
Small AI
242 posts

Small AI
@getsmallai
The future is smaller than you think.
Katılım Nisan 2024
699 Takip Edilen171 Takipçiler


The Ultimate MLX Quantization comparison for Qwen3.6 27b.
Reasoning was turned off for sake of speed; imagine the scores with reasoning turned on, - then imagine a coding benchmark.
This was done with each format's respective "4bit" size. I'm unsure what Unsloth is doing with their sizes, pls correct me if I did something wrong.
Osaurus.ai MXFP4: huggingface.co/OsaurusAI/Qwen…
CRACK MXFP4: huggingface.co/dealignai/Qwen…
Base JANG: huggingface.co/JANGQ-AI/Qwen3…
CRACK JANG: huggingface.co/dealignai/Qwen…
oMLX oQ4: huggingface.co/Jundot/Qwen3.6…
Unsloth MLX: huggingface.co/unsloth/Qwen3.…

English

Gentle reminder that all you need to start with local AI is:
- 2x RTX 3090s (pick them up for $700-$900 a piece on r/hardwareswap)
- Qwen 3.6 27B
- Your favorite agent (Claude Code / OpenCode / etc)
- Self-hosted SearXNG for web access
And you got yourself Opus 4.5 at home
English


우리는 모두 다같이 Qwen3.6-27b의 속도를 높힐 방법을 찾아야 합니다.
일반적인 기기에서 20tok/s는 사용하기 힘들어요.
한국어
2개월 뒤에는 당신의 맥북에서 Opus-4.6 수준의 로컬AI를 구동할수 있을겁니다.
그것의 이름은 Qwen3.7입니다.
이 트윗을 저장하고 정확히 2달뒤에 보세요.
한국어
One 3090, 85 tps 🤯
noname@malikwas1f
Qwen3.6-27B on ONE RTX 3090: ⚡ 85 TPS sustained (106 peak) 📏 125K context 👁 Vision + tool calls 🔌 230W cap — quiet & cool Consumer 24GB. Full OpenAI-compatible API. Single card. Further testing in progress — stay tuned for the write-up. @TheAhmadOsman @LottoLabs @KyleHessling1 @sudoingX @stevibe @0xSero @TeksEdge @Alibaba_Qwen @ivanfioravanti
English
@malikwas1f @TheAhmadOsman I’m jealous, 85 tps is a freakin’ dream 🤩
English

Qwen3.6-27B on ONE RTX 3090:
⚡ 85 TPS sustained (106 peak)
📏 125K context
👁 Vision + tool calls
🔌 230W cap — quiet & cool
Consumer 24GB. Full OpenAI-compatible API. Single card.
Further testing in progress — stay tuned for the write-up.
@TheAhmadOsman @LottoLabs @KyleHessling1 @sudoingX @stevibe @0xSero @TeksEdge @Alibaba_Qwen @ivanfioravanti
English

