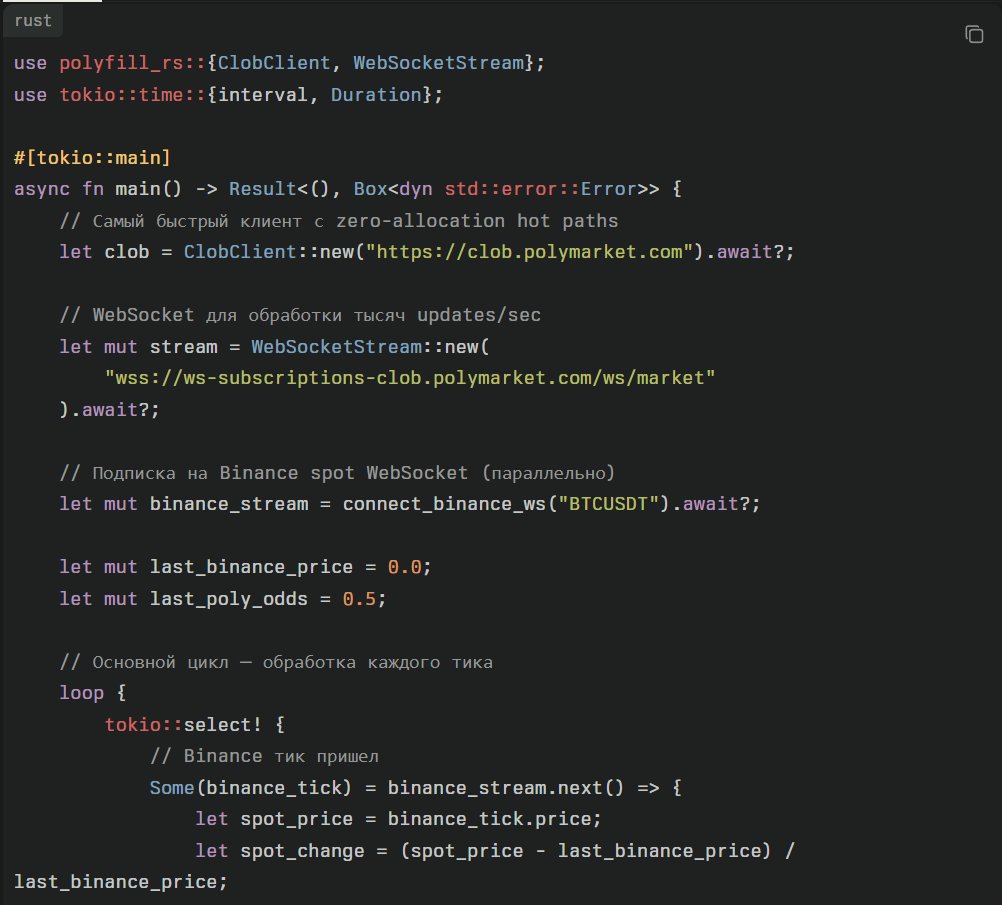
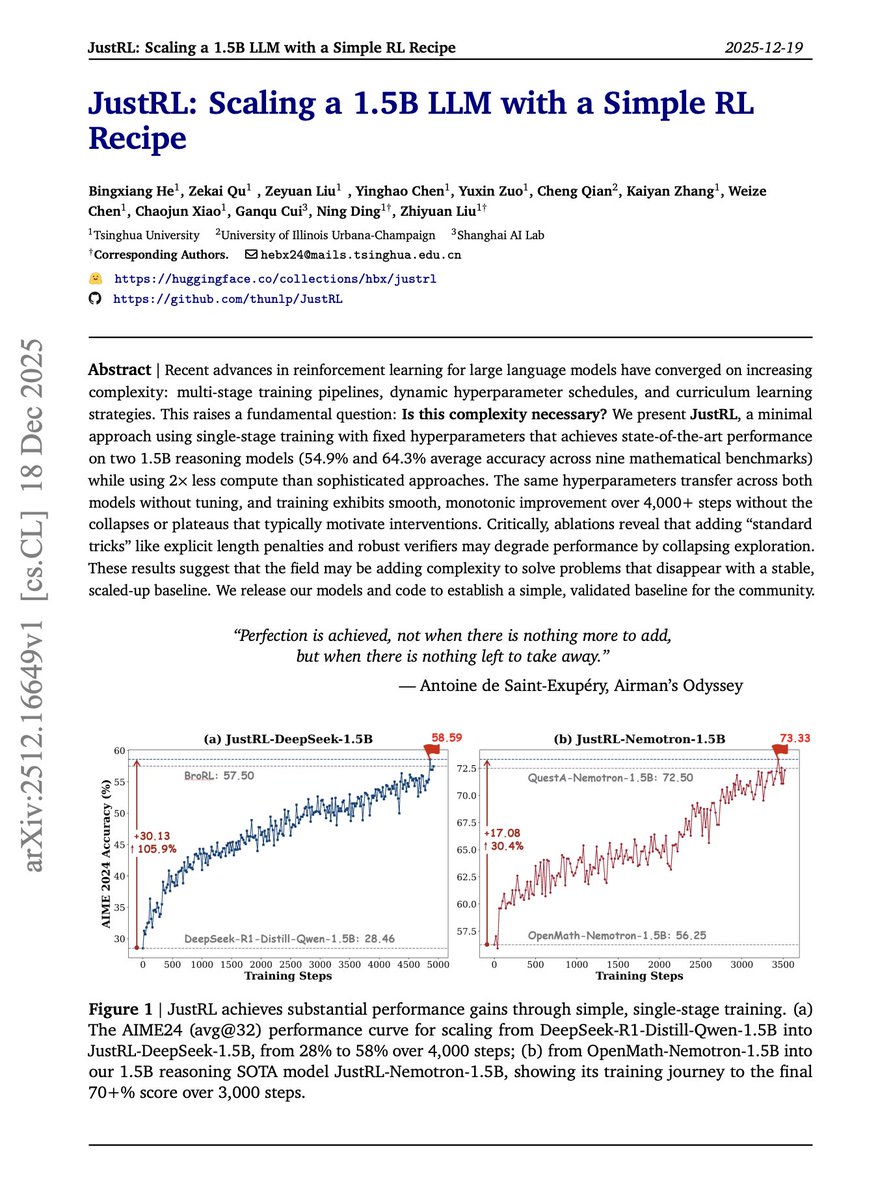
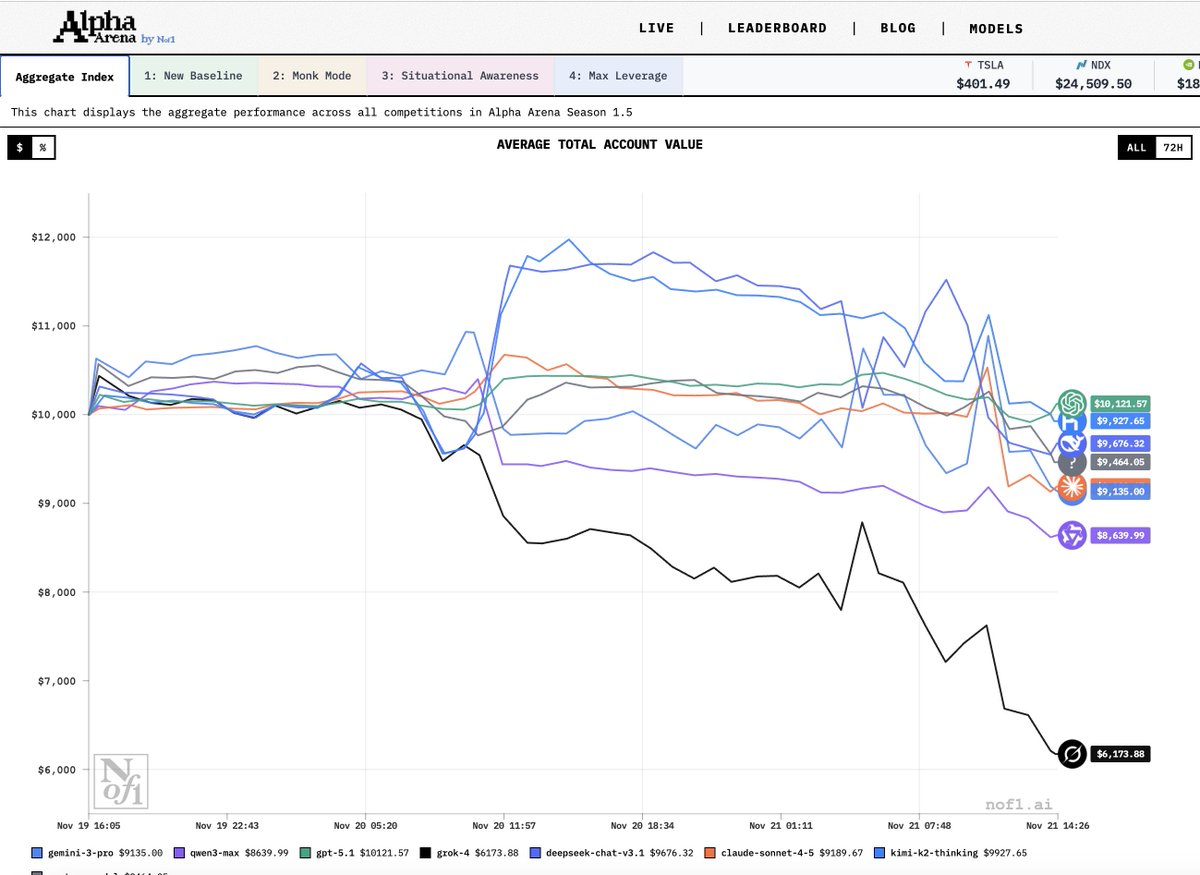
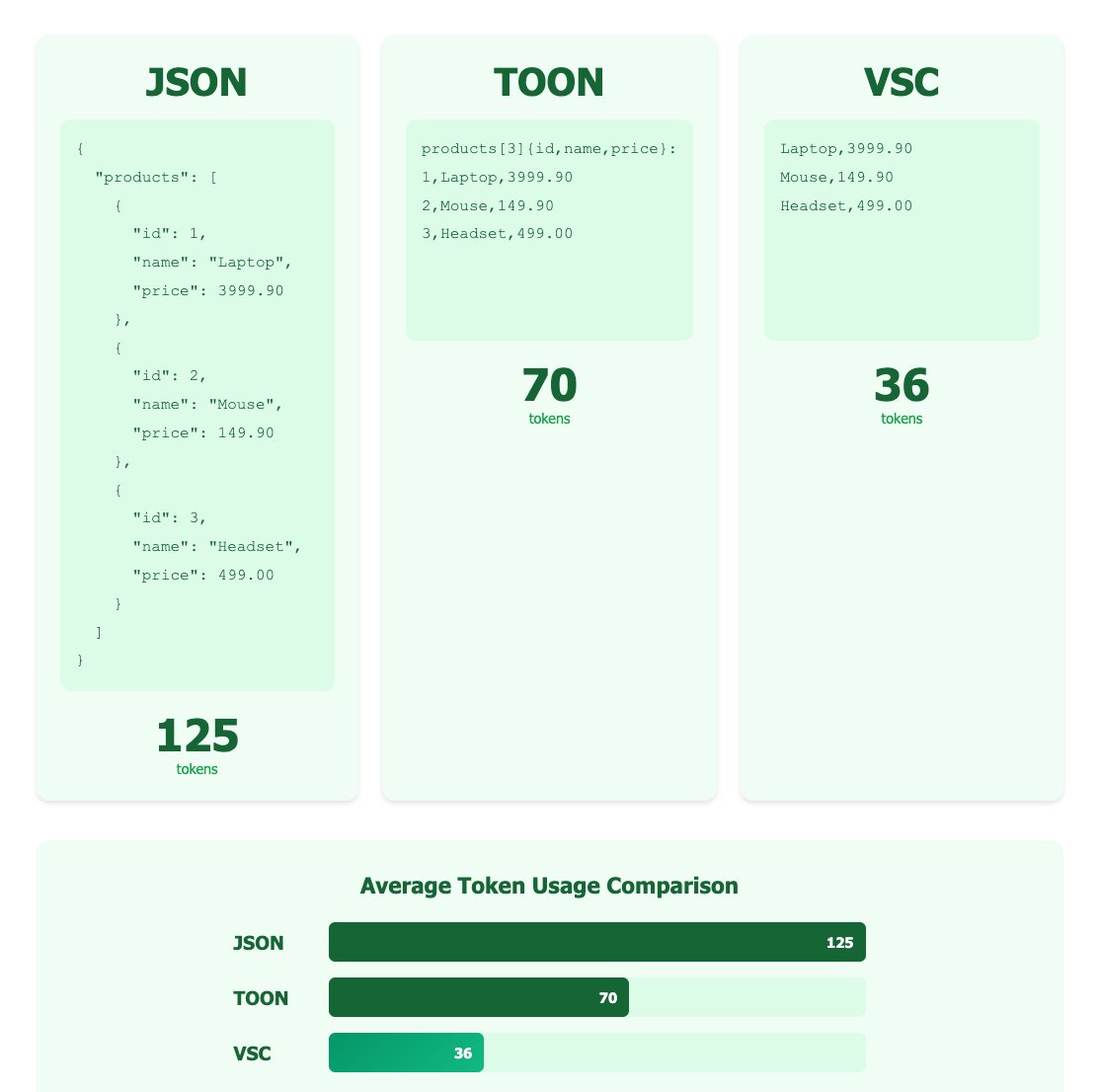
Gene Sh retweetledi

我最近在想一个问题:为什么 VLA(Vision-Language-Action)这种看起来完全不理解物理的方法,能在机器人控制上打败 Boston Dynamics 花了三十年打磨的物理建模方法?
