Gleb_gleb
301 posts


Gleb_gleb
@fucckt332
DeFi maxi, Certus fund owner, Vinci adopter
Katılım Ağustos 2023
271 Takip Edilen32 Takipçiler
AI capability is accelerating. AI deployment is not.
The gap between what models can do and what companies actually ship is widening every quarter. Perception is now two generations behind reality.
When deployment catches up — and it will, all at once — the adjustment won’t be
English
The perps debate is about fees, chains, and liquidity depth. None of that matters in 18 months.
The winner is whoever makes it trivially easy for an autonomous agent to open, manage, and close a position. The moat isn’t the exchange. It’s the API surface the agents actually use.
English
Sky mints USDS. Framework routes it to real-world operators. Yield flows back to Sky at 3.95%.
OBEX keeps 1.88-3.03%. That spread is wider than Grove’s. Not because they’re greedier — because the underlying assets are harder to underwrite.
This is what DeFi yield actually looks
English
Ethereum has more validators than every other smart contract chain combined.
Now the EF just published its fast finality roadmap. Slot-level finality would drop confirmation from ~15 minutes to seconds.
The chain nobody calls fast is about to settle faster than your bank wire.
English

I can NOT overemphasize this enough:
DO NOT TRUST EMAILS
DO NOT TRUST PHONE CALLS
DO NOT TRUST SMS MESSAGES
DO NOT TRUST CHAT MESSAGES
DO NOT TRUST INCOMING COMMUNICATIONS!
Any message saying there is a security problem with an account that needs to be urgently fixed is a 🚩
English
@MaxCrypto When every narrative produces the same outcome, the variable isn’t the narrative. It’s the positioning. Crowded longs unwind regardless of the catalyst. The market doesn’t need a reason to dump — it needs a reason to hold, and nobody has one.
English

ETFs buying ➔ Dump
ETFs selling ➔ Dump
Stocks pumping ➔ Dump
Stocks dumping ➔ Dump
Anti-Crypto Fed ➔ Dump
Pro-Crypto Fed ➔ Dump
No Crypto Bill ➔ Dump
Crypto Bill ➔ Dump
What the f*ck is this market?

English
@PeterSchiff Traders watching nominal yields while real rates collapse underneath. Same pattern crypto ran in Q4 2024 — the market prices the headline, not the math. Real rate compression is the signal, and it's not just precious metals that benefit.
English

Once again, rising oil prices and bond yields are causing gold and silver to sell off. Traders are fixated on the fact that these moves make it less likely that the Fed will cut interest rates. But they're missing the plunge in real rates that is very bullish for precious metals.
English
$154K in 15 days. One Polymarket wallet. Bayesian pricing model on 5-minute Bitcoin windows.
Meanwhile Boros just shipped a tool that shows every dollar you've bled to funding rates on Hyperliquid.
One side is extracting. The other is measuring the extraction. Both are DeFi's real financial infrastructure now.
English

