LISA@MindOS_Lisa·5h@goodhunt The vast majority of users who use DeepSeek are good people😉Çevir English003281
Jaden思考日志@Jaden_riku·6h@MindOS_Lisa x.com/Jaden_riku/sta… Reddit真的是被低估了,在这个AI时代ÇevirJaden思考日志@Jaden_riku一张图讲清楚:Reddit在AI时代的到底有多重要 中文101223
Roland.W@rwayne·6h我确实是第一次看到讲在Reddit上面去挖掘需求的 这个文章值得被更多人看见,写得特别特别的好 第一次看到非技术背景的女性用户写出这么高质量的文章,太厉害了👍ÇevirLISA@MindOS_Lisax.com/i/article/2050… 中文1116017.3K121
LISA@MindOS_Lisa·7h涉及与物理世界人类交互、独特性强的事情人类做得也不开心☹️Çevirindigo@indigoxStanford 用 1500 个工人和 844 个任务告诉 YC:你们 41% 的钱投错了方向 —— 你们投的都是"人们不想要"或"不需要"的东西,而那些"想要但没什么人做"的事正在等待 founders。论文中工人最想自动化的前 10 个职业 Claude 的使用量只有 1.26%,现有 AI 使用反映的是早期采用者偏好,不是真实工作场所需求! WORKBank 把工作任务划分成了四个象限,高渴望和高能力分别表示对 AI 高需求和 AI 目前的能力: 🟢 Green Light(高渴望 + 高能力) 这一象限聚集的工作类型:数据录入 / 文件整理 / 日程安排 / 例行报告生成 / 标准化客服流程 / 重复性信息检索整合(QA、合规类) 🟠 R&D Opportunity(高渴望 + 低能力) 这一象限聚集的工作类型:跨系统协调(涉及多个工具/部门但仍结构化)/ 长上下文研究 + 综合分析 / 项目计划和资源分配 / 中等复杂度的创意设计 这正是创业公司应该看的方向——工人想要 AI 帮忙,但当前 AI 能力还没到位。 