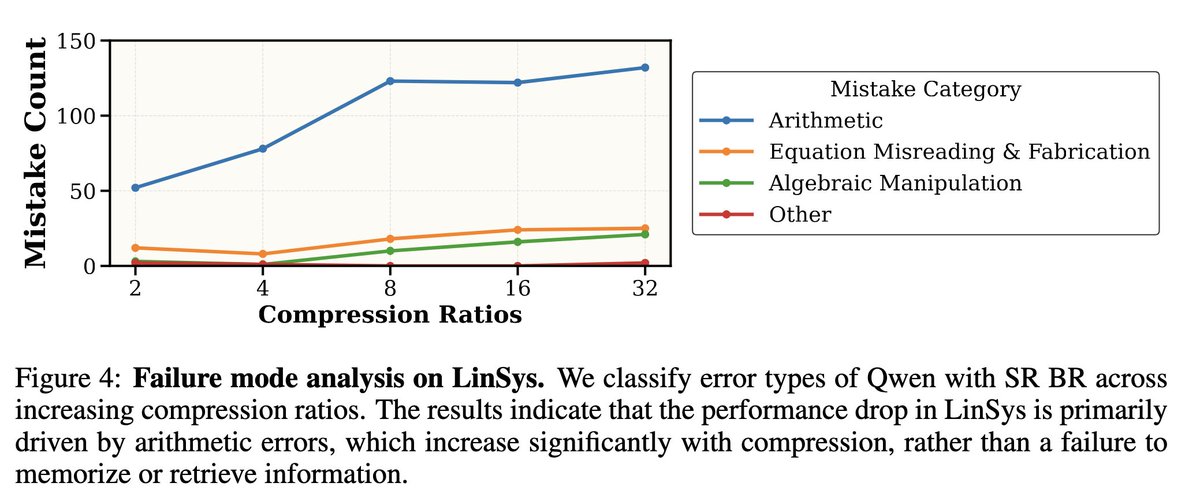
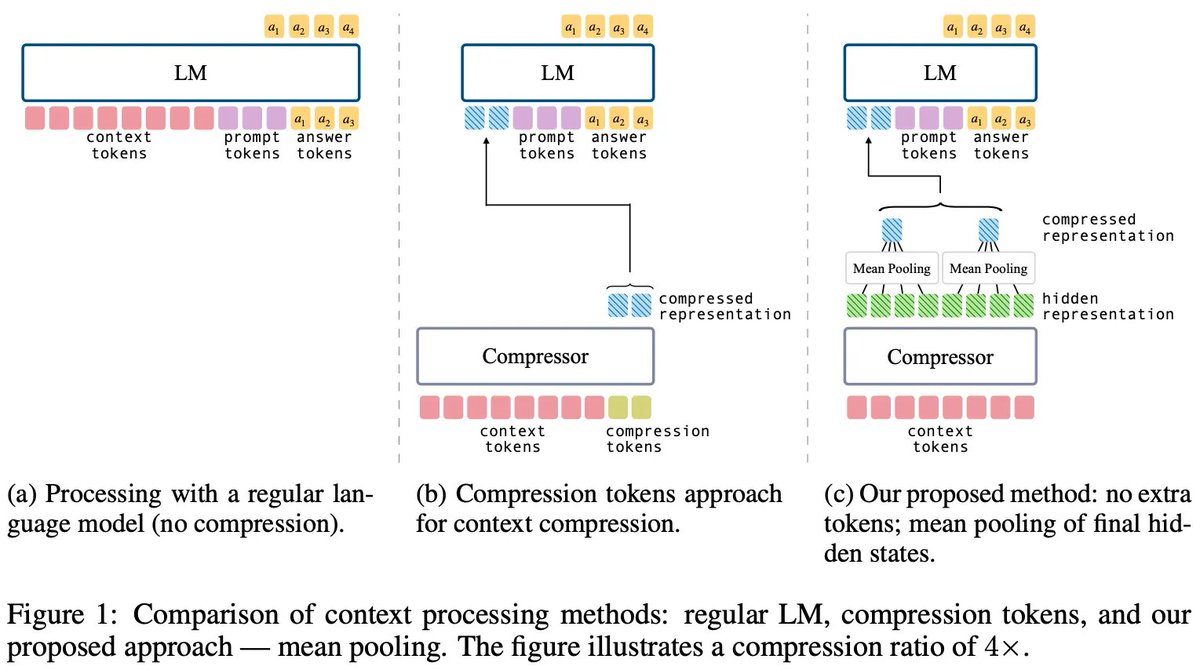
Long overdue thread, but better late than never. Grateful to my amazing co-authors for making this happen ( @yair_feldman @shankarpad8 @xkianteb @yoavartzi ) and to the great @nthngdy for feedback and support!
Check our paper on arxiv for more details: arxiv.org/abs/2510.13797
English