HALT (“High Accuracy, Less Talk”) accepted to ICLR 2026 🎉
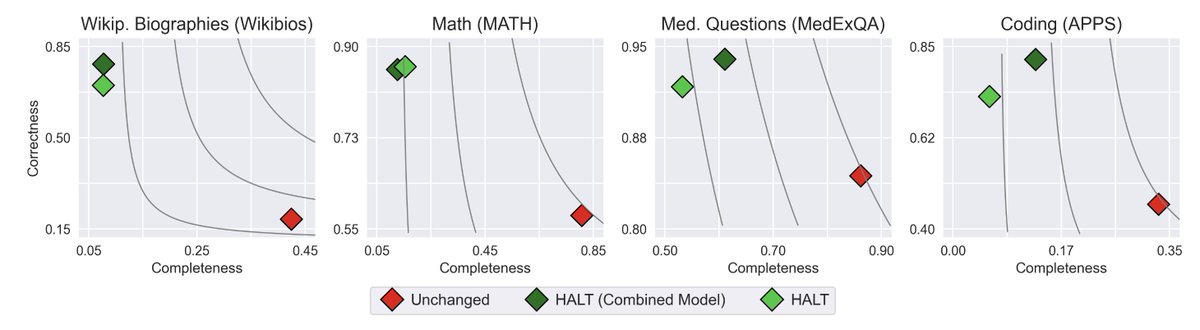
LLMs are trained to always finish answers — even past what they truly know — causing partially wrong outputs.
HALT instead finetunes models to stop when confidence drops, trading completeness for reliability 🚧
👇
Tim Franzmeyer@frtimlive
What if LLMs knew when to stop? 🚧 HALT finetuning teaches LLMs to only generate content they’re confident is correct. 🔍 Insight: Post-training must be adjusted to the model’s capabilities. ⚖️ Tunable trade-off: Higher correctness 🔒 vs. More completeness 📝 with @AIatMeta 🧵
English