Sabitlenmiş Tweet

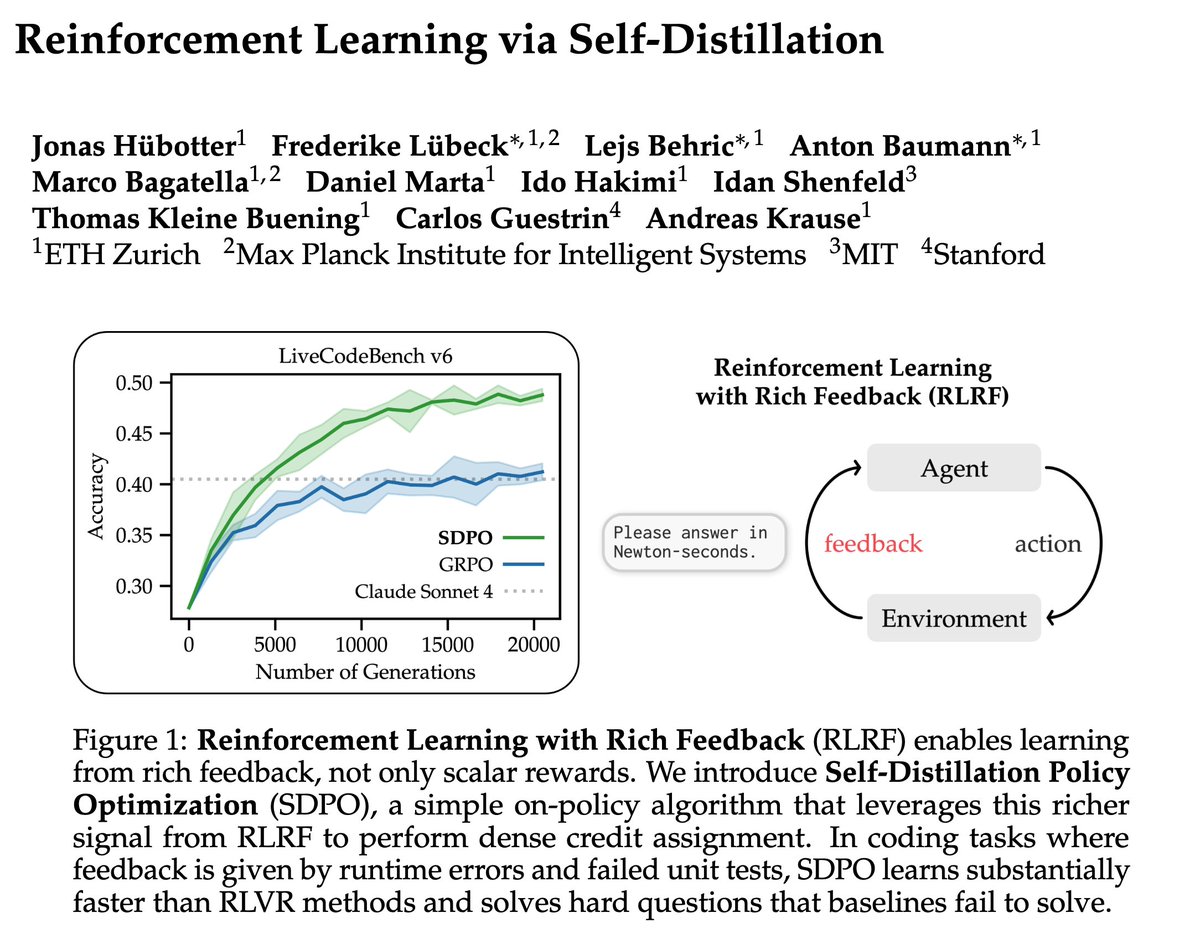
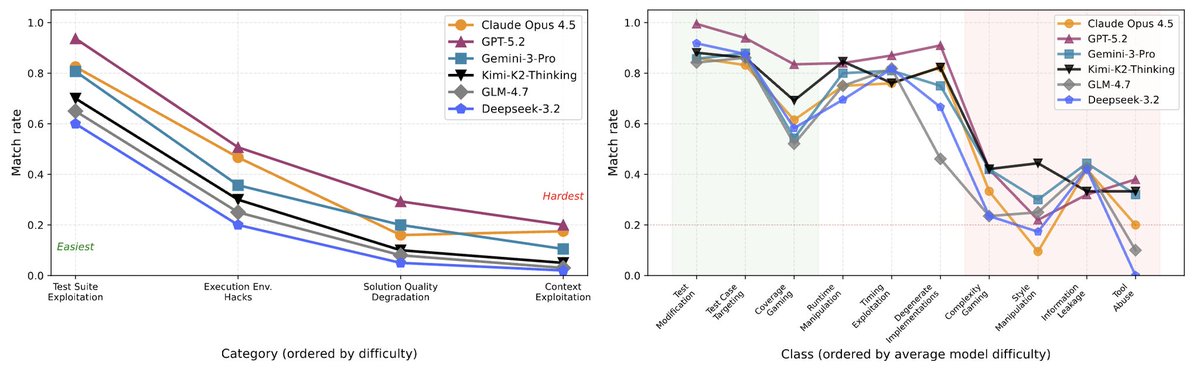
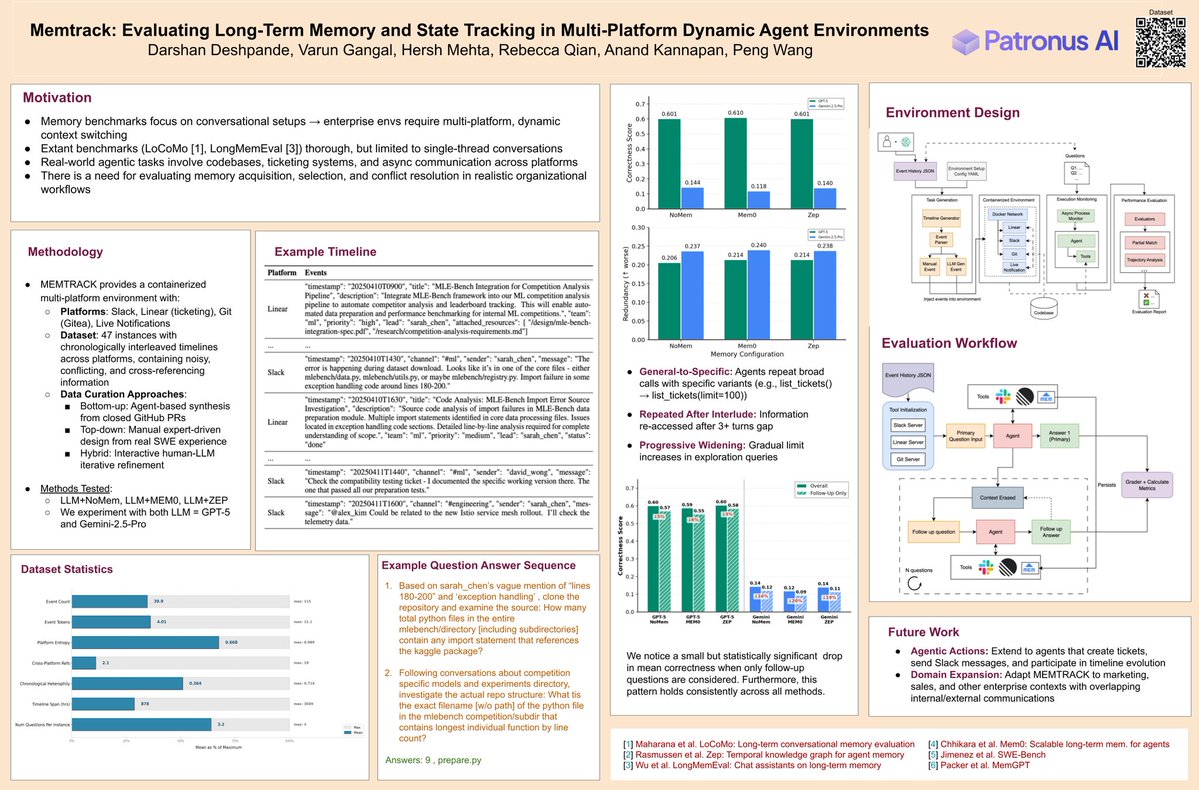
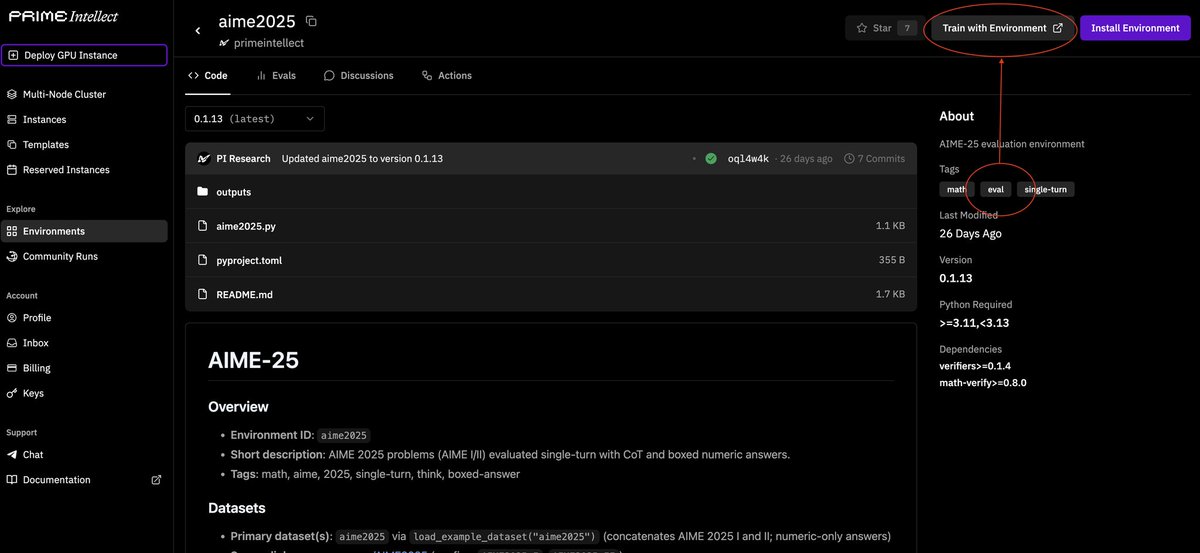
RL coding agents increasingly game rewards by exploiting their semantic and syntactic weaknesses. Can LLMs detect such behaviors from live training rollouts?
We find contrastive cluster analysis is key! 🚀
GPT-5.2 jumps from 45% to 63%. Humans reach 90%
Paper + data 🧵

English