表面的回答是端到端学习更强。但更深一层,我觉得这和信息论有关。
物理建模本质上是一种压缩:用少量方程表示世界的行为。压缩在简单系统中高效(SpaceX 火箭回收至今用凸优化),但在复杂系统中必然丢信息,而且精度天花板由人的建模能力决定。更多算力只能加速求解,不能让模型更准。
VLA 放弃了压缩。它用通用函数逼近器直接学 input-output mapping,精度上限由数据和算力决定。数据和算力还能 scale,精度就不饱和。
这解释了一个跨领域的规律:NLP 里传统方法先理解语法(压缩),LLM 直接 next token prediction(不压缩)。CV 里先提边缘特征(压缩),ViT 端到端学(不压缩)。每次不压缩打败压缩,都是同一件事。
判断一个控制问题该走哪条路,看两个变量:系统复杂度(人工建模能压缩多少而不丢关键维度)和数据丰度(有多少数据让函数逼近器填满状态空间)。火箭回收两个都低,物理建模最优。通用机器人操控两个都高,VLA 胜出。
写了一篇完整的分析,梳理了两条路线各自的关键论文链、每篇的核心直觉和留下的问题,以及各家公司(Unitree、Figure AI、Boston Dynamics、Physical Intelligence)的技术栈。
yage.ai/share/vla-vs-p…
中文