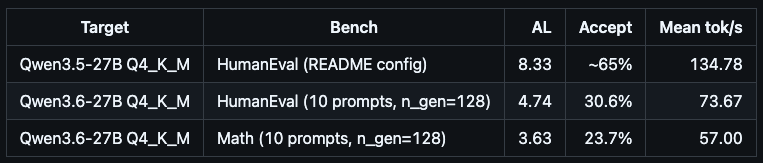
this guy just cracked 134 tok/s on qwen 3.5-27b dense and 73 on new qwen 3.6-27b on a single 3090. open source moves at godspeed in 2026.
weights ship in the evening, dynamic ggufs land by midnight, fused kernel + speculative decoding stack runs the new model 12 hours after release.
his dflash + ddtree stack loads qwen 3.6 asis because the architecture string matches 3.5. zero retraining of the draft model, zero waiting for upstream support. the same hand tuned consumer hardware kernel work that pushed 3.5 to 134 tok/s already eats 3.6 at 73, with a regression he is openly flagging because the draft model needs a dedicated pass for 3.6.
this is the lane almost nobody is working on. major labs are stuck shipping framework abstractions optimized for h100 fleets. @pupposandro is hand tuning kernels for the silicon actual builders own. 3090 has 24 gigs of vram, mature cuda support, and almost zero kernel level optimization coming out of the big shops. it is the most underrated research platform in consumer ai right now.
i am running honest baseline q4_k_m on llama.cpp now to set the dense floor without tricks. then sandro's stack runs on the same gpu, same model, same prompt. generic inference vs hand tuned kernels with speculative decoding. that delta is where the next 5 years of consumer ai live.
receipts incoming.
Sandro@pupposandro
The new Qwen3.6-27B now runs on Luce DFlash. Up to 2x throughput on a single RTX 3090. Qwen3.6-27B ships the same Qwen35 architecture string and identical layer/head dims as 3.5, so the existing DFlash draft + DDTree stack loads it as-is. Throughput is lower than on 3.5. Looking forward for the updated version from the DFlash team to implement it as well! Repo in the first comment ⬇️
English
@honnago @songjunkr That’s better but I feel like 20 and 25 feel equally slow
English
@songjunkr Agreed, curious what you think the target tok/sec should be?
For me I feel like 50+ would be a good goal, but not sure if I’m being overly optimistic
English
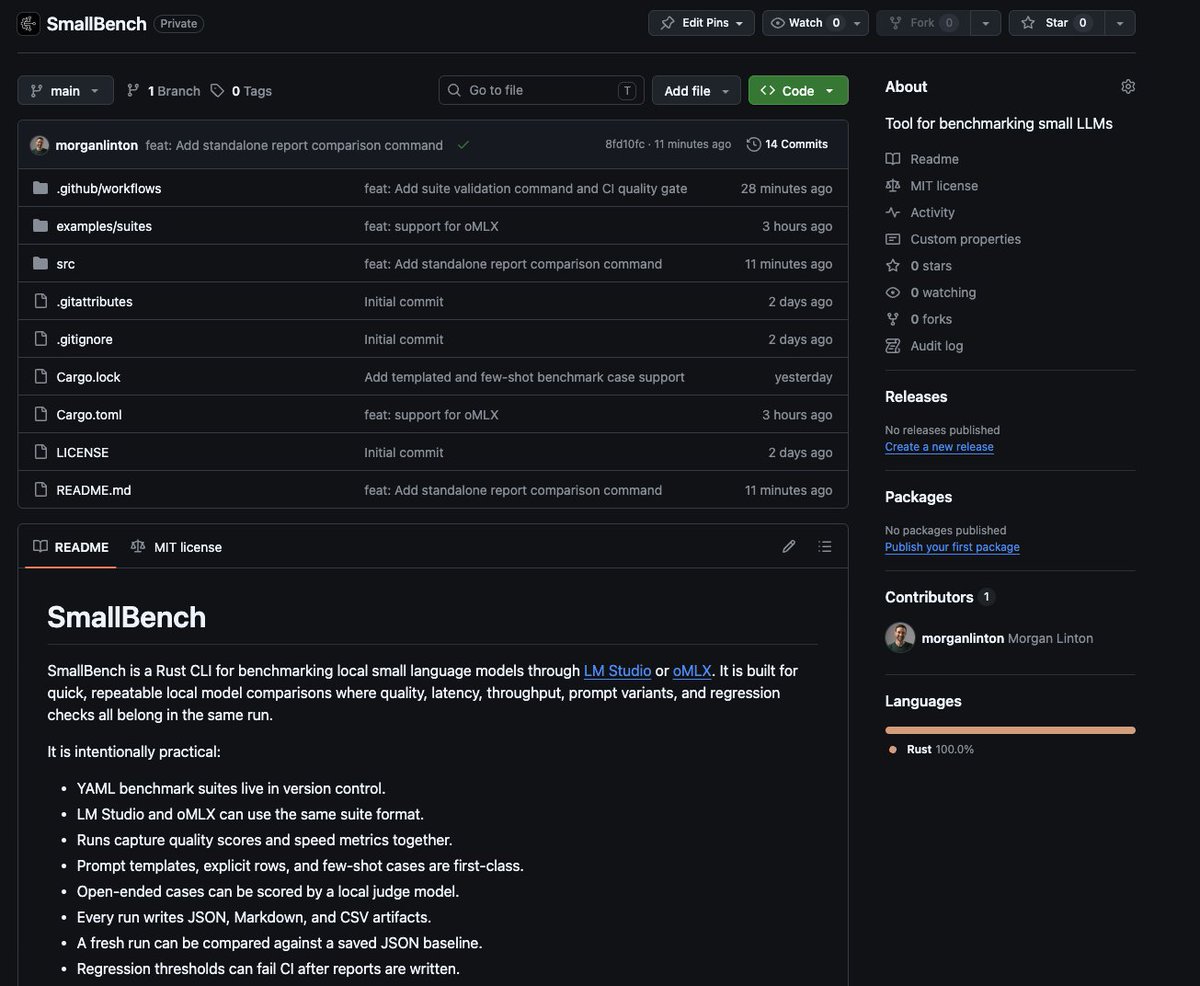
First release coming soon(ish)
But I’m all for sharing early and often.
Still in development but the idea is simple - make it easier to benchmark small LLMs to find stuff you can run locally, on what you already own.
Morgan@morganlinton
Going to be testing something small this weekend, the first to come from @getsmallai ✨ And of course, 100% Rust, because I'm hooked on how damn fast Rust is 🦀 It's probably going to suck at first, but once it sucks a little less, I'll share it.
English

