
Gulaid
2.3K posts


Why don’t LLM’s just tell you when you are asking a question / doing something that is out of distribution?
English
Gulaid retweetledi

We used to go to a special website, ask strangers for help with programming, and get humiliated in return

English
Elon is 0 to 1 type of CEO. He is inefficient as a CEO for scaled-up operation.
Benjamin De Kraker@BenjaminDEKR
What exactly is valuable inside Cursor here that justifies $60 Billion? Or is it an acquihire, using Cursor staff to build back the gutted xAI?
English
@NBA__Courtside This guy cares about his lil podcast than not making to the playoff.
English

Draymond Green on him and Devin Booker getting ejected:
“So, obviously Devin Booker and I got ejected. Devin Booker told Scott Foster that I punched him in the stomach, which is a lie. Number one, a punch is with a close fist. Number two, it’s very obvious I was taking a foul. So, Scott Foster goes to review it, realizes I didn’t punch him in the stomach, and he call an away from the play foul. Guy’s passing the ball. So I’m not sure how it’s away from the play, but I think that’s Scott Foster’s way of well, there’s not really much here for me to call a flagrant foul or a technical foul, but I feel I need to do something. And so he calls it away from the play foul, which to me made absolutely no sense. However, I was standing on the sideline and Book was shooting a free throw and I was saying, “Yo, Book, I punched you.” And I just kept saying, “So, I punched you, you know, and he didn’t want to answer.” And so I kept asking him and then finally he was like, “Uh, man, I said I moved on, Dray. I ain’t know. I said I moved on.” And I asked again, so I punched you, you know, he got a little testy and started making some comments. So, I made some comments back to him, but make no mistake about it, man. Book, that’s my young fella. Always have been. That relationship stems back to Book being in high school. And ain’t nothing going to change that relationship. We had that moment. What really pissed me off was we got ejected. We weren’t cursing at each other or anything. We were talking back and forth. And as you can see by AD prank show, I don’t do well with like shut up techs, you know, like I’m going to give you a tech. So you guys have to stop talking. That sh*t don’t work for me.”
(Via @DraymondShow)
NBA Courtside@NBA__Courtside
Draymond Green on his future with the Warriors: “I hope it’s not the end… I have a player option coming up this summer and I don’t know what’s going to happen… this year was a little bit different from me even going through the trade talks at the deadline. Not quite knowing whether I’ll get traded or not. I’ve never gone through that before…. Going into the summer, I don’t know. We’ll see. Ultimately I think I’d love to finish in the place I started, but there must be things held up on both ends” (Via @DraymondShow)
English
@firstadopter maybe you should start a podcast too... insightful Substack!
English




Gulaid retweetledi

Artemis II astronaut Victor Glover received a hero's welcome from his neighbors! 🇺🇸

It’s Ma’am, PhDelightful 🇺🇸@ItsGoneAwry
My daughter’s friend lives down the street from Victor Glover and the neighborhood is throwing him a little welcome home parade 🥹🥹🥹
English
@RobBfromDerby We better listen him, man! he just crazy, enough to do it!
English






The critics who talk about LLM's hallucination problem are, IME, completely correct.
Other than for coding, I just use the chatbots as glorified search engines, and I don't think you should trust a word they say if you can't find a link to back it up.
English
@TheStalwart I hope this is an experiment to measure meaningful productivity and wasted tokens. otherwise, it does not make sense.
English
How does measuring productivity by total token consumption make any sense at all?
The Information@theinformation
Exclusive: Meta employees are competing internally to become “Token Legends,” ranking themselves by how much AI compute they consume. The leaderboard reflects a new status game where token usage is tied to productivity and influence. thein.fo/4cagfEP
English


Gulaid retweetledi


TBPN will remain an independent platform for founders to share news, launch products, and interact with the most engaged audience in tech.
We’ll maintain full editorial control while working with OpenAI to scale the show’s reach and production.
See you at 11a PT, every weekday.
English
OpenAI is acquiring TBPN
This has been a dream job and the show only gets better from here

