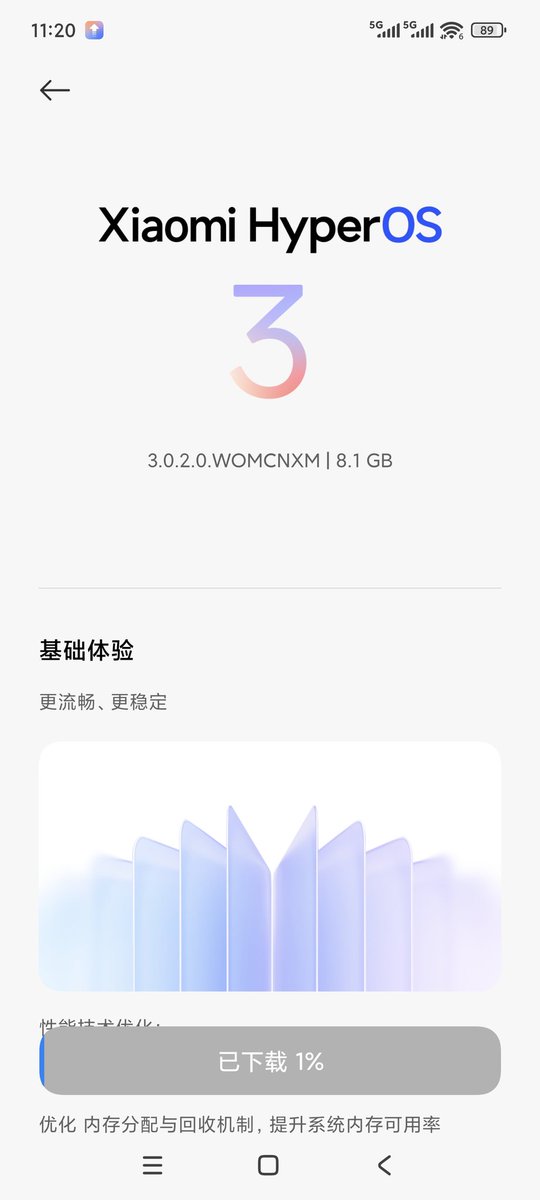
flex
200 posts

flex
@flex_lib
Gentoo Users🔋 Python / TS / Rust 💻 Crypto Builder💰 DevOps💾 3D printing / Circuits🛠️
Katılım Mayıs 2020
313 Takip Edilen151 Takipçiler




干活的话自建bot可能是比较好的做法。又用了一阵,CodexWeb适合快速看到一个点子实现起来是什么样的(代码、甚至是简单的效果)但仅凭其自身,能完成的复杂度有局限性(不容易微调,甚至没法简单rebase)稍大点的功能至少要再和CLI工具做协调,如果很复杂的功能(我在vibe游戏的引擎部分)还要考虑多个模型交叉验证,就不够用了。
中文
最近我比较密集地在用 Codex 的云端版,主要是把一年多以前做的网页小游戏原型拿出来重新打磨。之前因为付费 OpenAI 才注意到它,顺手点进去看了下,发现确实已经能直接在云端开工了。
我最直观的感受是“省事”。不需要自己搭环境,也不需要在本地折腾配置,手机打开网页、选仓库就能开始写代码。做完改动以后还能直接创建 PR,然后让 Codex 再帮你做一轮 review。对一些偏前端的项目,如果本身还接了 Cloudflare 之类的预览链路,确实可以把开发、调试、review 这条流程在云端(甚至手机上)串起来,效率很高。
环境适配方面,我的观察是 JS 应用的适配做得挺好;Python 相对弱一些。整体的工作流整合得很顺,但我也能感觉到云端环境的上限目前还不是特别高,这会让复杂项目更容易碰到边界,不过这类问题理论上也属于可以逐步补齐的那种。
模型效果本身我觉得是不错的。虽然我最近没有做系统的横向对比,但在“快速迭代”和“细节打磨”上,它给的帮助是实打实的。另一个我很喜欢的点是它在 GitHub 上 review PR 的速度很快,质量也可以;但对应的代价是 credits 消耗得非常快,甚至比让它实际写代码还快。
缺点也比较明确。它确实有用,第一次会很认真、也很完善地把任务拆成一条条可执行的 task 列出来;但不像本地 CLI 那样你还能在 plan 上反复微调,因为从你说完第一句话开始,它往往就会倾向于直接进入“按指令执行”的状态,后续追问也被它当成继续执行的信号。对我来说,这和我平时把这些工具当“通用的智能软件”来用的习惯不太一致,因为我很多时候希望先讨论、拆解、权衡,而这个Plan模式的行为让讨论变得复杂。另一个是云端对“根据 code review 建议去逐条修改”的支持感受一般(可能也和 GitHub 的 UI 有关),另外像 rebase 这类操作在云端场景下也不算顺手,所以复杂情况下可能还是需要配合本地 CLI 才会更稳。
总体来说,如果目标是快速做原型,或者在云端维护一些不太重的项目,Codex 云端版是个不错的选择。它的限制也比较明显,但只要提前了解边界、调整使用方式,仍然能覆盖很多实际工作;而如果你本来就有自建远程 agent 的能力,那种方式在完整性和可控性上目前依然更强。
中文

直接开宗明义,请不要升级 Prisma V7 With Rust Free
prisma.io/blog/prisma-or…
官方宣称性能能有 3x 提升。但是实则不然。我们今天在真实环境上线后发现了极大的 performance regression
我们最开始怀疑是 driver 有问题,但是进过我们线上实时 Profiler 的采样和验证后,我们更倾向于目前的 WASM Query Compiler 存在很大的问题
这一点在上游也得到的了部分验证,不仅是 PostgreSQL 的场景出现 performance regression. FYI github.com/prisma/prisma/…
所以,珍爱生命,远离 Prisma
中文

