
Erman Eroğlu
1.6K posts

Erman Eroğlu
@geldeki
Mahallesiz/Klansız - Öteki (Yoğurdu Ekşi Olan), Software Developer (Namıdiğer Yazılımcı)
Katılım Ocak 2023
1.4K Takip Edilen246 Takipçiler

@AlexJonesax llama cpp + turboquant gave me ~11 tokns/sec on my m4 pro 24gb.
Català


@JayanthSanku01 Thank you Jayanth! @grok tell me the the KV cache and the context size relationship in more detail in terms of their ram usage optimizations
English

@furkanbytekin Minimax 2.7 20 dolarlık alın. Ben memnunum. Token Bitme ihtimali yok
Türkçe

Deepseek aldım 5 dolarlık. o da 2 saatte 0.40$ yaktı. bugün komple çalışsam 2.5$ falan yakacak. aylık 75 dolar edecek bu da. yani yapay zeka için en ucuz modellerde bile 75 doları gözden çıkarmamız gerekecek. Yerelde çalıştırabileceğimiz bir şey yok mu ya 😣
Türkçe
@jun_song Daha ne kadar yükselecek ki? Bu biraz abartılı bir iddia değil mi?
Türkçe

제가 이 글을 올린지 2달이 조금 안되었는데,
이미 전세계에서 중고 MacStudio 가격은 1.5배에서 2배 비싸졌습니다.
이제는 신제품도 판매가 중단되었고, 로컬LLM의 수요는 계속해서 늘어나고있습니다.
Cloud AI 구독비용은 사라지지만, 하드웨어는 사라지지 않습니다.
가격은 오히려 오를겁니다.
송준 Jun Song@jun_song
구형 맥스튜디오 중고가격이 엄청나게 오를겁니다. 사실꺼면 빨리 사시는게 좋아요. 이미 m1 m2 64gb이상 램 모델은 전국에서 품절이고 어디를 봐도 구매글밖에 없습니다. 로컬LLM이 소형화되는 추세고, 추론에 필요한건 VRAM과 대역폭뿐인데, 중고가격이 반값도 안되는 M1과 신형인 M4는 추론성능으로는 차이가 크게 안납니다
한국어
@kreadony @ozgurozturknet İdare ediyor. Hatta 10 dolarlık subscription a düşeceğim bu ay. Muhtemelen yeter
Türkçe

@geldeki @ozgurozturknet Baya baya kullanıyorsun 😁 memnun musun genel olarak ?
Türkçe

Yav bu deepseek neymiş böyle. Claude ile merhaba diyorsun bismillah 25 dolar. İki gündür deepseek'i ırgat gibi çalıştırıyorum, gerçek ırgat olsa iki katlı evi tek başına dikmisti o kadar çok çalıştırıyorum daha yarım dolar yakmamış.
Türkçe
@kreadony @ozgurozturknet Ayrıca Claude code da da kullanabiliyorum tabi. Ama seviye olarak tabii ki bir opus 4.7 değil.
Türkçe
Openclaude ile agent olarak kullanıyorum. Ayrıca vps e kurulu Hermes e bağladım. Onun üzerinden telegram kripto sinyal botu arsa botu haber botu ve klasik chatbotu olarak kullanıyorum şimdilik. Eve kamera sistemi döşeyip anlık yüz tanıma alarm güvenlik sistemi vs projelerim var. İşte kullanıyorum tamamen kişisel şeyler için yetiyor. İşte Claude opus 4.7 kullanıyorum
Türkçe
@robink78 @ozgurozturknet Bende minimax 2.7 +hermes var. Ama sabit 20$ olan subscription.4 saatlik dilimler halinde kotalar var. Daha 4 saatte kotanın yüzde 15 ini kullandığımı hatırlamıyorum. Kaçak afghan işçisi gibi maşallah. Acaba deepseeke geçmeli miyim?
Türkçe

@wanerfu Sorry but it did not work for Turkiyes 2 mainstream real estate sites due to cloudflare bot recognition, 1: sahibinden.com 2: Hepsiemlak.com
English

OpenClaw 现在可以抓取任何网站而不被屏蔽——零机器人检测,原生绕过 Cloudflare,比 BeautifulSoup 快 774 倍。
无需维护选择器。无需变通方案。只需数据。
这是不公平的优势,而且完全开源。
github.com/D4Vinci/Scrapl…

中文
@D4Vinci1 @wanerfu Sorry but it did not work for 2 main real estate sites due to cloudflare bot recognition, 1: sahibinden.com 2: Hepsiemlak.com
English

@wanerfu Thanks for writing about my project :)
Here’s the full docs if anyone is wondering: scrapling.readthedocs.io/en/latest/inde…
English

So many exciting AI toys and models to test! We need 48 hours a day!
English
Erman Eroğlu retweetledi
AI는 인류에게 가장 중요한 자산이 되었습니다.
최신 프론티어 모델에 접근 가능여부로 계급이 나누어집니다.
Sonnet을 사용하는 사람과, Opus를 사용하는 사람의 생산성은 비교가 불가능하니까요.
그 시대를 오늘 Antrophic이 시작했습니다.
그리고 제가 예측한것처럼 $20 플랜은 $100가 되었습니다.
Opus에 대한 접근의 최소치를 $100로 올린겁니다.
이 가격은 여전히 그들의 적자를 커버하지 못합니다.
지능당 가격은 계속해서 낮아지는건 사실입니다.
하지만 사람들은 Mythos와 같이 더욱 더 많은 컴퓨팅이 필요한 고급 모델을 원할겁니다.
그것이 가격이 계속해서 올라가는 이유입니다.
Mythos를 사용하는 최상위 계층과, Opus를 사용하는 중위 계층, Sonnet을 사용하는 하위 계층으로 나누어집니다.
이런 계급나누기에 휩쓸리지 않기위해 앞으로 사람들은 자신만의 지능을 구축할겁니다.
그것은 로컬LLM이고, 앞으로 수요는 계속 늘어날수밖에 없습니다.
세상의 변화에 대비해야합니다.
한국어