English

TBPN has been acquired by OpenAI!
The show is staying the same and we’ll continue to go live at 11am pacific every weekday.
This is a full circle moment for me as I’ve worked with @sama for well over a decade. He funded my first company in 2013. Then helped us fix a serious logjam during a critical funding round a few years later. When I took my second company through YC, he was president at the time, and then when I joined Founders Fund, the first deal I saw in motion was the post-ChatGPT round in late 2022. And as we started growing TBPN last year, he was the very first lab lead to join the show.
Thank you to everyone that has been a part of TBPN until now. The last year has been the most fun and rewarding part of my career and we’re excited to have more resources than ever going forward.
English
Iranians and Americans don't really know each other. Iran was better off to make a skit or a meme on tiktok. People don't read 4 pages long letter from heads of states.
Ali Ahmadi@AliR_Ahmadi
Asking Americans to read a 4 page letter ... sigh
English
@TheStalwart @Havelock_AI He should have done a tiktok video instead. Most Americans read at 7-8th grade level according to the the national literacy institute.
English
Just 31%. Iranian President Masoud Pezeshkian communicates to the American people in a very literate register, according to @Havelock_AI


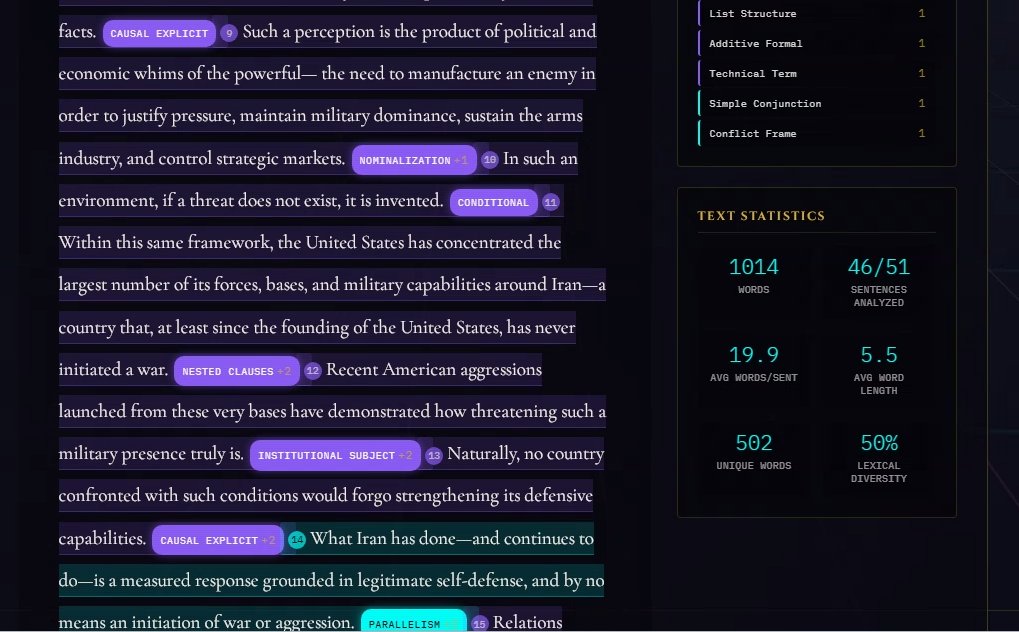
English
We should start entertaining the idea of incorporating LLMs in legal processes. People can be flawed with insufficient bandwidth
Robbie Harvey@therobbieharvey
More clips of Judge Milliron are popping up after a viral clip of him berating an IT worker last week.
English
@TechNerd4everr They are playing catchup.. perplexity is only 400 members team, and they not financially super profitable. it makes sense.
English
Microsoft is losing ground in the AI race. With the OpenAI relationship souring, acquiring Perplexity could be their smartest move to stay relevant in the AI application layer
Satya Nadella@satyanadella
New in M365 Copilot: Council. You can run multiple models on the same prompt at the same time, so you can see where they align and diverge, and understand what each adds.
English