Sabitlenmiş Tweet

Happy to introduce 🔥LaM-SLidE🔥!
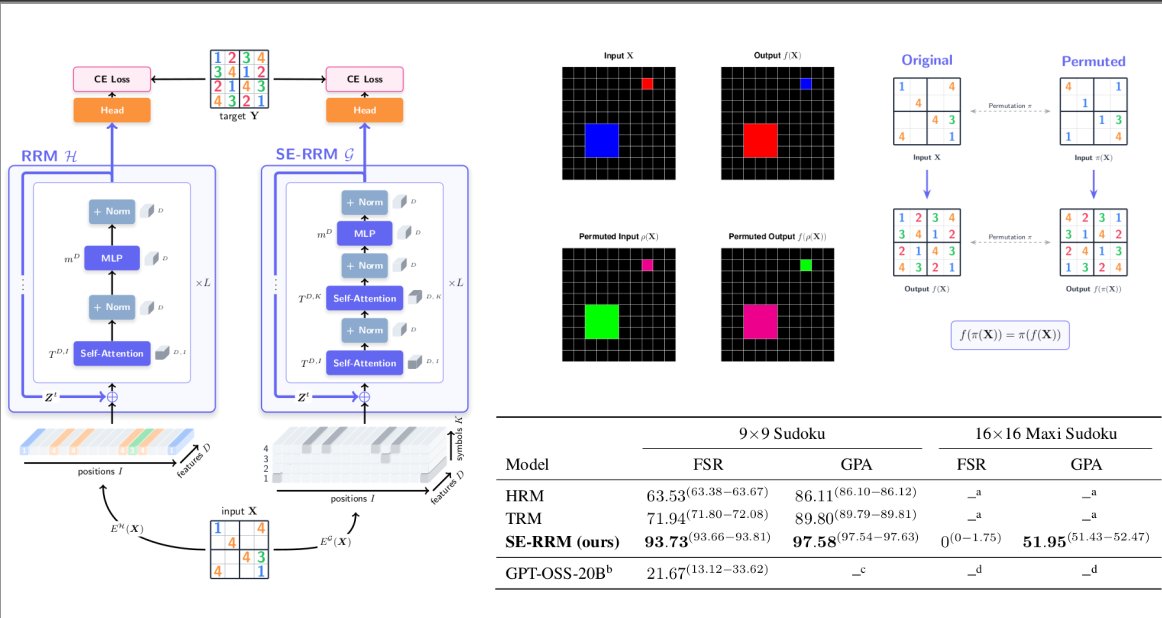
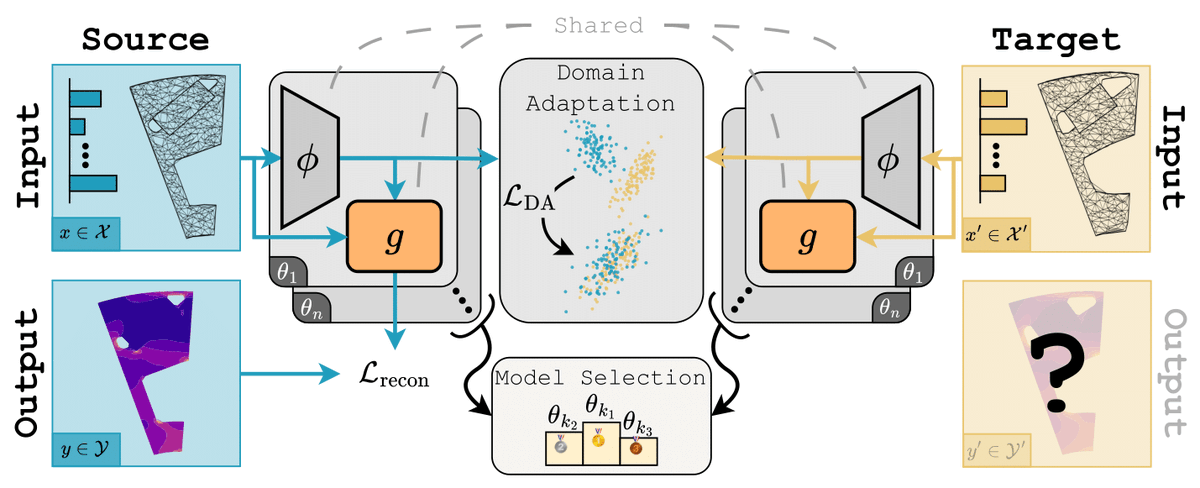
We show how trajectories of spatial dynamical systems can be modeled in latent space by
--> leveraging IDENTIFIERS.
📚Paper: arxiv.org/abs/2502.12128
💻Code: github.com/ml-jku/LaM-SLi…
📝Blog: ml-jku.github.io/LaM-SLidE/
1/n
English