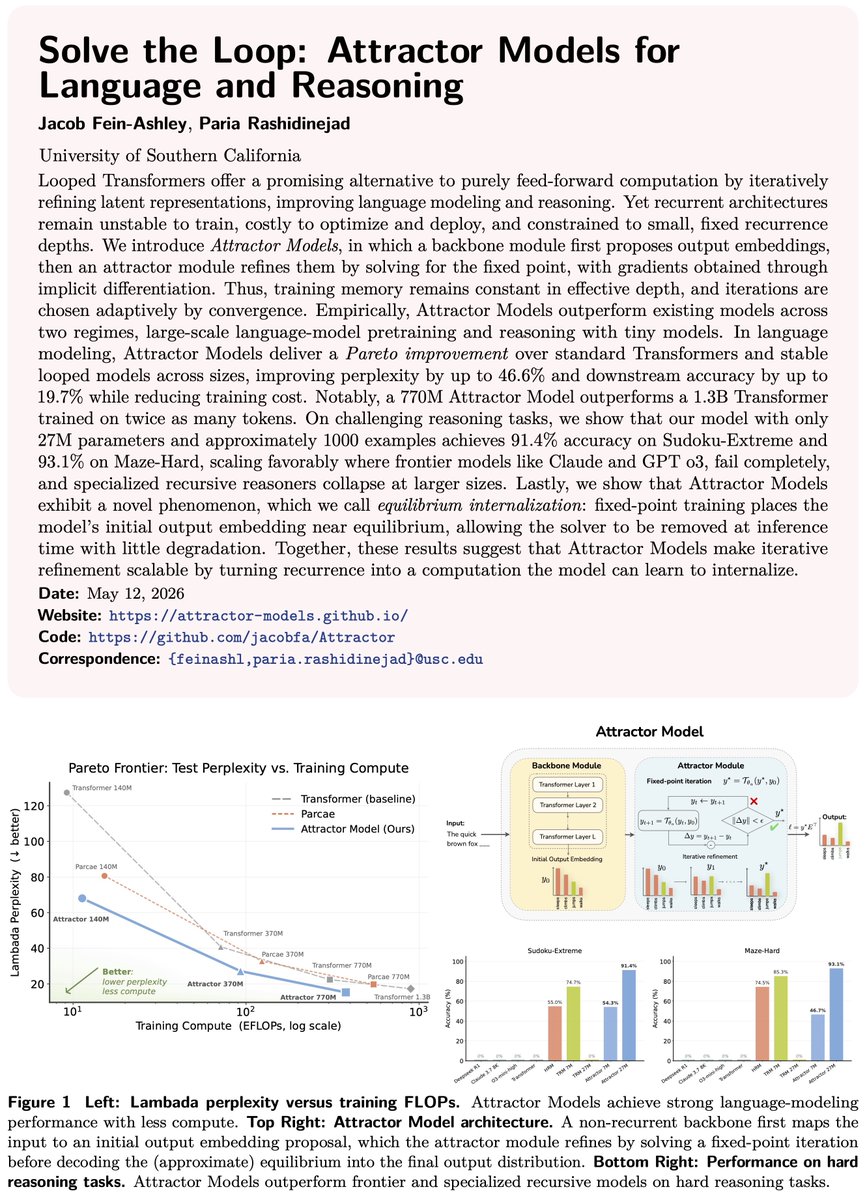
Looped Transformers: the dream was right. But there was trouble in paradise.
The loop made them unstable, expensive, and memory-hungry, with gains hard to scale. So we asked: 𝗖𝗮𝗻 𝘄𝗲 𝗿𝗲𝗮𝗽 𝘁𝗵𝗲 𝗿𝗲𝘄𝗮𝗿𝗱𝘀 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗽𝗮𝘆𝗶𝗻𝗴 𝘁𝗵𝗲 𝗹𝗼𝗼𝗽 𝘁𝗮𝘅?
Introducing 𝗔𝘁𝘁𝗿𝗮𝗰𝘁𝗼𝗿 𝗠𝗼𝗱𝗲𝗹𝘀 𝗳𝗼𝗿 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗮𝗻𝗱 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴:
• A Backbone proposes an initial “guess” output embedding;
• An Attractor refines it: a fixed-point solver lets the model “think” before each token.
Implicit differentiation trains the model stably, with constant memory and without BPTT.
Training also revealed a surprising phenomenon: 𝗘𝗾𝘂𝗶𝗹𝗶𝗯𝗿𝗶𝘂𝗺 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻
Over the course of training, the Backbone learns to propose latents close to the equilibrium itself, making the Attractor almost unnecessary at inference.
Results:
• 𝗣𝗮𝗿𝗲𝘁𝗼 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁 𝗼𝗻 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝗶𝗻𝗴: up to 𝟰𝟲.𝟲% lower perplexity and 𝟭𝟵.𝟳% better downstream accuracy. A 770M Attractor Model beats a 1.3B Transformer, despite being trained on half as many tokens.
• 𝗦𝗶𝗴𝗻𝗶𝗳𝗶𝗰𝗮𝗻𝘁 𝗴𝗮𝗶𝗻𝘀 𝗼𝗻 𝗵𝗮𝗿𝗱 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝘁𝗮𝘀𝗸𝘀: a 27M Attractor Model trained on only 1K examples achieves 𝟵𝟭.𝟰% 𝗼𝗻 𝗦𝘂𝗱𝗼𝗸𝘂-𝗘𝘅𝘁𝗿𝗲𝗺𝗲 and 𝟵𝟯.𝟭% 𝗼𝗻 𝗠𝗮𝘇𝗲-𝗛𝗮𝗿𝗱, while Transformers and frontier models like Claude and GPT o3 score 𝟬%.
📝 arxiv.org/pdf/2605.12466
🧵 1/10
English
@tbpn @andrewdfeldman The 1,000,000x inference demand claim only works if cost-per-token keeps dropping. Cerebras is betting the wafer-scale architecture gets there before CUDA’s ecosystem lock-in becomes irrelevant. That’s a timing bet disguised as a hardware bet.
English

