cada día mas cerca de Idiocracy
·KidRock en el pentagono dando catedra

Español
Gastón Zelarayán
10.4K posts

@gasze
❤️ 𝚖𝚊𝚗𝚒𝚓𝚊 𝚌𝚞𝚛𝚒𝚘𝚜𝚘 𝚎 𝚒𝚗𝚚𝚞𝚒𝚎𝚝𝚘 𝚎𝚗 𝚌𝚘𝚗𝚜𝚝𝚛𝚞𝚌𝚌𝚒ó𝚗🌪️ "Desafiar el miedo a saltar no te da alas, pero te hace más feliz"



This video is literally 50 entrepreneurs giving you an MBA in 18 minutes:


we're making @blocks smaller today. here's my note to the company. #### today we're making one of the hardest decisions in the history of our company: we're reducing our organization by nearly half, from over 10,000 people to just under 6,000. that means over 4,000 of you are being asked to leave or entering into consultation. i'll be straight about what's happening, why, and what it means for everyone. first off, if you're one of the people affected, you'll receive your salary for 20 weeks + 1 week per year of tenure, equity vested through the end of may, 6 months of health care, your corporate devices, and $5,000 to put toward whatever you need to help you in this transition (if you’re outside the U.S. you’ll receive similar support but exact details are going to vary based on local requirements). i want you to know that before anything else. everyone will be notified today, whether you're being asked to leave, entering consultation, or asked to stay. we're not making this decision because we're in trouble. our business is strong. gross profit continues to grow, we continue to serve more and more customers, and profitability is improving. but something has changed. we're already seeing that the intelligence tools we’re creating and using, paired with smaller and flatter teams, are enabling a new way of working which fundamentally changes what it means to build and run a company. and that's accelerating rapidly. i had two options: cut gradually over months or years as this shift plays out, or be honest about where we are and act on it now. i chose the latter. repeated rounds of cuts are destructive to morale, to focus, and to the trust that customers and shareholders place in our ability to lead. i'd rather take a hard, clear action now and build from a position we believe in than manage a slow reduction of people toward the same outcome. a smaller company also gives us the space to grow our business the right way, on our own terms, instead of constantly reacting to market pressures. a decision at this scale carries risk. but so does standing still. we've done a full review to determine the roles and people we require to reliably grow the business from here, and we've pressure-tested those decisions from multiple angles. i accept that we may have gotten some of them wrong, and we've built in flexibility to account for that, and do the right thing for our customers. we're not going to just disappear people from slack and email and pretend they were never here. communication channels will stay open through thursday evening (pacific) so everyone can say goodbye properly, and share whatever you wish. i'll also be hosting a live video session to thank everyone at 3:35pm pacific. i know doing it this way might feel awkward. i'd rather it feel awkward and human than efficient and cold. to those of you leaving…i’m grateful for you, and i’m sorry to put you through this. you built what this company is today. that's a fact that i'll honor forever. this decision is not a reflection of what you contributed. you will be a great contributor to any organization going forward. to those staying…i made this decision, and i'll own it. what i'm asking of you is to build with me. we're going to build this company with intelligence at the core of everything we do. how we work, how we create, how we serve our customers. our customers will feel this shift too, and we're going to help them navigate it: towards a future where they can build their own features directly, composed of our capabilities and served through our interfaces. that's what i'm focused on now. expect a note from me tomorrow. jack



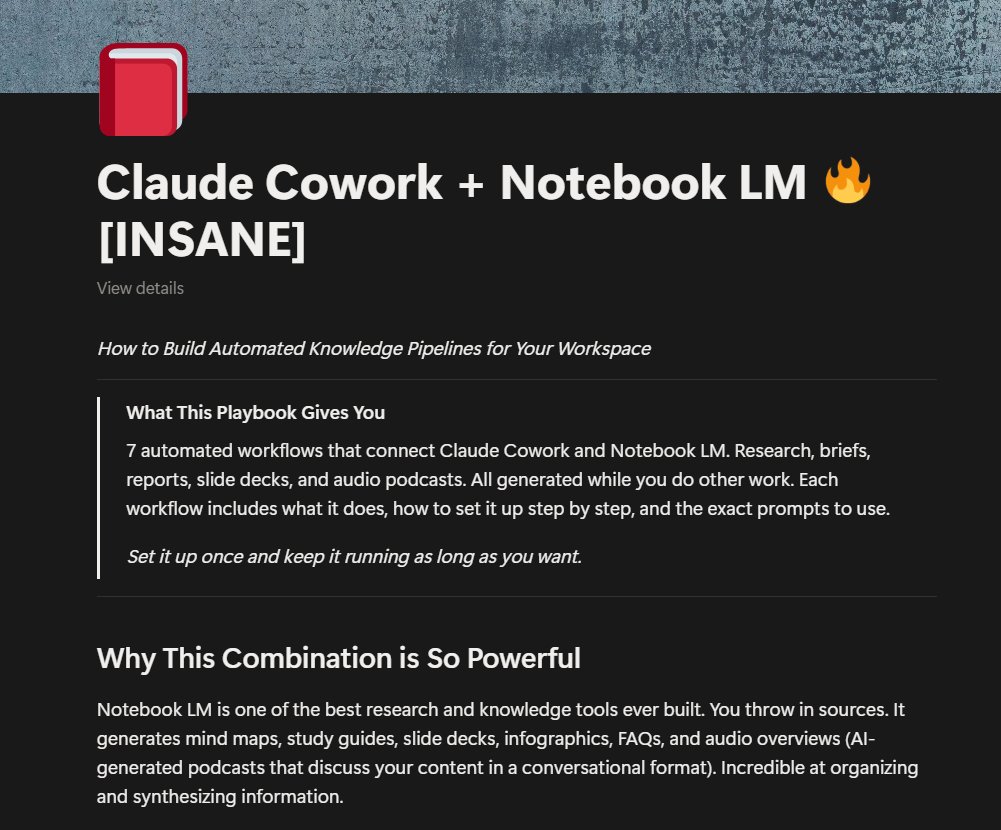



I taught Claude to talk like a caveman to use 75% less tokens. normal claude: ~180 tokens for a web search task caveman claude: ~45 tokens for the same task "I executed the web search tool" = 8 tokens caveman version: "Tool work" = 2 tokens every single grunt swap saves 6-10 tokens. across a FULL task that's 50-100 tokens saved why does it work? caveman claude doesn't explain itself. it does its task first. gives the result. then stops. no "I'd be happy to help you with that." no "Let me search the web for you" no more unnecessary filler words "result. done. me stop." 50-75% burn reduction with usage limits getting tighter every week this might be the most practical hack out there right now