githubchy retweetledi

githubchy
769 posts


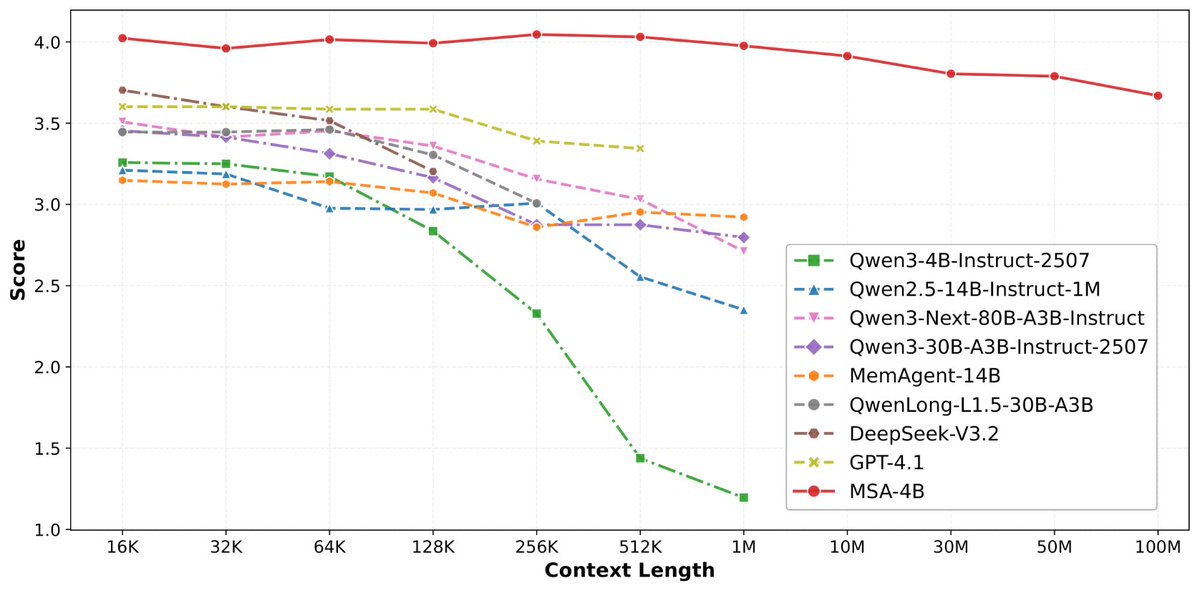
稍微剧透一下,@EverMind 这周还会发一篇高质量论文


Composer 2 is now available in Cursor.




发布啦!OpenWuKong v0.1 版本正式上线!🎉 官网下载: openwukong.app 前天逆向了阿里钉钉新推出的“悟空”,昨天就开始实现一个平替版本: - 快!底层Rust实现,启动迅速 - 小!mac版本只有不到20MB - 多模态支持!文本/图片多模态支持 - skills支持,浏览器自由操作,无限可能 当然目前只是一个最基础版本,未来还会持续更新,我们的PoorClaw穷虾🦞项目也会持续更新哒😘

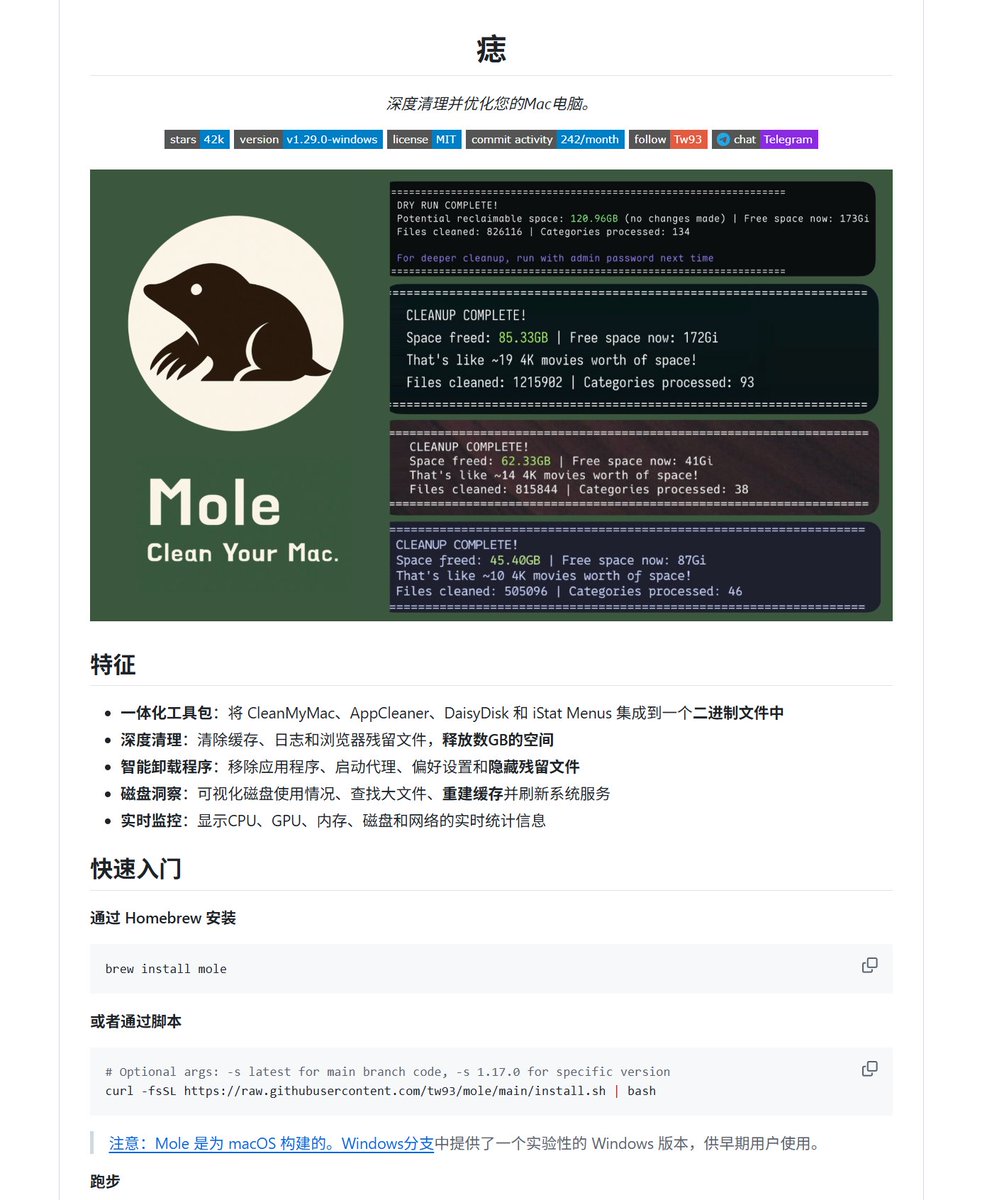





🚀全球内存疯狂涨价6倍的情况下,我们家懒猫微服16GB/32GB的机型依然没有涨价(之前囤了很多货),一条内存条价格就可以买一台微服了,CPU存储等于白送 🔥 16GB/32GB最后一批清仓货,良心低价出了,先到先得,感兴趣的大佬评论区打1