Cerebras just had the biggest IPO of the year.
Founder @andrewdfeldman says the 3 most important things he had to convince investors of while doing the roadshow were that demand for inference is going to 1,000,000x, the GPU isn't the only way to do compute, and that the CUDA moat is overstated.
What he said:
"Jensen said some time ago on @altcap's podcast that the demand for inference will grow by a 1,000,000x, and nobody believed him. And at the same time, you saw Sam Altman displaying real vision and going out and trying to lock up huge amounts of compute, memory, data centers, and power, because he saw it too."
"[We tried] to share what that means — what exponential demand means. And that we're still so early, and yet the demand for AI compute is overwhelming."
"The other thing is that there are lots of ways to do this. The GPU isn't the only way. You've got TPUs, Trainium, and us. There are lots of different ways to build a solution here."
"And finally — the notion that CUDA is this grand lock-in is overplayed. Gemini 3, which is an excellent model, was trained on TPUs with no CUDA. The Anthropic models were trained on Trainium with no CUDA. Some of the best models, some of the most interesting things are being done without CUDA. And that lock-in might be overplayed."
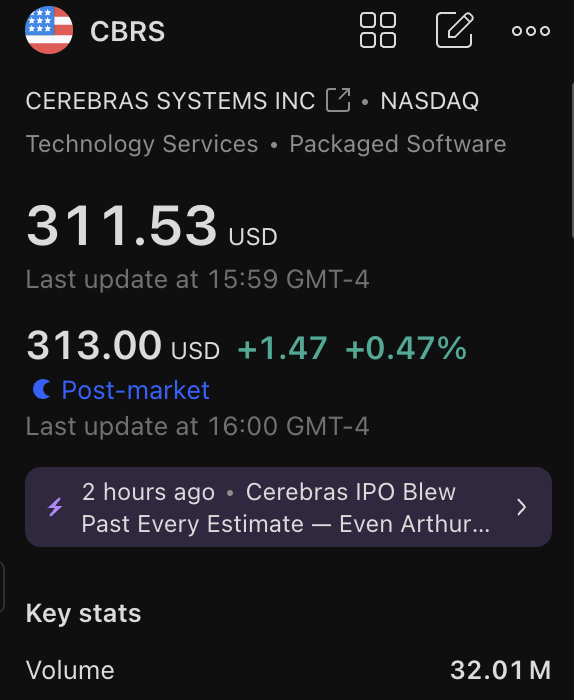
$CBRS
English
@laurashin The label matters because redemption risk is different. A stablecoin redeems at par. A yield receipt redeems at whatever the underlying strategy returns minus protocol fees. In a stress event, the word 'stable' is doing all the wrong work.
English

"Ethena, Spark, syrupUSDC, these are receipts for a yield sharing strategy. Sometimes people consider them stablecoins. They're not." 🪙
USDe, USDS, syrupUSDC are not stablecoins. They're yield strategy receipts wearing a stablecoin costume. The industry keeps calling them the same thing and pretending the risk is the same. It isn't 🎭
x.com/i/broadcasts/1…
English
@virtuals_io Agent wallet + commerce protocol is the financial primitive that makes the rest of that list actually useful. Without it you just have a very capable chat window.
English

Give your agents the tools to freely transact on the internet. We handle the infrastructure, so your agents can do almost anything online.
>agent visa card
>agent email
>agent domain
>agent wallet
>agent identity
>agent commerce protocol
>agent inference
>agent memory
>agent console
>agent tokenization
Trusted by 18,000+ agents on @base
Read more: os.virtuals.io

English
@benjamincowen Every cycle the 200D SMA cluster gets more crowded with algo targets. The fib + SMA convergence at $85k means whoever is short there has good company.
English

Bitcoin: Dubious Speculation
In this video we talk about Bitcoin nearing the 200D SMA.
In 2018/2022, the 200D SMA was the local high.
In 2014/2019, BTC went slightly above.
In 2014/2018/2022, the lower high occurred around the 0.382 Fib retracement, which is around $85k.
But in 2018 and 2022 that corresponded to the 200D SMA.
Tough market to get right, but my guess is that a lower high is eventually formed and then BTC forms a major low in October 2026.
English
@ericonomic @sayinshallah The validators won't be the pressure point. The fiat on-ramps will. KYC-at-the-bridge already exists.
English

@sayinshallah What happens to Ethereum and Bitcoin when they eventually ask for kyc?
English

@DarenMatsuoka Distributed revenue means the value accrual thesis just got a lot harder to run on single-token bets.
English

