Sabitlenmiş Tweet
h4pZ
219 posts




New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along.
(Remember matmul is the single most important operation that transformers execute both during training and inference. Most of NVIDIA compute is spent on it. Gaining 1% in efficiency translates to massive savings in the order of many nuclear reactors :P)
I, yet again, realized i underestimated the effort. 😅 Here is one more booklet (lol). 47 figures!
I covered:
* The fundamentals of the GPU architecture with an emphasis on the memory hierarchy, building mental models for GMEM, SMEM, and L1/L2, and then connecting them to the CUDA programming model. Along the way we also looked at the "speed of light," how it's bounded by power, with hardware reality leaking into our model.
* PTX/SASS, and how to steer the compiler into generating what we actually want (is that loop being unrolled, are we using vectorized loads like LDG.128, etc.). I've annotated one PTX/SASS example for a simple matmul kernel in excruciating detail. Even if you're new to compilers you should find this useful.
(i actually found various inefficiencies in both compilers - fun!)
* Many core concepts such as tile/wave quantization, occupancy, ILP (instruction-level parallelism), roofline model, etc. Also building intuition around fundamental equivalences: dot product as a sum of partial outer products, why square tiles are the right shape for high arithmetic intensity, etc.
* The warp tiling method - which is near SOTA assuming you can't use tensor cores, TMA, async mem instructions, and bf16. Just maximizing GPU's performance using nothing but CUDA cores, registers and shared memory.
* Finally, we step into Hopper (H100): TMA, swizzling, tensor cores and the wgmma instruction, async load/store pipelines, scheduling policies like Hilbert curves, clusters with TMA multicast, faster PTX barriers, and more.
As always lots of examples, lots of visuals. This is the first time i could see warp tiling kernel and be like "oh i get it completely". I just needed my mental image transformed into an actual image.
A few years ago I was really inspired by @Si_Boehm's excellent blog post on how matmul works, but I also found it had several errors, some unclear explanations, and it was quite outdated. Building on @pranjalssh amazing work (who did a great job building sota kernels for H100) and my own research, this is the final result.
---
Again a huge thank you to @Hyperstackcloud (GPU cloud) for giving me an H100 (PCIe) node to run some of the experiments and analysis that i needed to write this up.
Also a big thank you to my friends Aroun (who did a very thorough review of the post; Aroun's doing cool GPU/AI stuff at Magic and was previously GPU architect at Apple and Imagine, he's one of the best GPU people i know and we worked together on llm.c w/ @karpathy) and the amazing @marksaroufim! (PyTorch) for taking the time during weekend when they didn't have to. :)

English
Thanks google and berkeley (gradient estimation)
arxiv.org/abs/1906.10652
arxiv.org/abs/1506.05254
English

@cgarciae88 @giffmana Gotta min the distance from the equator and max gdp per capita
English


This has been my 2nd time in Vancouver, and I have to admit, if Switzerland were to implode, I might move here.
They even have ONE Belgian place, which was great :) Except they didn’t have sauce samouraï. But Zurich has 0 if you don’t count my home.
Was great meeting everyone!!




Lucas Beyer (bl16)@giffmana
Good morning Vancouver! Things are different here: this guy is alone, chonky, and not scared at all, I was more scared of him towards the end lol. Also look at that … industrialization
English

If you haven't got the time to learn basic notebook-engineering, don't worry, there's a fix:
Just record a video, or write a blog post, telling everyone else not to use notebooks.
If you're successful, then you'll never have to learn, and no-one need know about your problem.
English
@giffmana @DavidBeniaguev @yacineMTB Thanks for sharing, I’ll try these and see how it goes. I’ve had good results back by using OWLViT as a visual prompt engine and then feeding the results into something like SAM if I want segmentations.
Sometimes it’s easier to describe an object by an image rather than text
English