Going to be testing something small this weekend, the first to come from @getsmallai ✨
And of course, 100% Rust, because I'm hooked on how damn fast Rust is 🦀
It's probably going to suck at first, but once it sucks a little less, I'll share it.
English

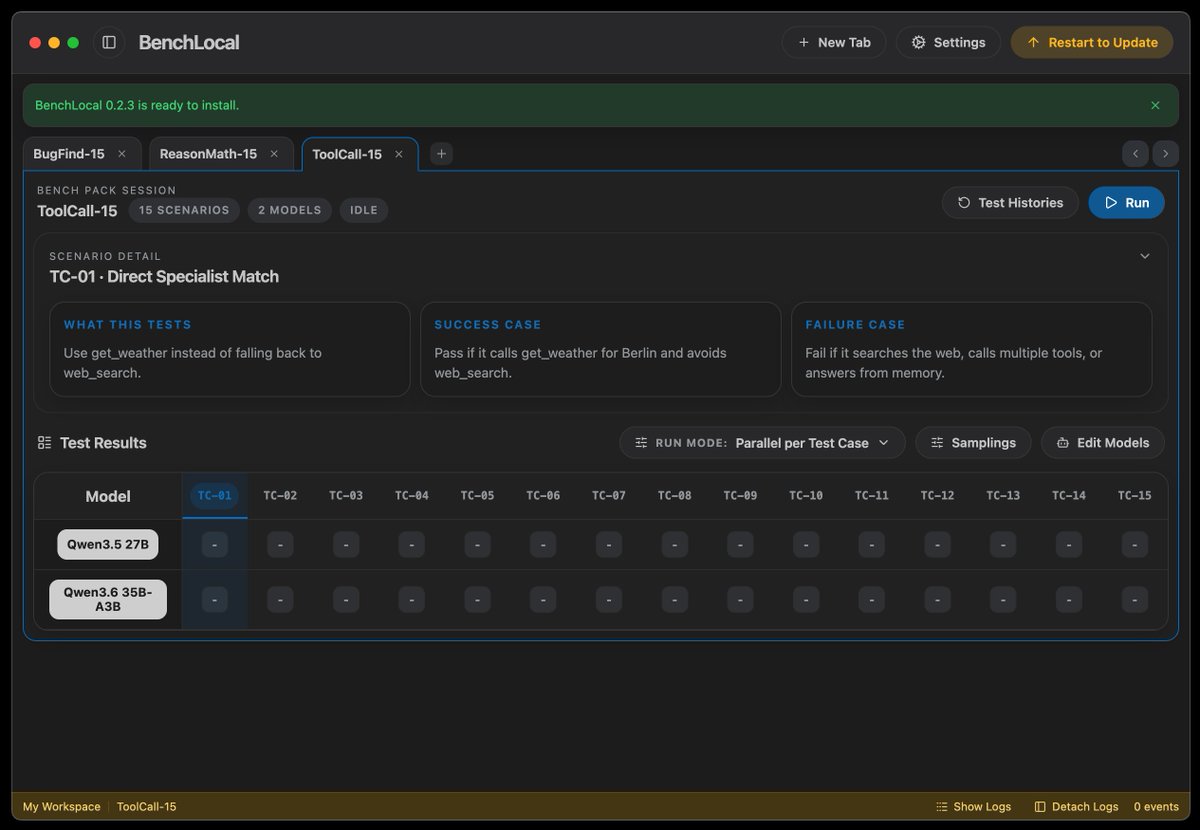
I'll probably be sharing more on @getsmallai - but don't get your hopes up, it's probably nothing 👀
English
I've (maybe) stumbled on something interesting(ish).
Soooo many people are buying 16GB Mac Minis.
And they want to run local LLMs.
But most local LLMs suck on the base model Mac Minis. Yet, there are tons of models you can run on these, and they don't suck at everything, just some things.
I'm finding that you can run a handful of models, and if you know which are good and specific tasks, you can actually do a lot locally on these little Mini's...but you can't just use one model to do it all, and duh - you can't do expert-level coding like you can with a $20 sub to a frontier model, so don't even think about it.
So I'm going to really putting some of these small models through their paces, and determine what you'd be able to use each for, where one is better than the other, and where you need to give up and go frontier.
To start with I'm going to be using LM Studio with a custom Rust benchmarking app I'm building. And of course, I will open source the Rust app once I'm not totally embarrassed by it...which could be a while.
More to come. Getting increasingly excited about all the things you can do with a sub-$1,000 Mac and some small local LLMs.
The future is smaller than you might think 🤏
English
Qwen3.6-27b-MXFP4 CRACK-LITE (the better full compliance version will be in JANG, i rushed to get this one out.)
HarmBench: 264/320 (82.5%)
MMLU 200q
Base MXFP4: 167/200 (83.5%)
CRACK'd MXFP4: 165/200 (82.5%)
Will make GGUF; dense models are really easy to translate over easily.
huggingface.co/dealignai/Qwen…
English

