Gurvan
151 posts

Gurvan
@gurvanson
I like Super Smash Bros. Melee for the Nintendo Gamecube™, Machine Learning, and most of all taking care of my friends.

Aight let's talk about frameworks, libraries, RL, and why I probably don't like your favorite RL codebase. Yes, including that one. The unusual thing about RL is that the algorithm is the easy part. GRPO is a single-line equation on some logprobs. If you have the data, computing the loss is trivial, and then presumably you're using it with a backprop library of your choice. But that's the problem -- getting the data. It's a pain in the ass. In regular RL you have to do rollouts, perhaps truncate some episodes, and handle the ends accordingly. If you don't want to be a snail, you'll want to vectorize the environment and adapt the algorithm for that. If you want to do an LLM, you need to do all the nonsense that makes LLMs fit in memory. You need to be careful about your prompts, mask out the right parts for the loss. You need a decent generation engine (vLLM), which then makes it a pain to update the weights. If you want to do multi-agent multi-turn LLM RL, might as well do commit sudoku. While we have many disagreements on just about anything RL-related, I think @jsuarez's Pufferlib exemplifies this point beautifully. It's without a doubt incredible at what it does - training RL algos on simulated environments very very quickly. But most of its novelty is pure infra. The core algorithms are largely the same as they've been for years, and I'm willing to bet they represent less than 10% of the overall engineering effort. Naturally, this has implications on the code you need to write to do anything beyond running the built-in examples. What I find time and time again, is that for many sufficiently nontrivial (read: interesting) research problems, it takes a similar amount of time to (a) write the thing from scratch/from simple primitives, or (b) adapt an existing framework to accommodate crazy ideas. In the former, you focus on writing the actual logic. In the latter, you wrangle the framework to allow you to add the logic. I know what I like better. All of this is because the algorithm is the easy part. The infra is the pain in the ass. So whenever you're in a position to choose - use the tools that simplify infra, and write the training loop yourself. Don't build frameworks, build libraries. You'll thank yourself later. Big shout out to my Master's supervisor from back in the day, who was the first one to tell me to drop rllib and just write PPO myself in PyTorch. And to @hallerite for inspiring me to finally write up this rant. I might write a proper effortpost with examples at some point in the future if the people demand it.






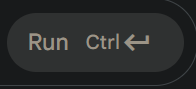












@stanislavfort i honestly picked the wrong graph to show. It is trained from scratch, but in an incremental fashion where parameters (the pseudo key/values) are iteratively increased, each time initializing at zeros.


TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters Natively scalable architecture that leverages the attention mechanism not only for computations among input tokens but also for interactions between tokens and model parameters. Replaces all the linear projections with a token-parameter attention layer where input tokens act as queries and model parameters as keys and values. Links below