Sabitlenmiş Tweet
foufou
4.5K posts


foufou retweetledi

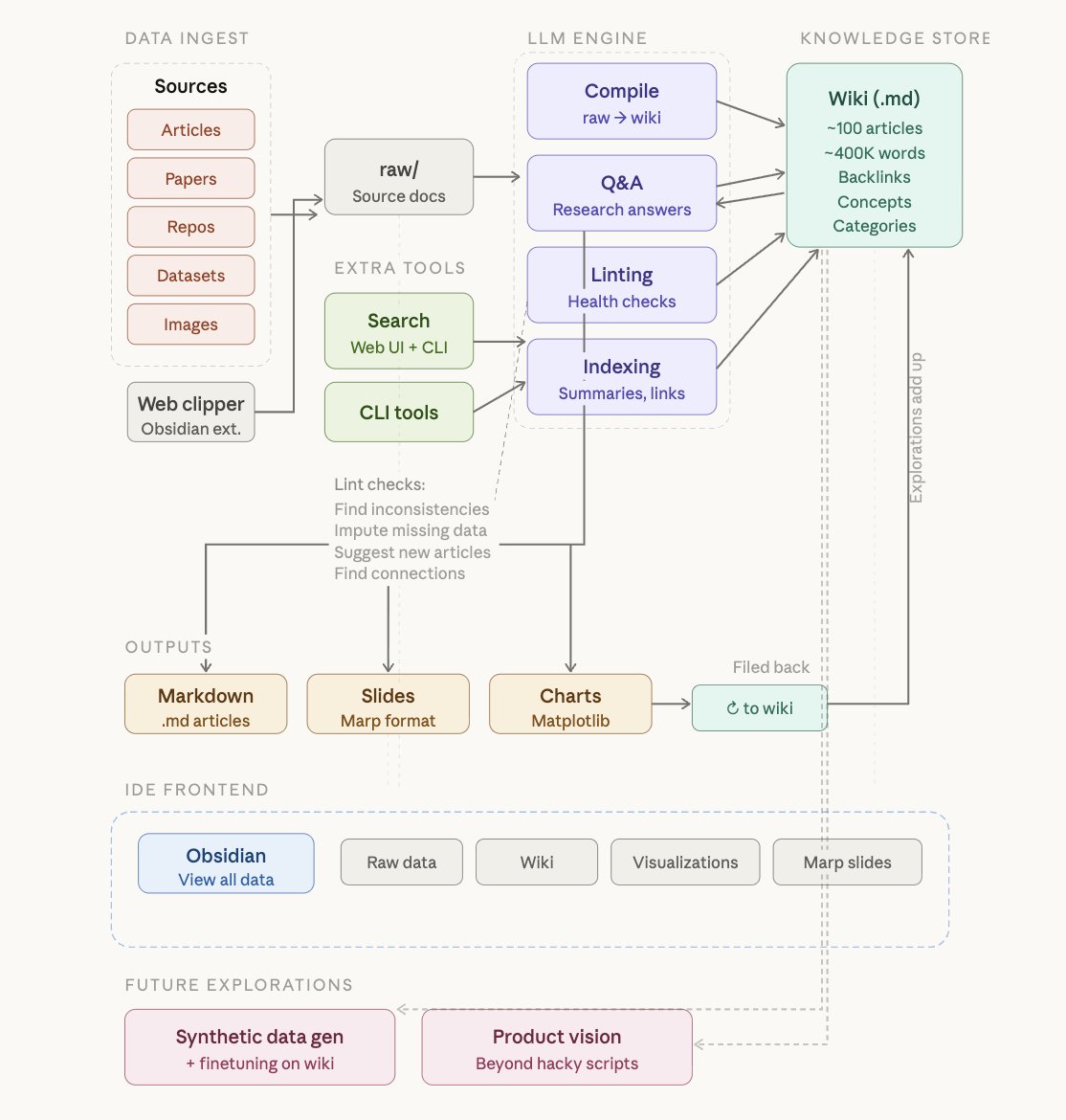
trying to use topological data analysis to map the shape of my x bookmarks through mapper + embedding extraction and generated 3 views:
- density: where attention keeps gravitating
- pca: the dominant axes of variation
- centroid: center vs edge (typical -> outlier)
English
foufou retweetledi

