Sabitlenmiş Tweet

Once a programmer becomes used to a complex solution to a problem, simple solutions to the same problem feel incomplete and uncomfortable
— Doug Hoyte
English
Greg Wedow
1.8K posts
@gregwedow
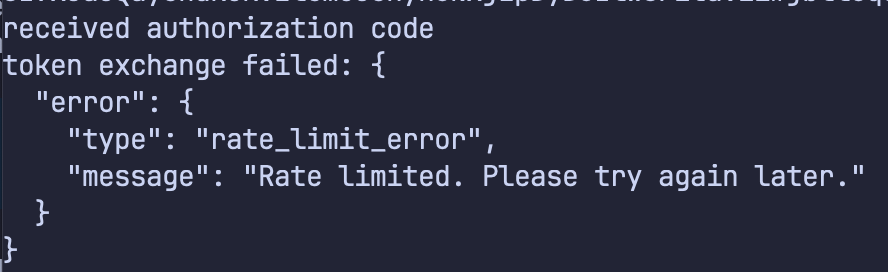
https://t.co/dGaMsQiwEc Task Management for Agents
ok hot take, who (dis)agrees? The general purpose agent/harness doesn’t exist the best harnesses are deeply Task specific and when we use a “default harness” out-of-the-box, we’re just making a tradeoff between - acceptable task performance - time+money spent designing around our task(s) that’s a totally fair tradeoff to make, maybe we’re happy with the out of box perf! what we call a “general purpose” harness is just one that’s reasonably good at a relatively large portion of tasks but there’s a reason why teams that want top 1% agent performance obsessively tweak the harness per Task+Model it’s because you can squeeze out a lot by building bespoke harness tooling for a Task. For a high value task, it’s totally worth the investment Your entire company might be predicated on that investment this effect is pretty clear when we try to swap models “models are non-fungible in their harness” - so the suck if we just drop in codex into the Claude Code harness but if you use the models together in a joint harness and design around the specific problem, you can get great perf I’ve mentioned before but i think the most exciting future is just-in-time harness creation per task idk if that’s a very popular take vs “one model will do everything” but it’s a current mental model and exciting thing i’m messing around with

claude code source is 512K lines opencode is 118K we're getting LOC mogged

Today, we release LFM2.5-350M. Agentic loops at 350M parameters. A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle. <500MB when quantized, built for environments where compute, memory, and latency are constrained. 🧵

We found that agents generate progressively worse code with each iteration. Real developers do not. SlopCodeBench is the only eval that faithfully measures quality degradation on iterative, long-horizon coding tasks. arxiv.org/abs/2603.24755 scbench.ai 🧵

Played around with PrismML's 1bit model. prismml.com It uses 1 bit per parameter, and a FP16 scale factor for each group of 128 params. Cool demo - runs crazy fast. It's able to handle basic tool usage via cursor, but it's nowhere near usable. I rate it neat / 10
@gregwedow @chinar_amrutkar That was the one thing I ran into. No worries though already having fun with it. Built some stuff like context compression inspired by Mastra's observational memory and nicer tool display. Great architecture btw, really easy to extend.