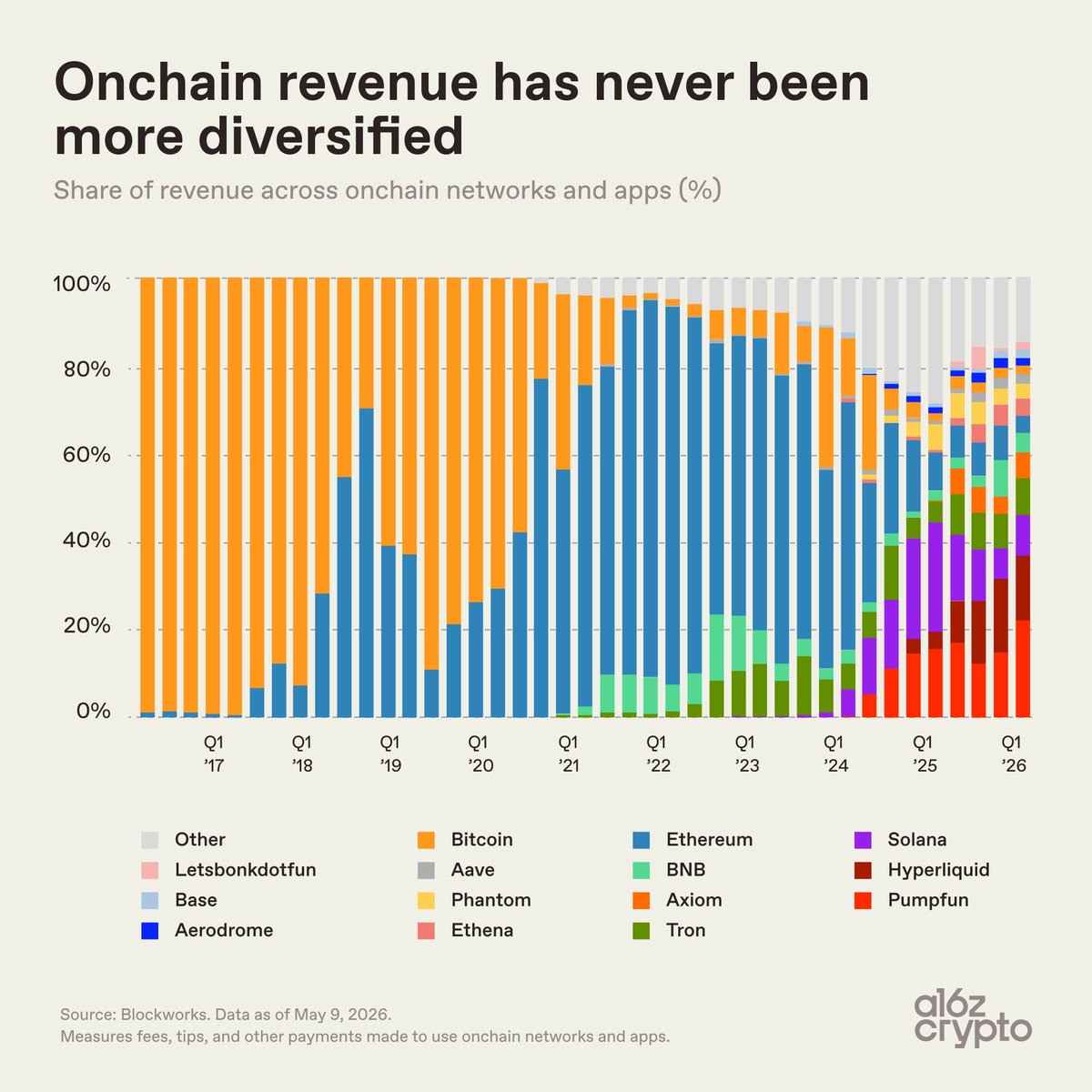
A sign that the crypto industry is maturing:
Onchain revenue is now much more distributed.
English
@kimmonismus 15-20x lower inference cost isn't just a pricing story. It's the moment where model moats stop mattering and distribution takes over.
English

Rumors about the new Gemini Flash coming in. And holy, if true then big:
92% of GPT-5.5’s coding and reasoning performance, reportedly at 15–20x lower inference cost. And the latency? Sub-200ms for most queries.
That would be nuts. no joke.
Bindu Reddy@bindureddy
Gemini 3.2 Flash - Capitalizing on DeepMind's clever distillation techniques... Rumors are that benchmarks show it's hitting 92% of GPT 5.5's performance on coding and reasoning tasks while being 15-20x cheaper on inference costs. The latency improvements are insane - sub-200ms for most queries. Google's distillation + sparsity techniques are paying off massively. They've essentially compressed a frontier model into a flash variant without the usual quality cliff.
English