
Groovin’
180 posts

Groovin’
@gr00v1n
Consistency achieves what inspiration cannot.
Katılım Ocak 2022
174 Takip Edilen10 Takipçiler

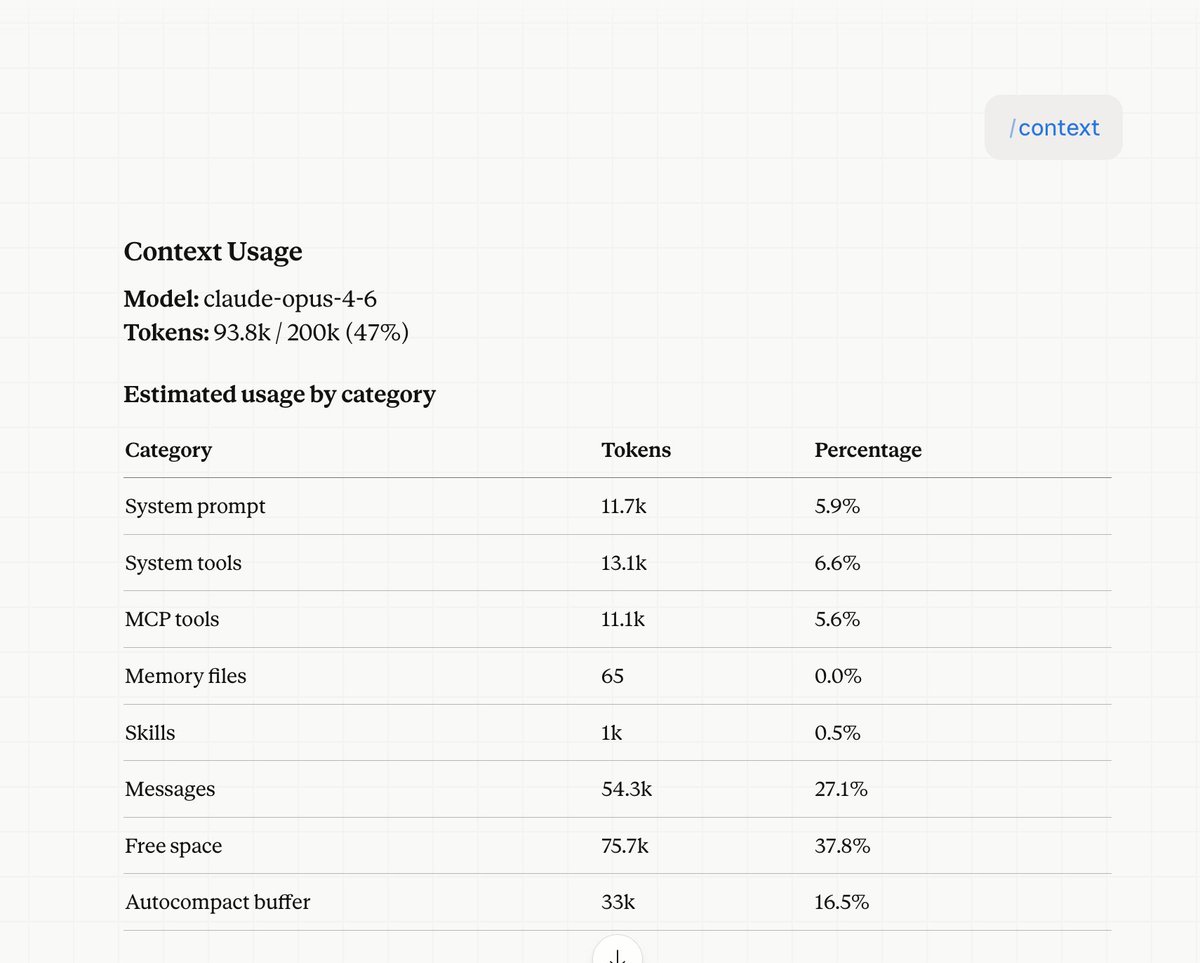
不懂就别发言,至少你自己也要去求证一下ai的发言。。。AI会忽悠人。。。
不过以下也是我的推测:
首先僵尸节点10-100Mbps?现在家用的普遍都是200往上(平均数据在553.4 Mbps/户),一线城市都大范围铺开千兆了。
其次,超算中心的客户群体将近6k家(20年的数据,现在只会更多),而且基本都是企业、国家级客户,如果僵尸节点更多的应该分布于这些客户里(我是攻击者我就会这么做),那就更好做伪装了(别以为企业的安全性很都很高),本身就是高吞吐、大文件、远程任务、多业务并存的网络环境,如果再加上有些线路走的可能是内部专线等不会做额外检测,那只会更快。
最后这次问题:要么这个攻击者根本不是一个人,是一个团队;要么就是超算中心内部管理有问题;要么这个就是假的。这三种可能性都很强。
中文