What are some computer-vision tasks that are actually useful IRL and cannot be done by any of the current gen LLM chatbot with image input?
Not looking for academic made-up benchmarks or brain-teaser tasks, only things that actually help you do stuff IRL.
English





h4pZ retweetledi

Hot take 🔥: Lots of buzz these days about new foundation open-source models but what if I told you there have been no real advance since 2019's T5 models 😀
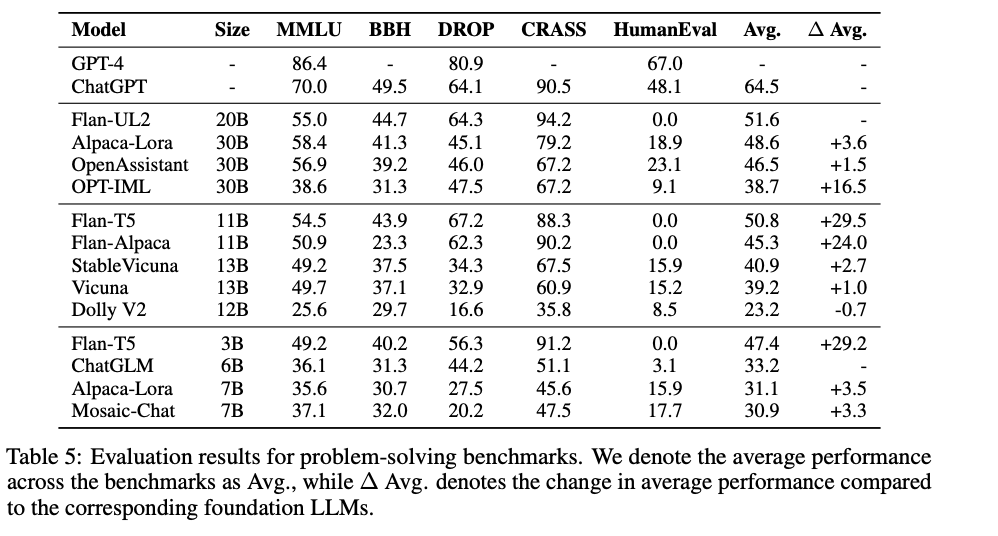
Take a look at this table from this new InstructEval paper: arxiv.org/abs/2306.04757. Some thoughts/observations:
1. Flan-T5 beats everything, including Alpaca (LLama-based), Flan-Alpaca, Mosiac-Chat/MPT, Dolly.
2. If you arrange this table in terms of "compute-match", encoder-decoder should have been in a different (lower) weight class. Basically, Flan-T5 3B is like a 1B+ decoder and Flan-UL2 is more like a 8B+ model. With this perspective, the gap is so dramatically huge that it's not even funny.
3. Flan-UL2 basically wrecks Alpaca-Lora 30B despite being so much smaller and effectively 4x less compute.
4. This is not entirely about Flan series models - it's more about the base models! The point is that the base T5 models are already ridiculously strong. 1 trillion tokens, just blatantly repeating C4 to heart's content. There's also mT5 and uMT5 which are strongly multilingual and ridiculously good. The base models are not long context, but Flan mitigates this.
5. The weakness is that T5/UL2 models are not diverse and are only C4 trained that means they probably don't do well at code/math whatever (code eval 0 score below lol). But its scary how strong a C4-only baseline that we had since 2019 is performing.
6. If you look at fastchat-t5 on the chatbot arena by @lmsysorg the 3B fastchat model does as well as MPT-7B et al despite being only 3B (and if you paid attention till now you know that's a 1B+ equivalent decoder-only model). That's really insane if you think of a 1B+ model on a leaderboard of all these new "OSS LLM advances".
7. It's likely at compute match, T5 >> Llama. The only problem is that we don't have T5 models at 30B and 65B.
You're welcome.
English

do you guys think going to school for a CS degree is still viable and worth the debt or am i just going to hope that just going for a autodidactic route an building shit will be viable to start a career in the future since chatgbt is pretty much the best teacher? pic very related

English


@MarcJSchmidt Wait weren’t you actually building it? What happened with deepkit
English

I really wonder why we don't have cool user interfaces for deep learning models yet, something like that:
would be so nice seeing the architecture, live stats of weights, intermediate layer visualisations, see gradients flowing, gradient bottlenecks, learning speed, etc


English
Do you guys think that SWE jobs will be viable in japan in 5+ years as a American? I’m more into the idea of quality of life then salary but I’ve heard work culture is insanely crunchy plus according to a friend who taught english there, they can be pretty sexist/xenophobic..
English
