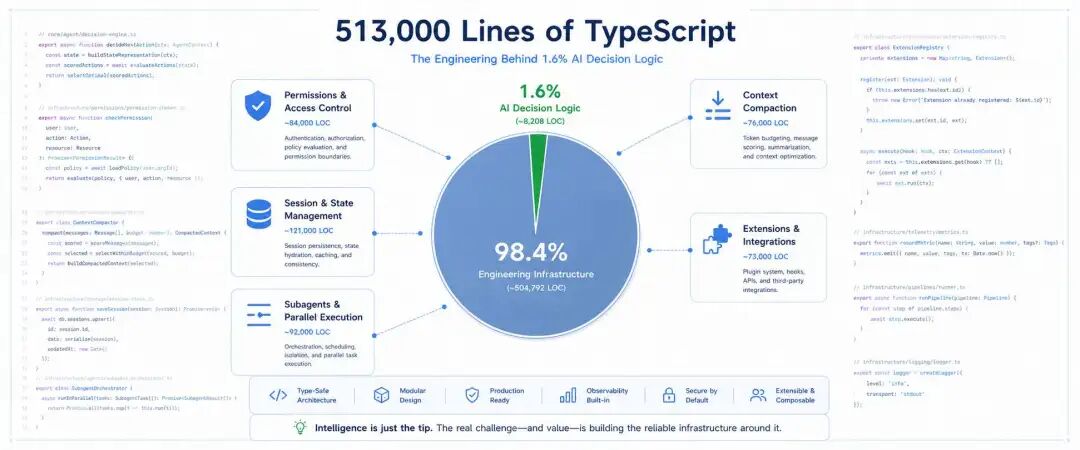
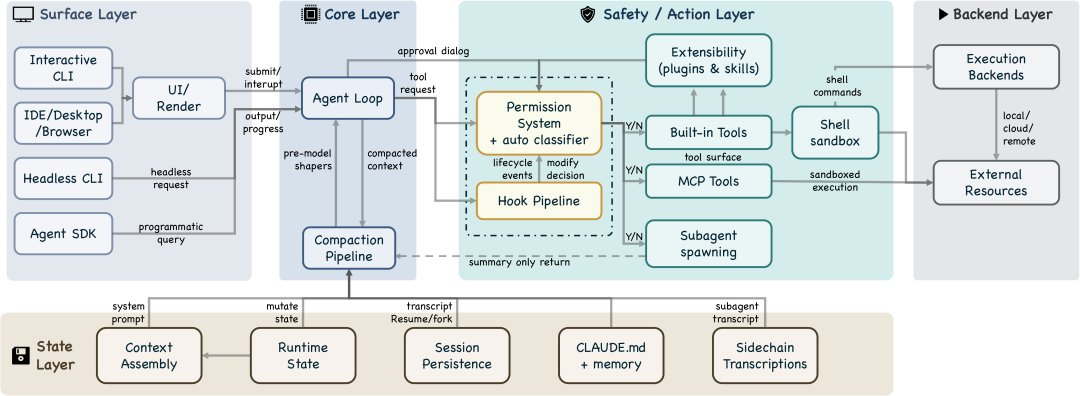
peter retweetledi

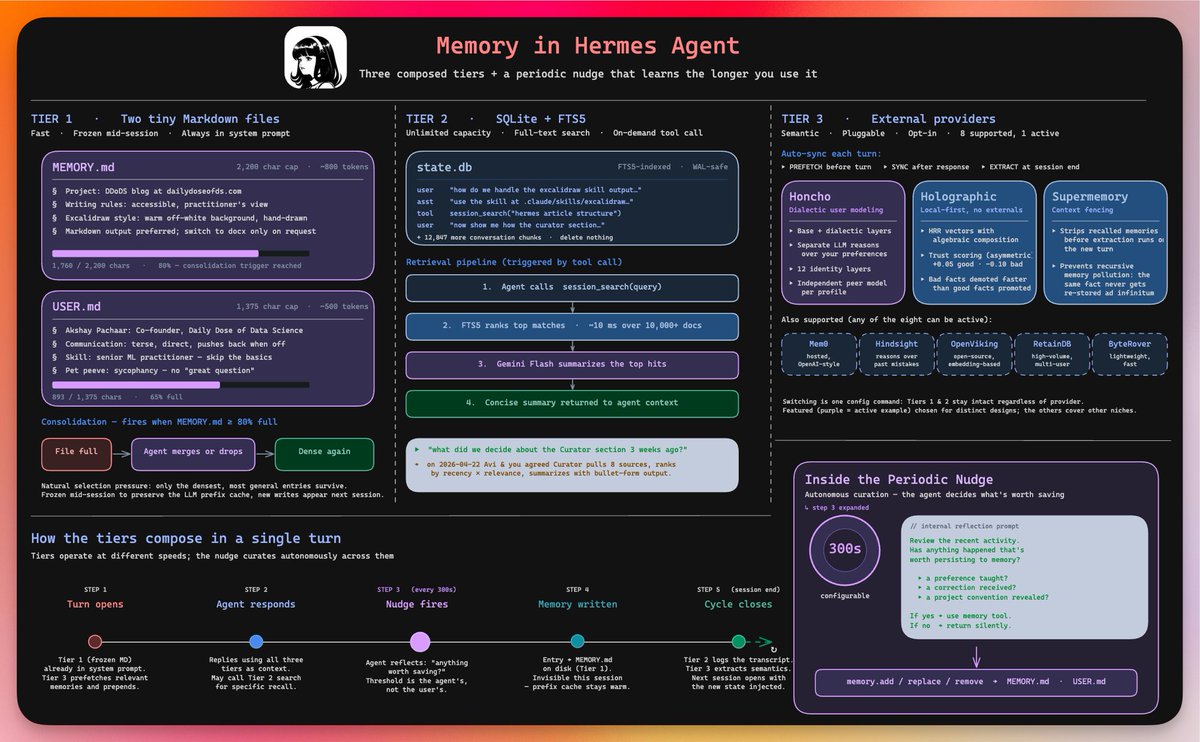
the three-tier memory of Hermes agent.
