@dallascard @ShayneRedford @emilyrreif @katherine1ee @dmimno @daphneipp @naaclmeeting Thanks--it was great to meet you the other day!
English
Gregory Yauney
27 posts

@gyauney
Cornell PhD student working on ML and NLP


Come talk to us about pretraining data curation at #NAACL2024 at 2pm at poster session 2! We're presenting A Pretrainer's Guide to Training Data Paper: aclanthology.org/2024.naacl-lon…

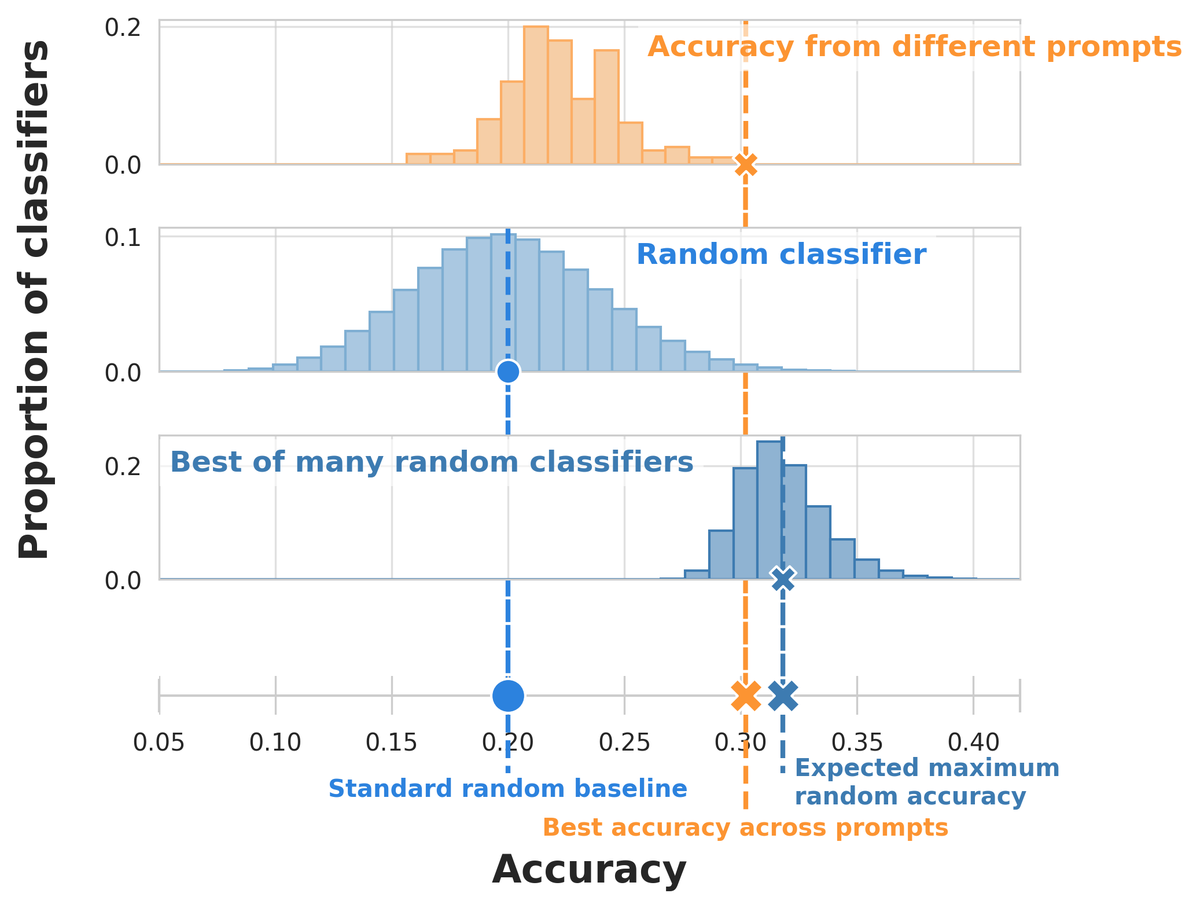
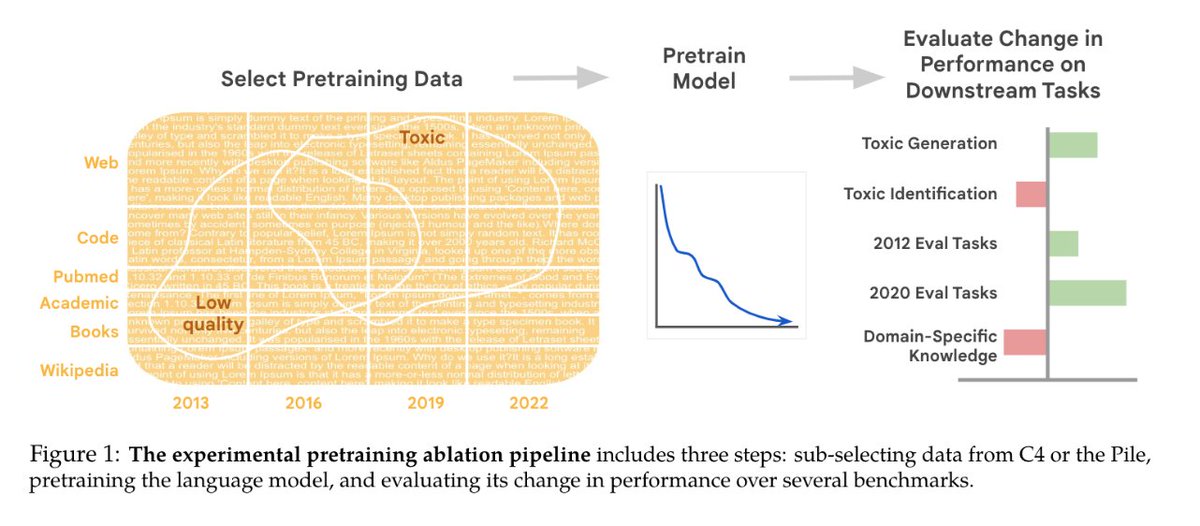
#NewPaperAlert When and where does pretraining (PT) data matter? We conduct the largest published PT data study, varying: 1⃣ Corpus age 2⃣ Quality/toxicity filters 3⃣ Domain composition We have several recs for model creators… 📜: bit.ly/3WxsxyY 1/ 🧵