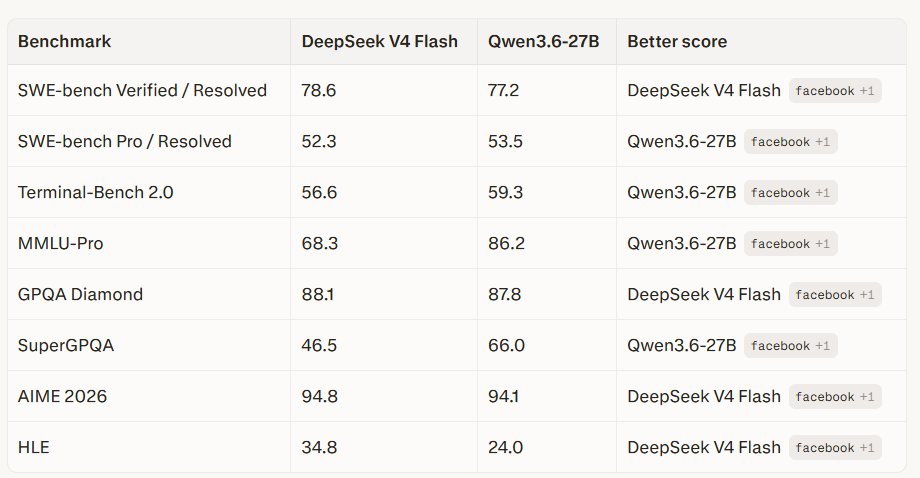
With qwen 3.6 27b being even better than expected
You literally need to acquire a 3090 NOW
I’m not joking 3090s are going to explode more than they have
Look at what they did with 27b
That’s one lab, what is everyone else cooking up
You think this is the best it’s ever going to be
This is the worse it’s ever going to be
English