AI agents forgets everything when your session ends. Hermes doesn't.
it has three memory layers, each at a different speed.
𝘁𝗶𝗲𝗿 𝟭: 𝘁𝘄𝗼 𝘁𝗶𝗻𝘆 𝗺𝗮𝗿𝗸𝗱𝗼𝘄𝗻 𝗳𝗶𝗹𝗲𝘀
MEMORY.md (2,200 chars) and USER.md (1,375 chars). injected into the system prompt at session start as a frozen snapshot.
MEMORY.md holds project conventions, tool quirks, lessons learned. USER.md holds your profile: name, communication style, skill level.
these files are tiny on purpose. when MEMORY.md hits ~80% capacity, the agent consolidates: merges related entries, drops redundancy, keeps only the densest facts.
natural selection pressure applied to memory. the files stay small, but what's inside gets sharper over time.
𝘁𝗶𝗲𝗿 𝟮: 𝗳𝘂𝗹𝗹-𝘁𝗲𝘅𝘁 𝘀𝗲𝘀𝘀𝗶𝗼𝗻 𝘀𝗲𝗮𝗿𝗰𝗵 (𝘀𝗾𝗹𝗶𝘁𝗲 + 𝗳𝘁𝘀𝟱)
every conversation gets stored in SQLite with FTS5 indexing. the agent can search weeks of past sessions on demand.
when the agent calls session_search: FTS5 ranks matches in ~10ms over 10,000+ docs, an LLM summarizes the top hits, and a concise result returns to context.
tier 1 is always present but tiny. tier 2 has unlimited capacity but requires an active search. critical facts live in memory, everything else is searchable.
𝘁𝗶𝗲𝗿 𝟯: 𝗲𝘅𝘁𝗲𝗿𝗻𝗮𝗹 𝗺𝗲𝗺𝗼𝗿𝘆 𝗽𝗿𝗼𝘃𝗶𝗱𝗲𝗿𝘀
8 pluggable providers that run alongside tiers 1 and 2, never replacing them. three worth knowing: Honcho (dialectic user modeling, 12 identity layers), Holographic (local-first, HRR vectors, no external calls), and Supermemory (context fencing that prevents the same fact from being re-stored infinitely).
when active, hermes auto-syncs every turn: prefetch before, sync after, extract at session end.
𝗵𝗼𝘄 𝘁𝗵𝗲𝘆 𝗰𝗼𝗺𝗽𝗼𝘀𝗲 𝗶𝗻 𝗮 𝘀𝗶𝗻𝗴𝗹𝗲 𝘁𝘂𝗿𝗻
this is the part most people miss. the tiers compose on every turn through a five-step cycle:
1. turn opens. tier 1 is already in prompt, tier 3 prefetches and prepends.
2. agent responds using all three tiers as context.
3. periodic nudge fires (~every 300s). the agent reflects: "has anything worth persisting happened?" if yes, it writes. if no, it returns silently.
4. memory written to MEMORY.md on disk. invisible this session because the prefix cache stays warm.
5. session closes. tier 2 logs the transcript, tier 3 extracts semantics. next session opens with the new state.
agent memory today is either always-on but shallow (stuff everything in the prompt) or deep but passive (vector store that never fires at the right time).
hermes composes across both: tiny always-present files for critical facts, full-text search for deep recall, external providers for semantic modeling, all orchestrated by a nudge that decides autonomously what's worth saving.
the agent doesn't just store memories. it curates them under pressure.
i wrote a full deep dive (article below) covering hermes agent's memory system, self-evolving skills, GEPA optimization, and how to set up multiple specialized agents on your machine.
Akshay 🚀@akshay_pachaar
English