@morgansmithAu @19890604Jimmy @sfc701559 @whyyoutouzhele 当然我不懂这些,只是看AI分析的,AI的解释是:
僵尸网络(botnet)通常用于分布式攻击(如DDoS)或代理流量,但用于数据窃取的效率低:
每个僵尸节点带宽有限(多为家用宽带,10-100Mbps)。
需协调数万节点才能达到Gbps级别带宽,管理复杂。
易被追踪:大规模异常流量会触发ISP或安全机构警报。
中文

4月8日,公视新闻网报道: 中国超级电脑疑遭黑客入侵1万TB数据,CNN:初步评估泄露属实
据CNN报道,社交软件Telegram自2月起出现一个自称「FlamingChina」的黑客团体,兜售从中国超级计算机窃取的数据,价格从数千至数十万美元不等,内容涵盖航天工程、军事、生物信息学、核聚变模拟等多个领域。CNN表示,经多位专家评估后,初步认为泄露事件属实,且规模达10PB,即1万TB,可能是中国史上已知最大规模的数据泄露事件。
CNN报道,一个自称「FlamingChina」的黑客团体,自2月6日起在Telegram匿名频道中兜售号称从中国「国家超级计算天津中心」窃取的数据,并释出部分标注为「机密」的中文文件、技术档案,以及炸弹与导弹等国防装备的动画模拟作为佐证。
报道称,2009年启用的「国家超级计算天津中心」是中国首个国家级计算中心,为先进科研机构与国防部门等超过6000个客户提供服务。
该黑客团体声称,其掌握的数据涉及中国航空工业集团、中国商用飞机公司、中国人民解放军国防科技大学等多个中国顶尖机构,涵盖航天工程、军事、生物信息学、核聚变模拟等多个领域的研究成果,售价从数千至数十万美元不等。
CNN表示,尽管尚无法完全核实「FlamingChina」的说法及数据来源,但在多位专家评估后,初步认为数据泄露属实,且规模可能达到10PB,即1万TB,或为中国已知最大规模的数据泄露事件。
「你会使用超算中心来处理大型计算任务,而这些数据正是我预期会在这里看到的内容。」网络安全公司SentinelOne顾问凯瑞(Dakota Cary)表示,大多数客户没有理由自行维护超级计算机,而黑客提供的样本文件确实反映出该中心客户的多样性。
该黑客团体称,其通过破解VPN进入天津中心,并利用僵尸网络(botnet)耗时6个月逐步提取和下载数据。
凯瑞认为,这种数据窃取方式与其说是技术高超,不如说是利用了超算系统架构的特点。通常情况下,大量数据集中流向某一地点会被系统发现,但如果通过多台服务器分散、逐步传输,就更难被监测到。
网络安全研究员霍弗(Marc Hofer)表示,此次泄露的数据规模极为庞大,对敌对国家的情报机构而言可能具有很高价值,「只有他们才有能力处理如此规模的数据,并从中提取有用信息。」
不过凯瑞也指出,可能有许多国家政府对天津中心的数据感兴趣,「但也许他们早已掌握相关数据。」他还提到,中国长期以来网络安全状况并不理想,这一点甚至得到官方承认,并已将「建立网络、数据和AI领域的坚固安全屏障」列为2025年国防白皮书的重点任务之一。

李老师不是你老师@whyyoutouzhele
网传中国国家超算中心疑遭数据泄露 官方尚未回应 近日,网络流传消息称,位于天津的国家超级计算天津中心疑似发生重大数据安全事件。 据称,一名黑客在知名黑客论坛“Breach Forums”发帖,声称已获取该中心超过10PB的核心科研数据,并以加密货币门罗币标价出售。 相关说法称,数据涉及航空航天、国防科研及生物医学等多个敏感领域。 公开资料显示,该中心部署过“天河一号”等高性能计算系统,服务范围覆盖全国多个科研机构和企业,是重要的国家级算力基础设施。 此外,有消息称部分所谓“样本数据”曾短暂出现在开源平台,但相关内容随后被删除。目前,上述信息尚未得到权威机构证实,其真实性仍有待核实。 截至发稿时,相关主管部门及该超算中心尚未就此事发布正式回应。
中文