🔴 Red Light(低渴望 + 高能力) 这一象限聚集的工作类型:内容创作的最终呈现(艺术/设计/媒体红灯比例 47.6% 全行业最高)/ 客户面对面的关系类(销售/法律咨询/客户管理)/ 决策的"署名"环节(草稿可以 AI 写但谁署名 = 谁负责)/ 创意的灵感判断("这个 ok / 不 ok"的最终拍板) 特征:技术上 AI 能做,但做的人在乎自己的 ownership / 创造性 / 客户关系——这是最容易引发劳动法纠纷和文化抵制的区域。中国法院的两个判例(Zhou 在 QA / Liu 做地图录入)就涉及这一区。 ⚪ Low Priority(低渴望 + 低能力) 这一象限聚集的工作类型:高度物理 / 跨系统手动追踪(电话、纸质文件、人工对接)/ 高度地方化、低标准化(每个城市/机场/银行流程都不同)/ 长尾的客户异常处理 / 受监管约束极强的小批量任务 特征:双低 = 不必做。论文也指出,这些任务人类做得也不开心(已经被流程化得很惨),只是 AI 现阶段也帮不上忙。 最被忽视的发现:同一职业内的不同任务往往横跨多个象限。最典型的例子 - 程序员: - "重构同一模式代码" → 🟢 - "理解模糊的用户需求" → 🟠 - "在客户面前展示 demo 并应对质询" → 🔴 - "在老旧 COBOL 代码里追一个偶发 bug" → ⚪ 这意味着"程序员被 AI 替代"可能是一个伪命题。程序员的某些任务在绿灯区(已被 Claude Code 大量自动化),某些在红灯区(客户沟通、责任归属),某些在 R&D 区(AI 还做不到的复杂理解)。 这也是 Diana / Cat Wu 描述的"PM 与工程师角色融合"在数据上的解释——工作不是被替代,是被重新切分到四个象限里🤔 中文001455
