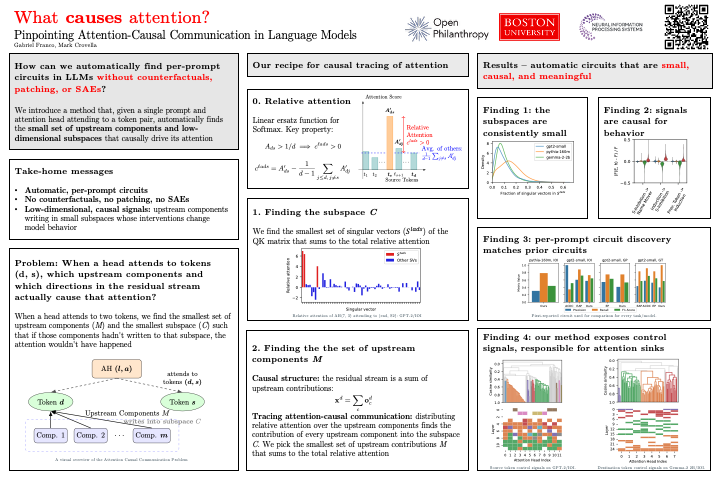
Sabitlenmiş Tweet

Why do attention heads attend where they do?
We can now pinpoint the EXACT features causing attention—without counterfactuals, patching, or SAEs.
New @NeurIPSConf 2025 paper with @mcrovella: "Pinpointing Attention-Causal Communication in Language Models"

English