所以我说大部分ai trading的产品方向走错了,走的是跟量化基金竞争那条路。
我做交易所和投资这么多年,我对与交易底层的几个悖论太了解了:1. ai 幻觉和自觉永远无法解决。2. 无法预知,观测ai的决策和执行流程,没有人会把大钱交给黑盒。3. 不管是人类策略还是agent策略,收益和规模相悖,拥挤交易势必影响收益有效性。4. 跟单agent 和买彩票没什么区别。
创始人自己也就拿个几百美金在那儿跑他们所谓的策略。
为什么大家还是走这条路:1. 本质上prompt loop 这种架构是最简单的。2. 找幸存者晒收益率是很好的噱头。3. 再简单的就是直接复用openclaw开源架构。
@MojoAI_HQ 我也在做这个赛道,我现在还没有办法说太多。不过核心目标是优化散户的交易流程,让拍板的多巴胺归用户,让可被替代的工作交给AI。可以说是一个更简单的,可以轻松实现用户复杂组合监控,分析,规则逻辑的交易所。为了解决上述的悖论,我们花了半年自研了agent架构,花了很多时间打磨UI,UX。
虽然我们也是agent,但产品本质上是给人用的,不是给ai用的。
很高兴的是下个月就要开始内测了。也欢迎 @off_thetarget 来试用,看看我们的产品是不是也是伪命题。
pepper 花椒@off_thetarget
已经不止有多个项目找我测一测他们的AI trading架构了 我就简单说几点吧 1. 拿长期实盘出来,短期妖币这种没有 max dd 的不代表什么,幸存者偏差而已。随便挑一个已经归零的币倒着回测,曲线一样漂亮 2. 如果 Sharpe ratio > 5,基本上可以确定是过拟合、look-ahead bias 或者数据泄漏。Medallion 常年也就 2-3,你一个人在家跑出 7,自己心里要有b数 3. 你拿一段 crypto bull market 的数据去测,和你拿一段大类市场的数据回测是不一样的,完全的 overfitting,基本我不看。最起码 2018、2022 两轮熊市能走通,再跑一轮 walk-forward,才算一个策略 4. 手续费、滑点、funding rate 都得建进去。Binance 的 maker/taker、VIP 档位、BNB 折扣一层层算下来,模型不准的话 backtest 和实盘能差出一倍年化,这是常态 5. 策略容量比收益率更值得看。10 万刀跑得动,不代表 100 万刀还能跑。小币深度就那么点,你一进场自己就把自己的信号打掉,backtest 里完全 reflect 不出来 6. 确实 crypto quant 没那么卷,但套利机会一直在被蚕食——funding arb、现货期货 basis、跨所价差,基本已经被做市商和 HFT 吃干净了。高频做不了,纯因子也没空间,剩下能做的只有趋势和 mean reversion 这两条老路 7. Alpha 有半衰期。策略上线三个月还能跑,算及格;半年还在,算不错;一年还有,大概率是运气好或者你的规模还没到引起注意的量级。别把一次 bull run 的红利当永续 alpha,你还没有那么牛逼 8. Grid search 出来的"最优参数"99% 是过拟合。真正稳的参数,是你在一个区间里随便挑都能跑,而不是精确到小数点后两位才 work。参数稳健性比单点收益重要一百倍,这点做过的人都懂 9. 2017 ICO、2020 DeFi summer、2021 meme、2022 LUNA/FTX、2023 AI 叙事,每一段市场结构完全不同。你在上一段拟合出来的"规律",换个 regime 直接归零,还倒亏手续费 10. 交易所风险永远比你想的大。FTX 归零、API 限流、插针爆仓、小所跑路、币安突然下架,这些都是"一次就结束游戏"的事。你年化 50% 抵不过一次交易所暴雷,这跟策略多牛逼没关系,做山寨的就要考虑到流动性和“下架风险” 11. backtest 上曲线波动看着很美,真到自己账户里连续三周净值下跌,90% 的人会关掉程序手动调参 12. 分清楚你赚的是 alpha 还是 beta。牛市里所有人都是 quant 大师,熊市一来只剩 beta 的人全被冲走。把多头暴露剥离出来单独看 alpha 曲线,大多数所谓"策略"根本没 alpha,就是变相 long BTC 加一点波动率。 13. ML 在 quant 里有大量虚假繁荣。LSTM、Transformer、强化学习被吹上天,实际在 SNR 极低的金融时序上,一个朴素动量因子加合理风控,能打过你调一万次的 XGBoost 真JB学习起来,quant是真的难得一笔
中文
foufou retweetledi

foufou retweetledi


foufou retweetledi

一个过去五十年未曾有过的时代即将来临
为何通胀如此特别,假如通胀保持五个点以上,所有回报率不超过五个点的生意都没有了性价比,诸如信贷,股票等等
因此世界将会更加看重实际回报,靠梦想和幻想的时代已经过去,这将会是投机最困难的时代
这也是商品的重新定价期,梦想破灭,世界要的是真金白银
Karenin@Kareninyu
通货膨胀,你好!
中文
foufou retweetledi