LISA@MindOS_Lisa·20h💡Tips:用AI写简单小程序prompt的三个要素 1️⃣ 目标:app的具体作用 2️⃣ 输入:用户输入的内容 3️⃣ 输出:app输出的内容 learn.deeplearning.ai/courses/ai-pro…Çevir 中文001168
LISA@MindOS_Lisa·20h扩散模型生成图片的过程,几分钟的课程把会讲到底层技术,从根本理解还是有用的 learn.deeplearning.ai/courses/ai-pro…Çevir 中文000105
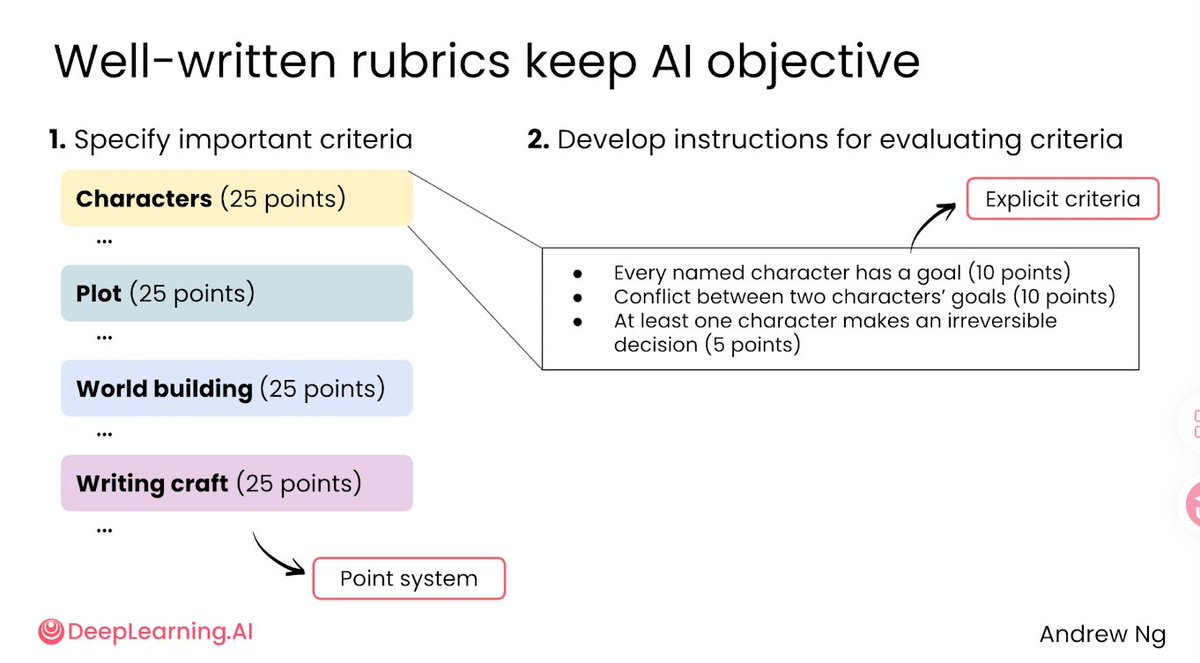
LISA@MindOS_Lisa·21h💡Tips: AI写修正长文的Tips 1️⃣ 按照每一段落确认内容 2️⃣ 修正标准需要把维度分清楚,并且每个维度需要有具体评分细则 3️⃣ 不同大模型的能力范围不一样,可以跨模型修正标准的完整性 learn.deeplearning.ai/courses/ai-pro…Çevir 中文000122
LISA@MindOS_Lisa·22h💡Tips: 避免AI写作很AI味的方法 1️⃣ 充分背景的prompt+补充文件生成3个大纲outline 2️⃣ 选择一个合适的大纲,调整要表达的要点bullet point 3️⃣ 根据调整后的大纲生成全文full textÇevir 中文101142
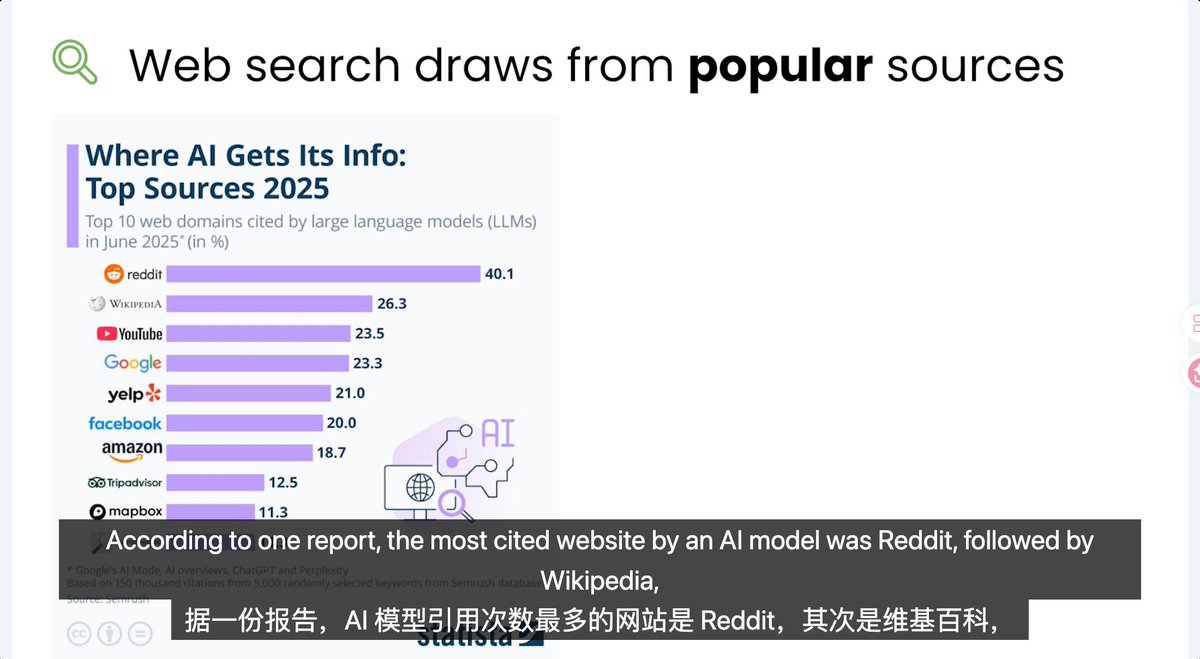
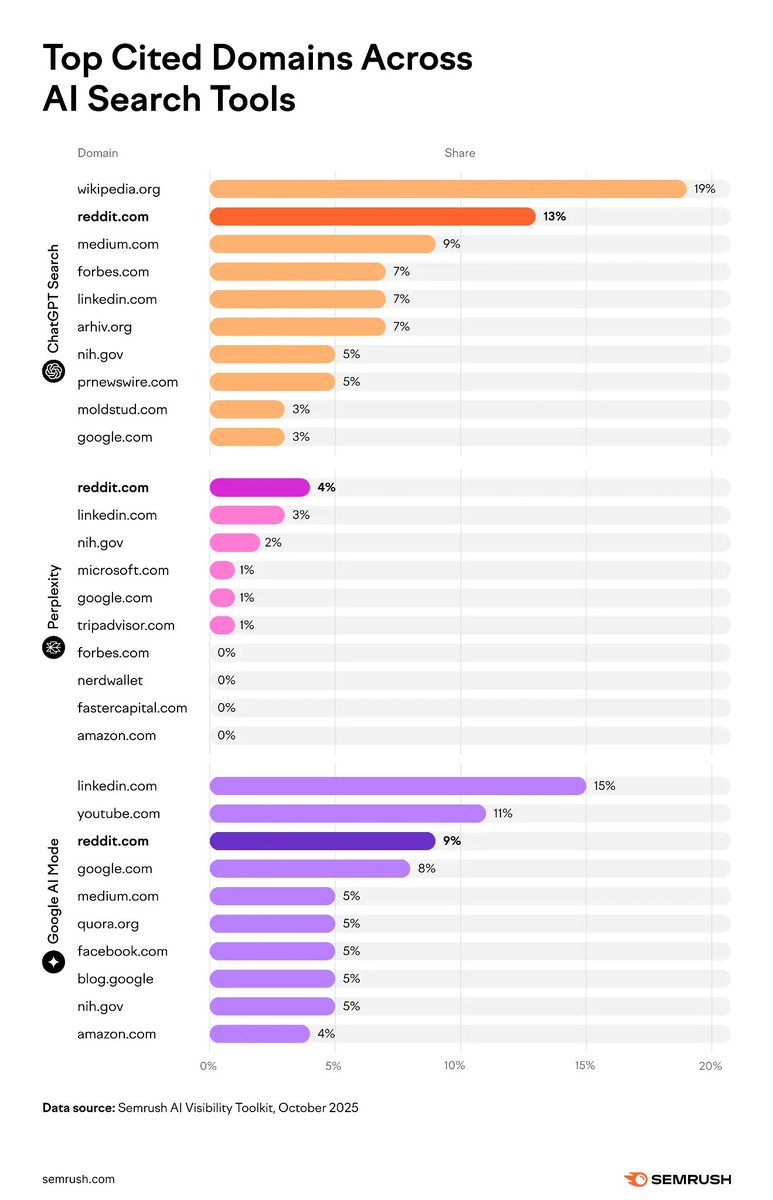
LISA@MindOS_Lisa·23h@yangyi 这个数据好像是25年6月semrush的数据,在刚发的吴恩达教授的课上截的图。quora的数据引用量也挺大的。但是风格跟Reddit完全不一样了。Çevir 中文100230