Sabitlenmiş Tweet

LLMs go stale daily: facts shift, discoveries land, hallucinations are uncovered. How do you continually keep up with knowledge drift without retraining?
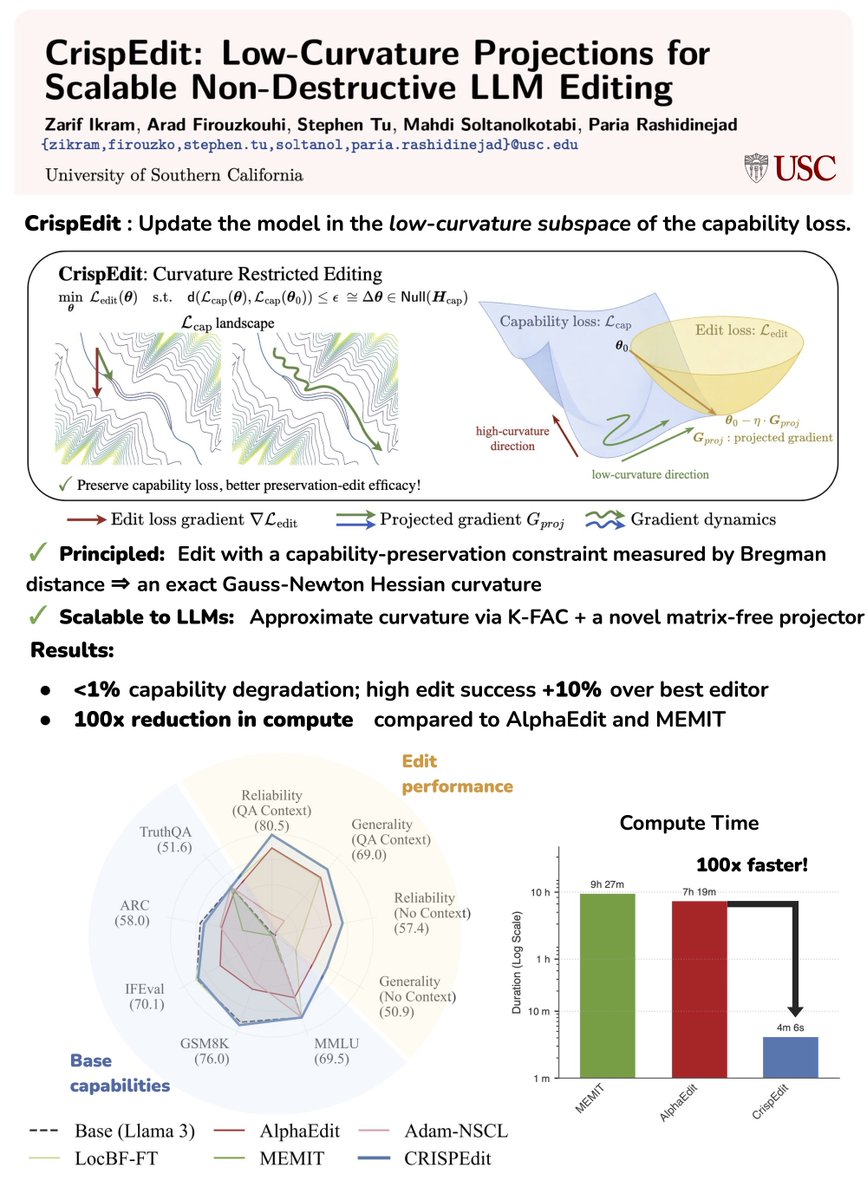
Our new work, CrispEdit, lets you apply 𝘁𝗵𝗼𝘂𝘀𝗮𝗻𝗱𝘀 𝗼𝗳 𝗲𝗱𝗶𝘁𝘀 to billion-parameter LLMs in 𝗷𝘂𝘀𝘁 𝗮 𝗳𝗲𝘄 𝗺𝗶𝗻𝘂𝘁𝗲𝘀 𝗼𝗻 𝗮 𝘀𝗶𝗻𝗴𝗹𝗲 𝗚𝗣𝗨, while keeping the model’s existing capabilities intact. That’s >𝟭𝟬𝟬𝘅 𝗳𝗮𝘀𝘁𝗲𝗿 than popular editors like AlphaEdit and MEMIT.
💡𝗖𝗼𝗿𝗲 𝗶𝗱𝗲𝗮: The landscape of existing capabilities is sharp in a few directions and flat in many others, so we apply edits only in the low-curvature subspace, where updates are “safe”.
✅ This avoids paying for full retraining and mitigates capability degradation and forgetting in existing editors.
𝗥𝗲𝘀𝘂𝗹𝘁𝘀:
• 𝗛𝗶𝗴𝗵 𝗲𝗱𝗶𝘁 𝘀𝘂𝗰𝗰𝗲𝘀𝘀: +10% over best baselines under the real 𝘢𝘶𝘵𝘰𝘳𝘦𝘨𝘳𝘦𝘴𝘴𝘪𝘷𝘦 𝘨𝘦𝘯𝘦𝘳𝘢𝘵𝘪𝘰𝘯 (WILD), not just teacher-forced evaluation.
• 𝗖𝗮𝗽𝗮𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀 𝗶𝗻𝘁𝗮𝗰𝘁: <1% drop on average.
• 𝗙𝗮𝘀𝘁: 3,000 edits on Llama-3-8B in <5 minutes on a single NVIDIA A40.
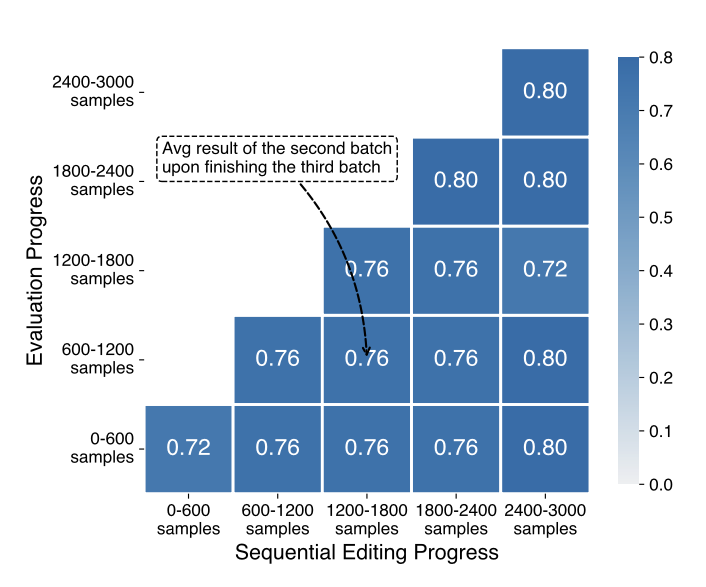
• 𝗦𝗲𝗾𝘂𝗲𝗻𝘁𝗶𝗮𝗹 𝘂𝗽𝗱𝗮𝘁𝗲𝘀: Sequential CrispEdit effectively maintains both the capabilities and previous edits.
📝 arxiv.org/pdf/2602.15823
English