
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡)
6.4K posts

𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡)
@gonzaloserrano
≡𝐺𝑂pher at @TigerDatabase 🐯 @Bcn_Eng community founder 👥Cooking lover 👨🍳 Metalhead 🤘 Amateur tennis and padel player 🎾
Sóller, Mallorca, Spain Katılım Aralık 2009
1.3K Takip Edilen1.1K Takipçiler
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡) retweetledi

Claude EM: Tu compañero Engineering Manager AI-powered sobre Claude.
github.com/jcesarperez/cl…
Feedback bienvenido! Ayúdame a mejorarlo
Español
@bcherny I think it was renamed to /less-permission-prompts ?
English

2/ The new /fewer-permission-prompts skill
We've also released a new /fewer-permission-prompts skill. It scans through your session history to find common bash and MCP commands that are safe but caused repeated permission prompts.
It then recommends a list of commands to add to your permissions allowlist.
Use this to tune up your permissions and avoid unnecessary permission prompts, especially if you don't use auto mode.
code.claude.com/docs/en/permis…
English
Dogfooding Opus 4.7 the last few weeks, I've been feeling incredibly productive. Sharing a few tips to get more out of 4.7 🧵
English

👋 I'm the PM on GitHub's Maintainer Love team, and we're focused on making your life easier.
If you could wave a magic wand, what is the #1 feature you'd want us to ship? No idea is too tiny - the smallest changes often have the biggest impact.
Drop your wishes below. 👇
English
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡) retweetledi

🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: dropbox.com/scl/fi/f5luli8… Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
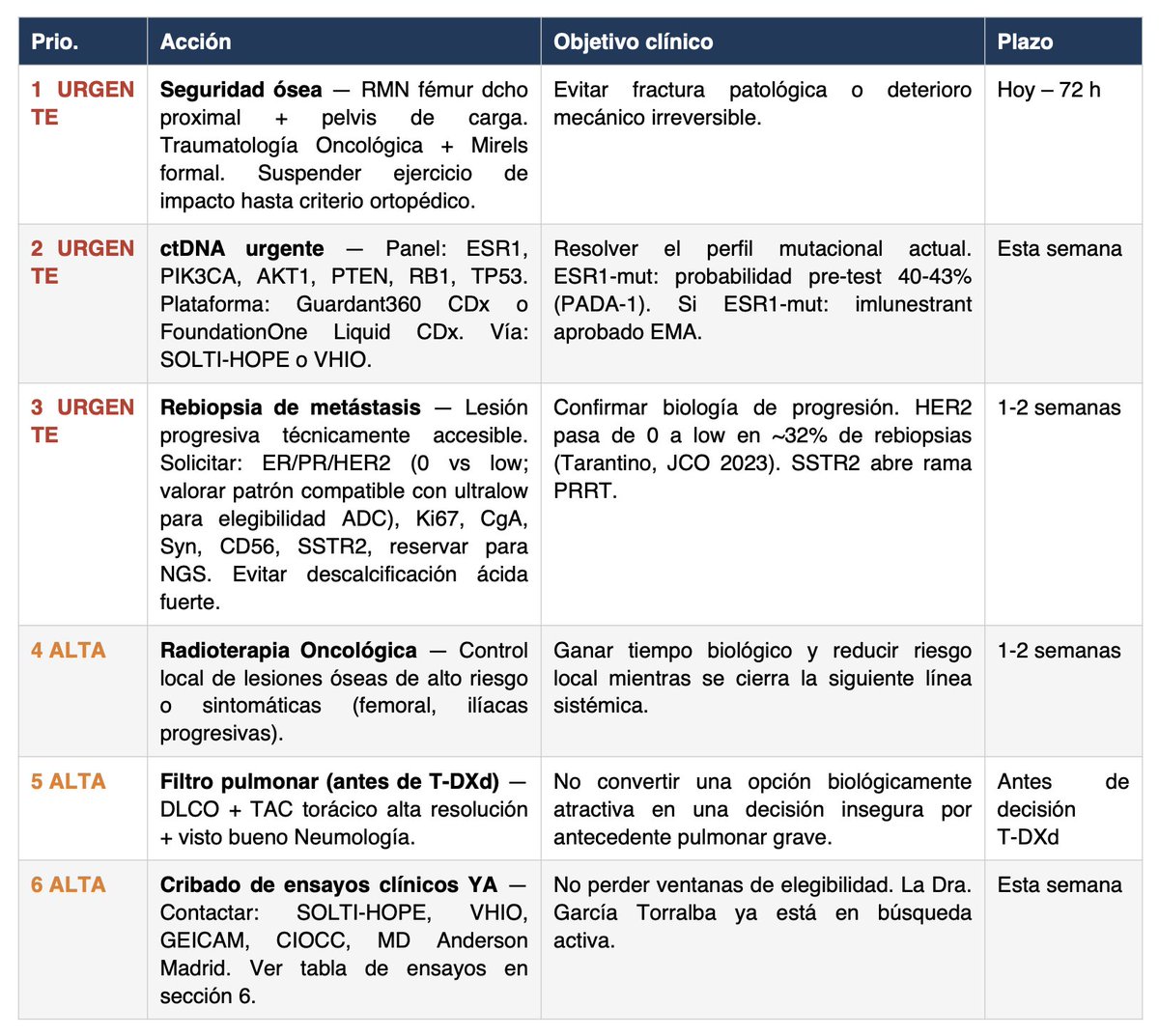

