Sabitlenmiş Tweet

Kianté Brantley
2.6K posts
@xkianteb
Assistant Professor at Harvard University @KempnerInst and SEAS | Fitness enthusiast | (He/Him/His)




🚀 How can we make LLM-based optimization stable and scalable when the feedback signal is stochastic? Introducing POLCA: a framework for robust, scalable stochastic generative optimization. Paper: arxiv.org/abs/2603.14769 Code: github.com/rlx-lab/POLCA 🧵👇 1/






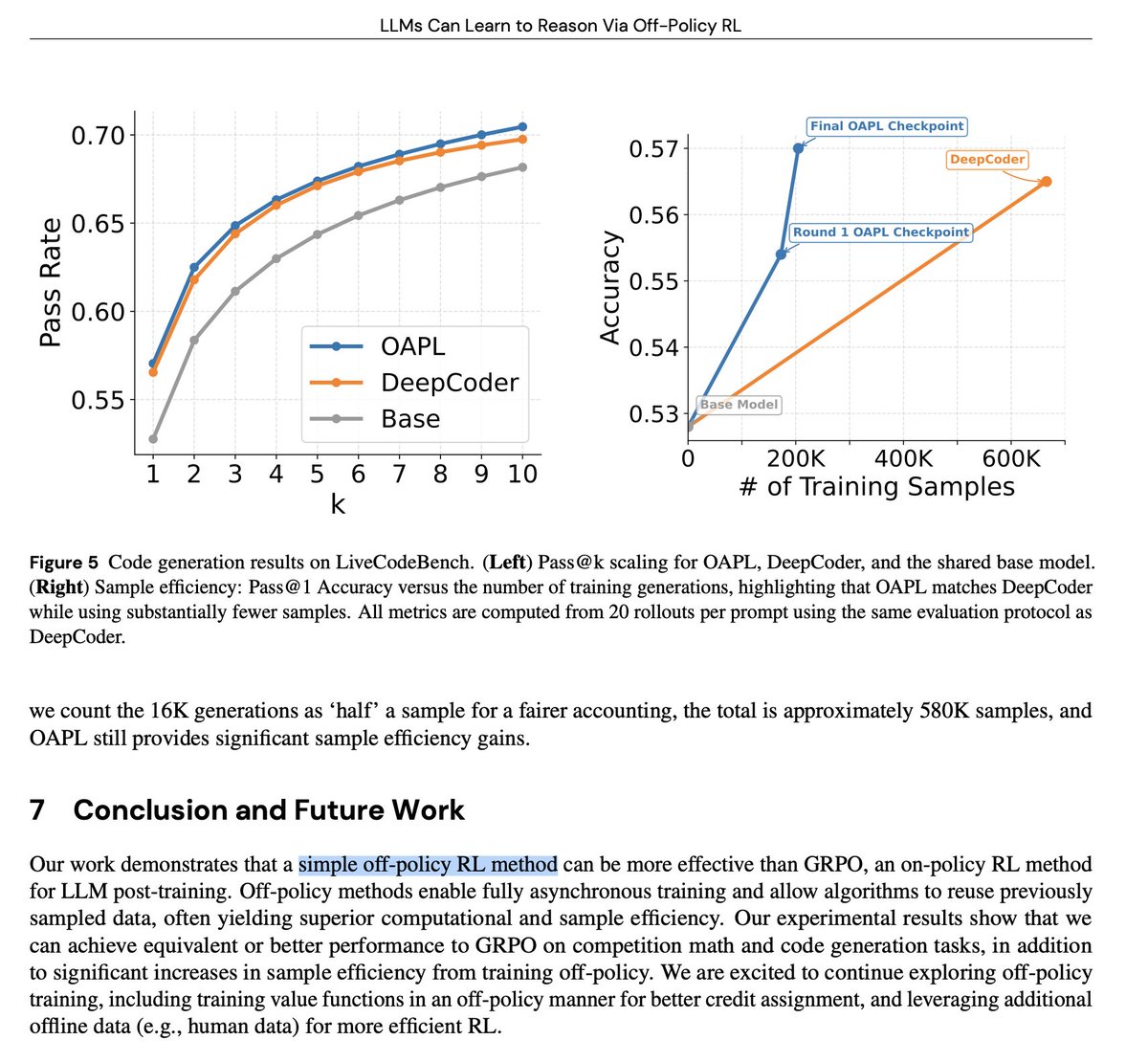
Does LLM RL post-training need to be on-policy?