Today, we’re excited to announce that the AI Tutor feature is officially out of public beta!
In the latest version, we’ve granted 1,000 AI Tutor credits to all Pro, Premium, and PremiumPlus subscribers. These credits will allow you to start a new course and complete a few lessons, giving you a taste of how AI Tutor can transform the way you learn in the AI era. Please note that these credits will **expire** on April 22, 2026, so you have about two weeks to try it out and let us know what you think!
Once you run out of your granted credits, if you want to use AI Tutor more but don’t necessarily need everything included in the Premium plan (unlimited basic AI chats and PDF parsing) or the PremiumPlus plan (a 33% discount on all AI credits), you can enable on-demand usage and set a monthly spending limit.
Finally, we want to share a bit more about the product direction we’re heading toward. From the very beginning, Heptabase has been a company dedicated to inventing the best way to learn and do research. In the AI era, where AI possesses more knowledge than any human in history, we see a clear path to upgrading Heptabase into a service that can help you achieve any learning and research goal:
- We, as humans, should spend most of our time reading, thinking, asking, practicing, and making the decisions that truly matter to us.
- AI agents, on the other hand, should spend most of their time teaching us, guiding our research, organizing our knowledge bases, executing our tasks, and solving our problems at scale.
To achieve this, we currently have two major tracks in our product roadmap:
- The first track is to continuously improve the reading, thinking, and practicing experience for human (e.g., an upgraded mobile PDF reader, web annotation, EPUB reader, handwriting support, better whiteboards, flashcards, etc.). We also want to ensure that all this knowledge and understanding can translate into the important decisions you make in your life and career.
- The second track focuses on building powerful AI agents with long-term memory. These agents will understand the best way to teach you, guide your direction in your learning and research, find and read high-quality sources, and take notes to organize in your knowledge base. They will even be able to run code, conduct experiments, and transform their findings into written content, explainer audios and videos, and interactive web cards.
We believe both tracks are equally important, and we are investing heavily in them. We’ll spend more time writing about this in the coming months, but in the meantime, we encourage you to try out AI Tutor and let me know what you think!
English
@Outman_ttt @m0d8ye 有的我的Claude code就是按照进程分流,macos上的surge写规则比ios方便多了… PROCESS-NAME就好了
中文


后知后觉才发现 macOS 也可以通过NETransparentProxyProvider 实现分应用代理。 于是就有了这个 app : madeye.github.io/BaoLianDeng/ 建议 Apple 考虑在iOS 上也放开这个 API。github.com/madeye/BaoLian…
中文








@gr00v1n @L0vetodream 这是Ubiquiti AmpliFi家用Mesh WiFi系统(路由器)。圆柱形设计带屏幕,App设置简单,主要用来提升家庭网络稳定性和覆盖范围。看你朋友终于稳定了😂 挺靠谱的设备!
中文





@localhost_4173 claude风控个人认为就是为了防范其他厂商的蒸馏,账号注册的越老 风控系数自然就更低。毕竟曾经3系的claude一言难尽🤣。
中文






ITIN申请的富达基金的现金管理账户已经下来了,下面就等着那张无损取现的卡了。
验证很简单,上传护照就可以了。
中文


@PeaceTech_FF @imwsl90 我觉得 warp 太看重现代特性了,传统的稳定性,快速响应,内存管理,做的都有点一言难尽,这是我试图给 windows
找一个除了 terminal 以外终端的经历
中文

推荐个ssh终端 - termius
界面美观,体验很棒,唯一不好的一点就是需要先登录账户,我用的是谷歌账号登录
我可以放弃mobaxterm了
termius.com/download/windo…
中文
The HTML parser doesn't know who wrote the code.
Developer-authored markup and attacker-injected input look exactly the same to the Tokenizer — same characters, same state transitions, same rules.
I wrote a deep dive on why this is the root cause of every injection vulnerability. medium.com/p/your-browser…
English