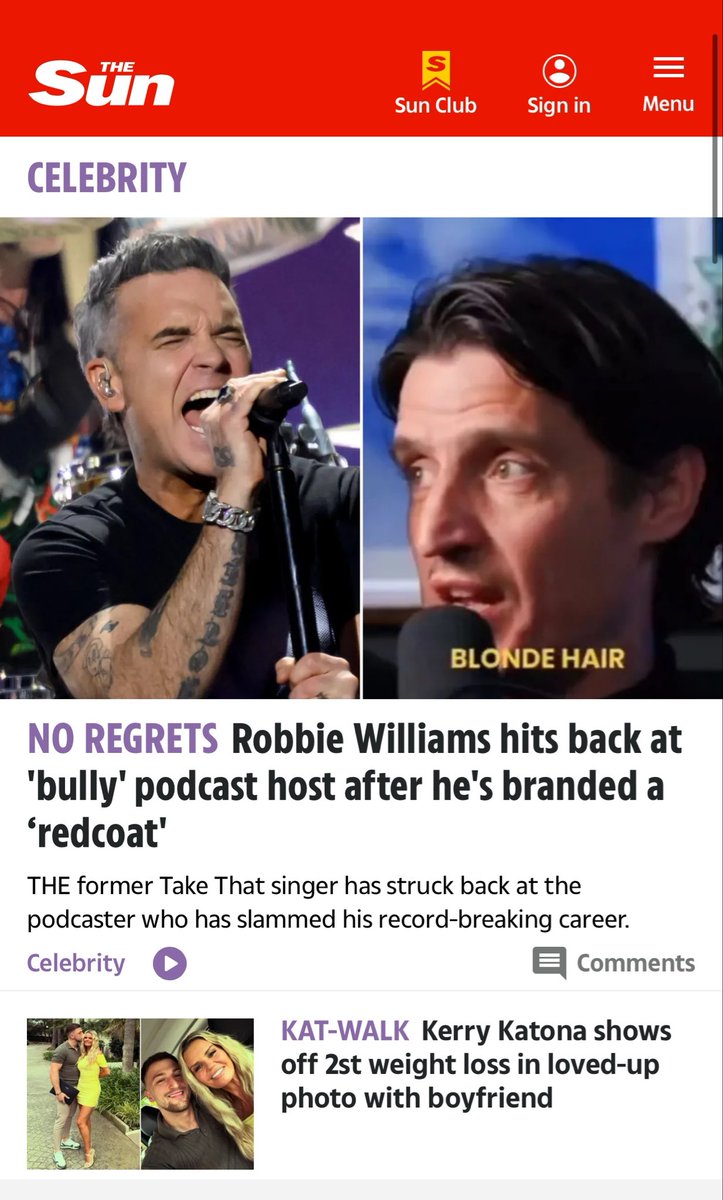
Sabitlenmiş Tweet

Counter-drone isn’t a niche. It’s the leading edge of an air-defense rebuild the West deferred for twenty years.
I put together a quick briefing document on some thoughts regarding the counter-drone (C-UAS) ecosystem.
New models are emerging at speed. Counter-drone-as-a-service is already live and private infrastructure providers and critical facilities are being given the legal authority to take direct responsibility for their own airspace defense. Download the pdf here: drive.google.com/file/d/1KBRWvQ…
#CUAS

English