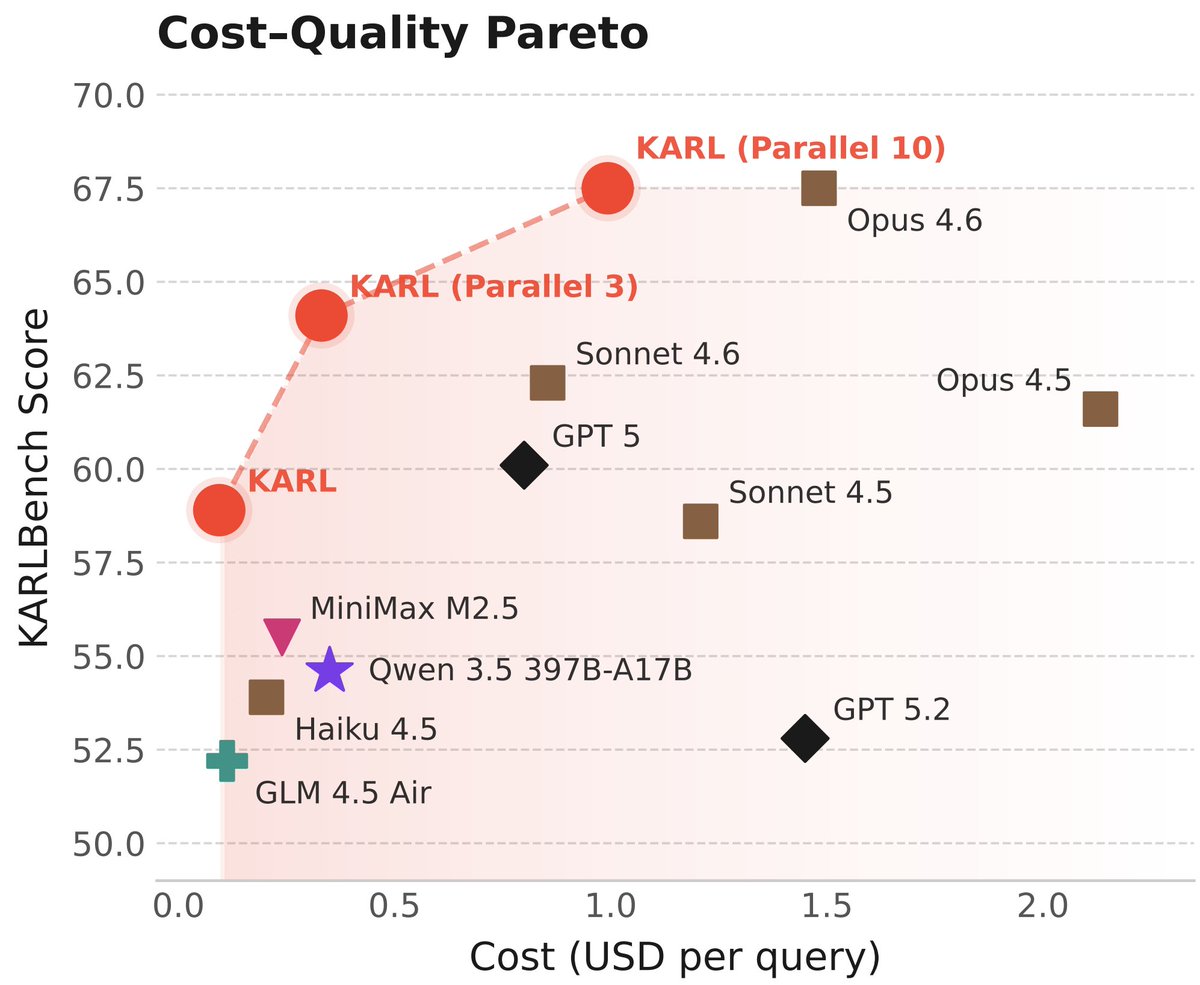
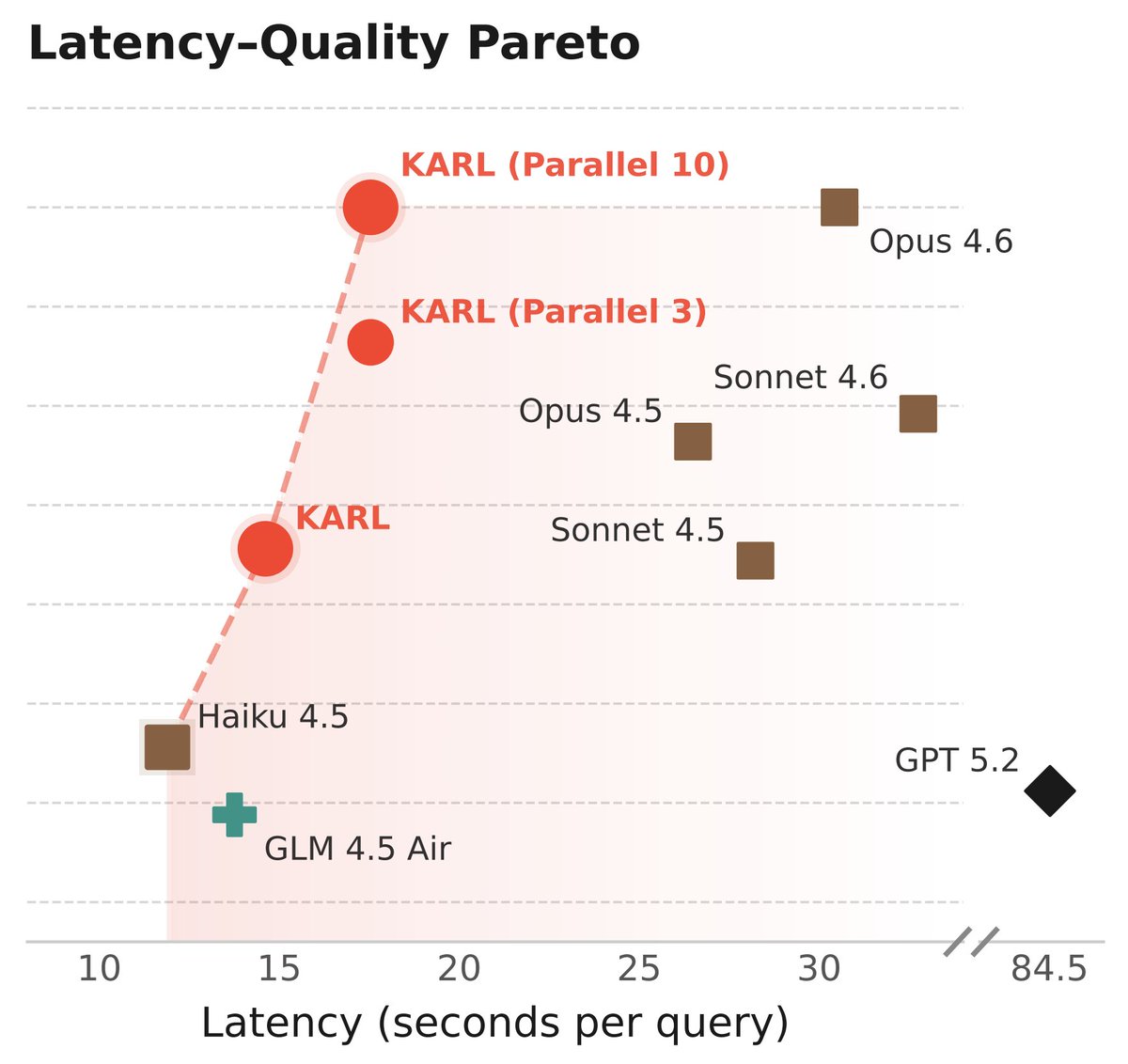
Meet KARL, an RL'd model for document-centric tasks at frontier quality and open source cost/speed. Great for @databricks customers and scientists (77-page tech report!) As usual, this isn't just one model - it's an RL assembly line to churn out models for us and our customers 🧵



Does LLM RL post-training need to be on-policy?

Does LLM RL post-training need to be on-policy?
tested and this works super well.. congrats @xkianteb!!

A reward model that works, zero-shot, across robots, tasks, and scenes? Introducing Robometer: Scaling general-purpose robotic reward models with 1M+ trajectories. Enables zero-shot: online/offline/model-based RL, data retrieval + IL, automatic failure detection, and more! 🧵 (1/12)
really fun project! you don't need to be on-policy to do RL! off-policy is just as good (and more sample efficient)!

Does LLM RL post-training need to be on-policy?