work "The Mirage of Model Editing" has been accepted as a main conference paper at #ACL2025! Many thanks to my supervisor @fei__sun, our collaborators, and special thanks to @HuaWenyue31539 for insightful discussions!

🚨 New Blog Drop! 🚀 "Reflection on Knowledge Editing: Charting the Next Steps" is live! 💡 Ever wondered why knowledge editing in LLMs still feels more like a lab experiment than a real-world solution? In this post, we dive deep into where the research is thriving — and where it's falling short. From foundational breakthroughs to the practical roadblocks no one’s talking about, we connect the dots and propose what’s needed to move forward. Join the conversation! #KnowledgeEditing #LLMs #AI #ModelEditing 📌 If you're working on LLMs, model updates, or mechanism interpretability, you don’t want to miss this. 👉 Read the full post: yyzcowtodd.cn/rethinkedit Key insights from our analysis: 0⃣ Current evaluation metrics and benchmarks inadequately assess knowledge updates in LRMs, highlighting the need for more comprehensive evaluation frameworks. 1⃣ Scaling challenges persist, with significant memory and computational constraints limiting the practical application of editing methods for larger or quantized local models. 🎁 Resource Release: To support the research community, we release covariance matrices for Qwen2.5-32B & QwQ-32B models for the current locate-and-edit methods. 2⃣ We outline promising research directions for developing language models that can effectively learn, adapt, and evolve their knowledge base. Huge thanks to the brilliant collaborators who made this deep dive into #ModelEditing possible! @uclanlp @CanyuChen3 @Jiachen_Gu @dsmall2apple1 @ManlingLi_ @VioletNPeng

all u need is vspace😂