哈哈哈哈,我的小孩不喜欢编程
如果假设一下,我会这样培养
1. 高中之前不要学编程,学了也不知道有啥用
2. 好好读书,把数学的素养和直觉培养出来
3. 学习画画,画画是锻炼想象力和观察力的好方法
4. 多去玩,编程的很多策略和鬼点子来源于生活
5. 长大以后,先找到一个感兴趣的目标,然后才开始编程,编程的天花板是数学基础、想象力和好奇心,而不是刷题
来,吃哈密瓜

asdw f@f_asdw
@manateelazycat 大佬,可不可以这样,假设你孩子想学编程,你打算如何培养?
中文

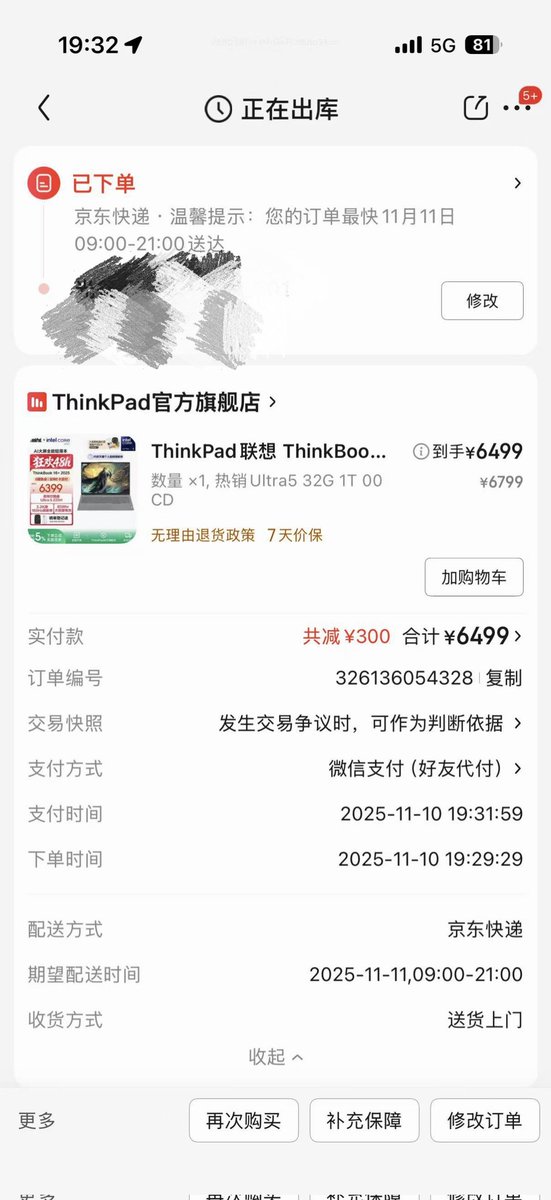
买了一台 ThinkBook 16+ 的机器,公司买6499多,个人买估计国补下来5699
买这个机器的理由:
1. Intel 集显省电,不折腾显卡驱动
2.15代 225 性能比我Dell G16 13900HK 性能还要强
3.外型比ThinkPad要帅一点,屏幕也很大
4.双内存条DDR5 5600, 公司库存的内存加上去,整个128GB内存,哈哈哈哈
公司有大佬用的这台机器,我就不担心Linux兼容性问题了,续航在Linux下一般般,2个多小时
Andy Stewart@manateelazycat
这台dell g16应该是硬件故障了,经常kernel panic,家里AMD同样内核没挂 我还是废电脑,传说LG gram Pro不错,有用过的推油吗? 键盘手感怎么样?适合长时间写代码吗?
中文

当年折腾板子的照片
每天开着车,拉着几台微服,带着两个小米路由器,一到供应商那里就开始疯狂测试,不知道的人以为我在用小米路由器给微服做空中按摩
每天都看无数遍dmsg日志,我现在都背得SATA硬盘各种状态下内核的日志序列 😂


中文


要分开看问题,退出个人角度看问题就能明白。
1. 社会层面:越发达的欧美越适合远程,因为竞争力不是效率,而是创意。反之中国这种卷王的环境,一个公司大量远程等于自杀,因为没有啥架构设计和商业模式可以对抗卷,唯有效率
2. 软件工程:越平台倾向的商业模式越需要现场,因为工程量太大,衔接地方太多,远程沟通成本太高,因为没有足够的架构师和项目经理去干传话筒的事情。反之,如果独立开发者,就是一个App自己就可以干,人多反而没用。想象一下,远程盖高楼花要谢,10人搭帐篷没必要
3. 性格方面:有些人天生独立性强,喜欢安静的,自己干完活很自由,还不孤独的,这种人适合远程。但是大多数人,不一起工作就会工作和生活边界就会模糊,缺乏安全感和目标,这些人都不适合远程,越干越郁闷
所以,开发的同学不要看DHH鼓吹远程办公就盲目相信,很对工作确实不适合远程。
而且DHH是有屁股的,你们远程办公越多,他basecamp的生意不是越好吗?至于远程办公有没有效果,那不是铲子要考虑的问题。
SkyWT@skywt2003
坐班就是工业时代遗留的产物。 在办公室里上班,就像在教室里才能学习一样,是一种毫无意义的社会偏见。 更离奇的是,我的合作方都和我不是一个 base 地,开会也是飞书会议,沟通也大多是在文档里的异步沟通。 搞不懂我此时此刻「在这个特定地点」工作的意义在哪。
中文