微软,总算出了个好东西。
开发了一款工具,
可以将几乎任何格式pdfs,word,docs,excel,PowerPoint,Audio,YouTube 网址
转换为Markdown文件,
众所周知Markdown 是AI 大语言模型最青睐的格式。
没有自定义解析器。没有损坏的布局。没有混乱的文本。
只是干净、结构化的标记,
只需一次安装
github.com/microsoft/mark…
中文
foufou retweetledi

开源啦🎉🎉🎉
基于 @karpathy 的 llm-wiki 方法论,我将其从抽象设计模式实现为完整的跨平台桌面应用,兼容 Obsidian,同时还基于原版做了很多优化增强。
🔧 两步思维链 Ingest:拆分为分析+生成两次 LLM 调用,保存到知识库的文件使用 LLM 进行深入分析,拆解内容生成知识图谱。
🧠 知识图谱:将知识库内的内容构建成图谱。
🔍 查询检索:四阶段管线,CJK 二元组分词搜索→图谱扩展→预算控制(4K-1M 可配,60/20/5/15 分配)→带引用编号的上下文组装。
💬 多对话聊天:独立会话持久化,引用面板标注使用了哪些 Wiki 页面,结果还可以保存到 Wiki 同时 Ingest。
我还做了如下改进:
🧠 知识图谱中,加入了不同实体之间的关系强度的加权计算算法,通过关系强度决定 LLM Chat 的时候引用资料的优先级。
🔬 深度研究:对特定话题联网查询资料并进行深度研究,使用 Tavily API 多查询检索,综合后自动 Ingest 回 Wiki,支持并发任务队列。
📎 Chrome 扩展:开发了chrome插件,一键将有价值的网页内容插入知识库。
📄 多格式支持:PDF/DOCX/PPTX/XLSX 结构化提取,保留标题、列表、表格语义,非纯文本转换。
🗑️ 智能级联删除:删资料自动清 Wiki 摘要、索引、死链接,共享实体仅移除引用不删页面。
🖥️ 跨平台工程:Tauri v2 + React 19,全平台兼容。
开源地址:github.com/nashsu/llm_wiki
欢迎 Star🌟
中文
foufou retweetledi

@karpathy Also, I'll here's the skill I made for the wiki.
If you wanna try yourself + hack around with it load it up in your agent of choice. Should work for nearly any data source (Notion, iMessage, etc)
gist.github.com/farzaa/c35ac0c…
English
foufou retweetledi
This is Farzapedia.
I had an LLM take 2,500 entries from my diary, Apple Notes, and some iMessage convos to create a personal Wikipedia for me.
It made 400 detailed articles for my friends, my startups, research areas, and even my favorite animes and their impact on me complete with backlinks.
But, this Wiki was not built for me! I built it for my agent!
The structure of the wiki files and how it's all backlinked is very easily crawlable by any agent + makes it a truly useful knowledge base.
I can spin up Claude Code on the wiki and starting at index.md (a catalog of all my articles) the agent does a really good job at drilling into the specific pages on my wiki it needs context on when I have a query.
For example, when trying to cook up a new landing page I may ask:
"I'm trying to design this landing page for a new idea I have. Please look into the images and films that inspired me recently and give me ideas for new copy and aesthetics".
In my diary I kept track of everything from: learnings, people, inspo, interesting links, images.
So the agent reads my wiki and pulls up my "Philosophy" articles from notes on a Studio Ghibli documentary, "Competitor" articles with YC companies whose landing pages I screenshotted, and pics of 1970s Beatles merch I saved years ago. And it delivers a great answer.
I built a similar system to this a year ago with RAG but it was ass.
A knowledge base that lets an agent find what it needs via a file system it actually understands just works better.
The most magical thing now is as I add new things to my wiki (articles, images of inspo, meeting notes) the system will likely update 2-3 different articles where it feels that context belongs, or, just creates a new article.
It's like this super genius librarian for your brain that's always filing stuff for your perfectly and also let's you easily query the knowledge for tasks useful to you (ex. design, product, writing, etc) and it never gets tired.
I might spend next week productizing this, if that's of interest to you DM me + tell me your usecase!
Andrej Karpathy@karpathy
Wow, this tweet went very viral! I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs. So here's the idea in a gist format: gist.github.com/karpathy/442a6… You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
English
foufou retweetledi