Español
@elwatto Hah I almost emailed you after I was rejected 🫣
No hard feelings though, landed in a great place to work.
Hiring well is very hard. Been there done that.
English

We once interviewed an engineer who did well technically. But I said no. The attitude was really off, entitlement through the roof. They sent a hate email after rejection. We dodged a bullet.
Three years later, they’ve been at four different companies. Listen to your gut.
English
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡) retweetledi

TIL from Claude: I spend too much money at REI (and way too much on Uber Eats).
ghost.build
@ghostdotbuild
English

@iamkevinkrieg a Stream Deck can help github.com/gonzaloserrano…
English



Cambios importantes que ya estamos teniendo en CoverManager con Claude Code:
> /deep-review hotfix/CPD-444
> /hotpatch api.php prod
> /bitbucket create-pr
> /newrelic errors last deploye
> /infra manage prod scale up
English
@michaelfreedman Did you install github.com/anthropics/ski… ?
English

Just asked to Claude review its own skills file for clarity, correctness, completeness, and conciseness.
Good plan. No appreciation for my poetry.
English
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡) retweetledi
Introducing TigerFS - a filesystem backed by PostgreSQL, and a filesystem interface to PostgreSQL.
Idea is simple: Agents don't need fancy APIs or SDKs, they love the file system. ls, cat, find, grep. Pipelined UNIX tools. So let’s make files transactional and concurrent by backing them with a real database.
There are two ways to use it:
File-first: Write markdown, organize into directories. Writes are atomic, everything is auto-versioned. Any tool that works with files -- Claude Code, Cursor, grep, emacs -- just works. Multi-agent task coordination is just mv'ing files between todo/doing/done directories.
Data-first: Mount any Postgres database and explore it with Unix tools. For large databases, chain filters into paths that push down to SQL: .by/customer_id/123/.order/created_at/.last/10/.export/json. Bulk import/export, no SQL needed, and ships with Claude Code skills.
Every file is a real PostgreSQL row. Multiple agents and humans read and write concurrently with full ACID guarantees. The filesystem /is/ the API.
Mounts via FUSE on Linux and NFS on macOS, no extra dependencies. Point it at an existing Postgres database, or spin up a free one on Tiger Cloud or Ghost.
I built this mostly for agent workflows, but curious what else people would use it for. It's early but the core is solid. Feedback welcome.
tigerfs.io
English
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡) retweetledi
"The filesystem is the API."
A filesystem backed by PostgreSQL, and a filesystem interface to PostgreSQL.
tigerfs.io
English
@sdepablos Inglés excepto cuando voy muy de culo y lo que quiero expresar con mi ingles no es preciso. Pero cuando cambie a usar /voice en Claude creo que lo haré en español.
Español

Vosotros en qué idioma le habláis a las AIs? Yo por deformación profesional en inglés el 99% del tiempo
Español
@juanmacias Y si le pones un StreamDeck, mejor github.com/gonzaloserrano… 😎
Español
Si no estás usando cmux.dev en Mac para trabajar con claude, estás perdiendo el tiempo
Español
@trq212 does Claude's GH App integration for code reviews allow referencing 3rd party plugins as CC does?
English
𝗴𝗼 𝚗𝚣𝚊𝚕𝚘(𝚌𝚝𝚡) retweetledi
AI didn't kill software moats. It shifted them.
This is something I have been thinking about a lot lately.
Finally found the time this morning to write down a framework for how to think about durable advantages in the age of AI.
(Also, I may or may not have a board meeting coming up this week...)
Ajay Kulkarni@acoustik
English
@gimenete It takes literally 5 minutes and any frontier model that’s at least 4-month old to figure it out.
English

People saying AI is not there yet for generating code are probably those that spent years discussing tabs vs spaces, linting rules, number of lines in a function and called their naming conventions “software architecture”
English