@kIzIL_Sayfa @grok olayı detayları ve Orhan Yılmazkayaya ne olduğunu anlat
Türkçe

Orhan Yılmazkaya'nın 27 Nisan 2009'da İstanbul Bostancı'da polisin "Teslim ol" çağrısına verdiği yanıt;
🗣"Teslim olmayan fedai bir devrimci kuşağın layığı olmaya çalışacağım...
Biz düşeceğiz fakat bizden sonra mutlaka bu kavga sürecek..,
Nasıl binlerce yıldır sürdüğü gibi..,
Thomas Müntzer’lerden Şeyh Bedreddin’lerden bu yana sürdüğü gibi..,
Mahir Çayan’lardan, İbrahim Kaypakkaya’lardan sürdüğü gibi
Türkçe

For a 96GB Mac Studio M3 Ultra with MLX (mlx-lm), the recommended max context is **16K–32K tokens** for most practical use (e.g. 13B–70B quantized models like Q4/Q5/Q6).
This keeps total usage under ~80% of unified memory (model + KV cache + macOS overhead). Smaller 7B–13B models can safely go to 64K+.
Set `--max-kv-size` accordingly and monitor in Activity Monitor to avoid pressure. The M3 Ultra's extra bandwidth helps sustain speed at longer contexts—test your specific model.
English

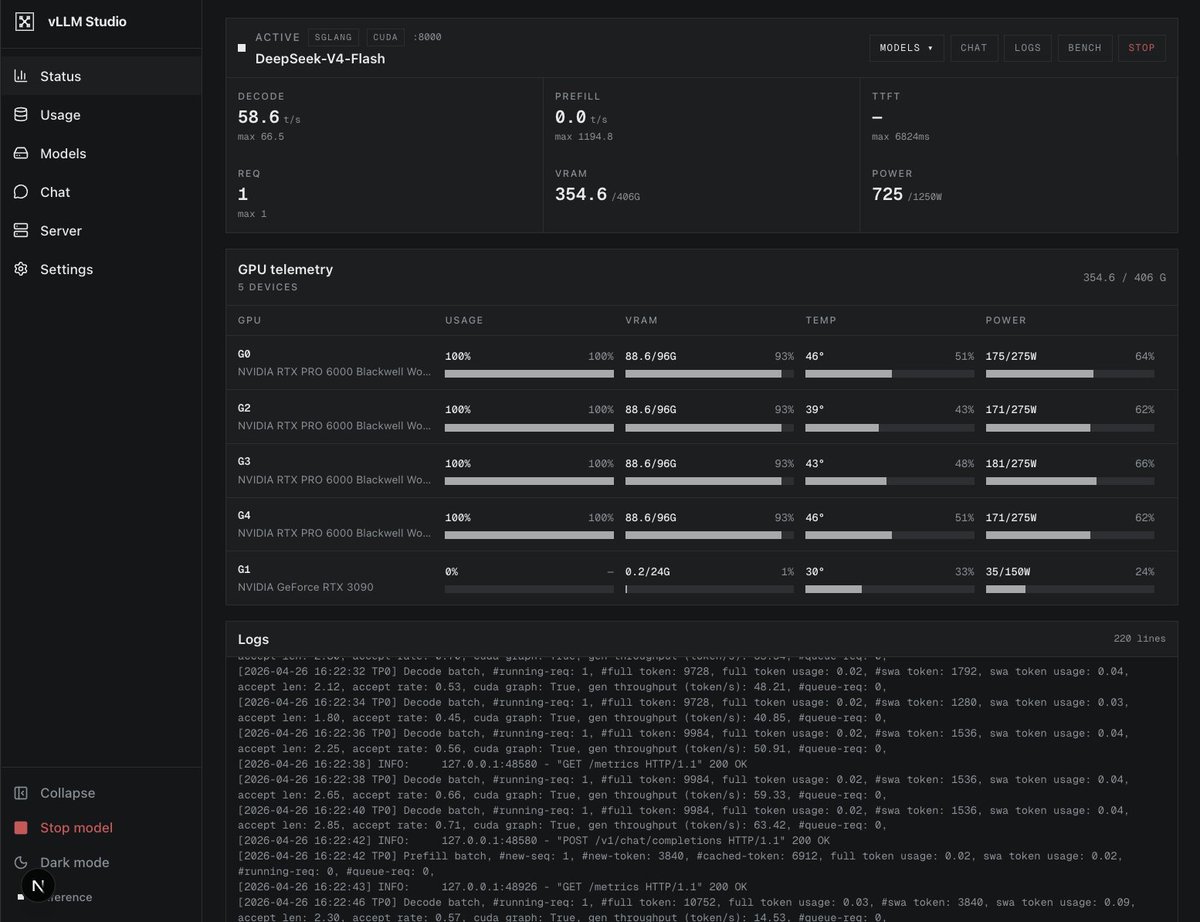
For a 32GB M2 Max MacBook Pro with MLX (mlx-lm), the recommended max context is **4K–8K tokens** for most practical use (e.g. 13B–30B quantized models like Q4/Q5).
This keeps total usage under ~80% of unified memory (model + KV cache + macOS overhead). Smaller 7B–8B models can safely go to 16K–32K.
Set `--max-kv-size` accordingly and monitor in Activity Monitor to avoid swapping. Larger contexts eat RAM fast—test your specific model.
English