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
foufou retweetledi

foufou retweetledi
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
foufou retweetledi

Athena作者据说在憋一个新的AI Agent架构,我看了看设计的太好了,明天就放到我们公司生产里面
大家可以看看之前的版本
github.com/Athena-AI-Lab/…
感谢你关注此事,埃里克斯·J·面包
中文
foufou retweetledi

想和大伙聊聊,在 AI 时代我是如何深入学习一个技术领域的。
之前没有 AI 之前更多是看书、翻这个领域有名的国内外人的所有博客,然后摘抄记录到笔记本,这种速度挺慢,但是很有学习的乐趣,比如当时学习 WebGL 就是这种感觉,可能学懂一个东西差不多要半年空闲时间,慢但快乐。
现在有了 AI 之后,其实我很讨厌网上那种3分钟教你看完百年孤独,也讨厌一切短剧和倍速看电视剧的方式,更多还是挑好的看,吃好一点。
不过最近写你不知道的 Claude Code 和 Agent 系列,除了自己懂的部分外,其实还有大量不太清楚的领域,好在之前收藏了不少文章,刚好借助这一块清库存,全部搞懂输出出去,一直认为,很多时候,不在于看了多少东西,听了多少东西,输入了多少东西,其实用处不大,更加看重你输出了多少东西,这个才是你自己的。
然后我上上周启动了一个深坑挑战自己,研究大模型的训练流程,确保非专业的人也听得懂,探索了2周,刚好这个经验可以分享给大伙,当然成文也差不多好了,最近会发出。
我会把这个学习过程当做写代码一样的组织,第一步收集高质量的资料,比如与之相关的近几年的精品论文,各大模型厂商发布的关键模型的博客,X上模型负责人发表的一些文章,以及斯坦福等高校的近两年关于这一块的课程学习,还有经典的手搓一个大模型的代码仓库等等,这些都是我的一个资料来源过程,我会借助工具自动化全部下载、转md、清洗,梳理,弄好结构化分门别类到我这次研究的仓库。
然后对于自己看得懂的内容就全部看一遍,把不好的删掉,好的留下,对于看不懂的内容,直接借助 Claude 帮我的理解,更复杂一点的直接翻译成中文去阅读,对于代码本地可以跑的就跑起来,不能跑的那种就去看结构,总之会有一个大概的认识和知晓技术原理,这个阶段可以去掉原有一半可能没有用的内容。
到了这个阶段,其实你对这个领域有一个大概的认知了,就可以给这篇文章开始写一个大纲,以及大纲应该结合的来源内容,这里均可以用markdown很多表达,你要讲什么,或者说你想讲什么更想让读者知道,一定一定,文章是写给你给给看的人看的,需要知晓对方的认知水平,和汇报其实差不多。
然后接下来就是苦力活加之前内容的复习过程,和大学时候考试前复习很像,把每一章的内容填充完整,这样下来,你会得到一篇非常长而且有点啰嗦的文章。
这个时候AI就可以帮太忙,你可以让他帮你不改变你原有的内容意思你的语气的情况下,帮我去掉无用的啰嗦内容,以及连贯不到位的内容,或者是这一块缺少的内容,还需要补充什么知识的地方,借助AI继续去完善补充,这里又可以学到很多原来遗漏的东西。
最后整理好以后,可以继续自己读一遍,而非让AI读一遍,这里AI只是工具,千万不要把你的脑袋被AI代替了,这就没有啥意思来,自己读的过程中可以对文章继续修改调优,这里和写代码又非常像了,自测那种感觉,修复问题修问题,最后读了2遍以后,基本感觉完美了,然后就可以发出来给大伙看看。
有小伙伴肯定是担心自己写的东西没有人看,就不太喜欢发出来,或者说就不写了,其实只要你的内容有意义,自然就有读者,而非是你偷懒的理由。
花10min写完这个碎碎念,结束,欢迎交流你是如何学习一个新领域的,下面视频就是我后面要发的那篇你不知道的大模型训练文章的学习仓库,挺有意思,就录了一个视频给大伙看看我的工业化学习方式。
中文
foufou retweetledi
Quick demo of the new NINR v2 with a noisy WX signal. Sounds like AI, but it's all Natural Intelligence.
Get the beta: airspy.com/download
English
foufou retweetledi

foufou retweetledi

foufou retweetledi
Malahit Mlite-880 – SSB/AM/FM shortwave receiver. The noise reduction feature works really well. Bluetooth support included. For $247.35 aliexpress.com/item/100500981…




English
foufou retweetledi

BREAKING: The US Federal Reserve is now no longer expected to cut interest rates until December 2027.
There is now a 51% chance of an interest rate HIKE by March 2027.
Rate HIKES are now more likely than rate CUTS.
How did we end up here?
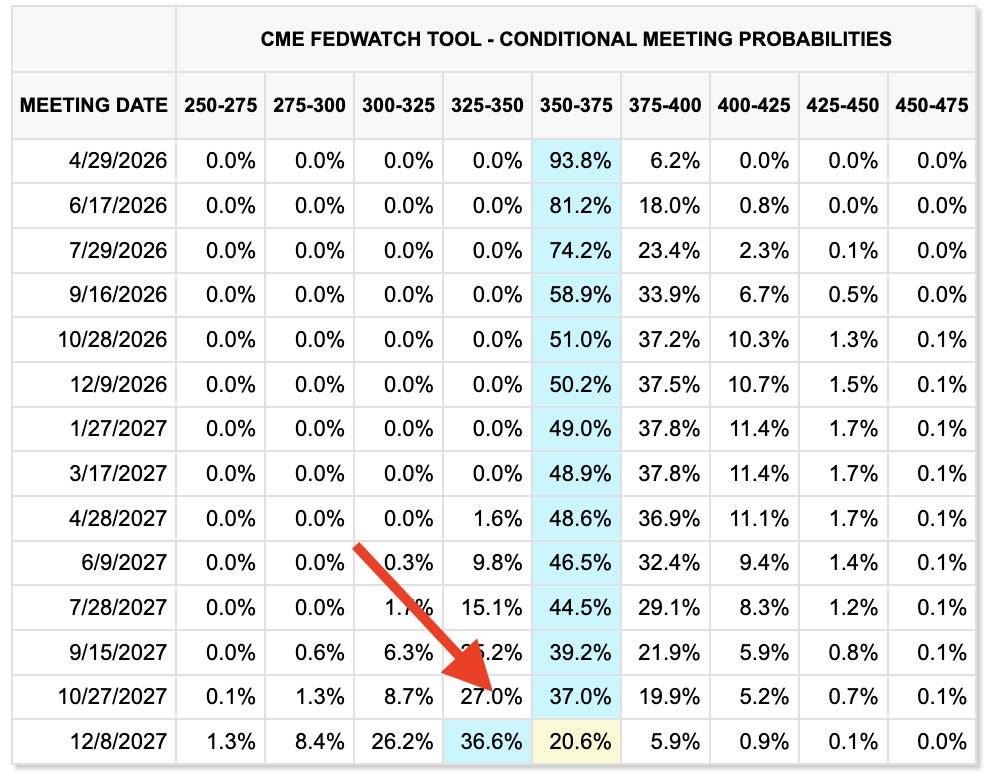
The Kobeissi Letter@KobeissiLetter
English
foufou retweetledi

其实这个市场里大部分交易了几年都豪无长进,不断充钱不断亏的人,本质上是一直没有建立“正向反馈的系统”,也就是战略的懒惰。
最简单的系统:
- 开每一单都必须有逻辑(这个逻辑可以是技术面、基本面、消息面,并有对应的信号,但不可以是“你感觉”)
- 对应每一单的开单逻辑,你的持有周期、和什么时候市场证明你的逻辑是错的是很显而易见的(比如你做新闻交易,半个小时了没涨就该走了,你做技术面的,到了支撑位反弹很弱,你就该先跑了)
- 用结果不断反馈你的开单逻辑
- 等待下一次信号的出现
- 重复这个过程
这件事你坚持做,就不可能不盈利,想盈利真的还没到拼天赋拼科技的程度,但如果你的每一单都是“我觉得”,也说不出什么开单逻辑,那你不亏谁亏,然而在这个市场里你的大部分对手都是“感觉派”。
中文