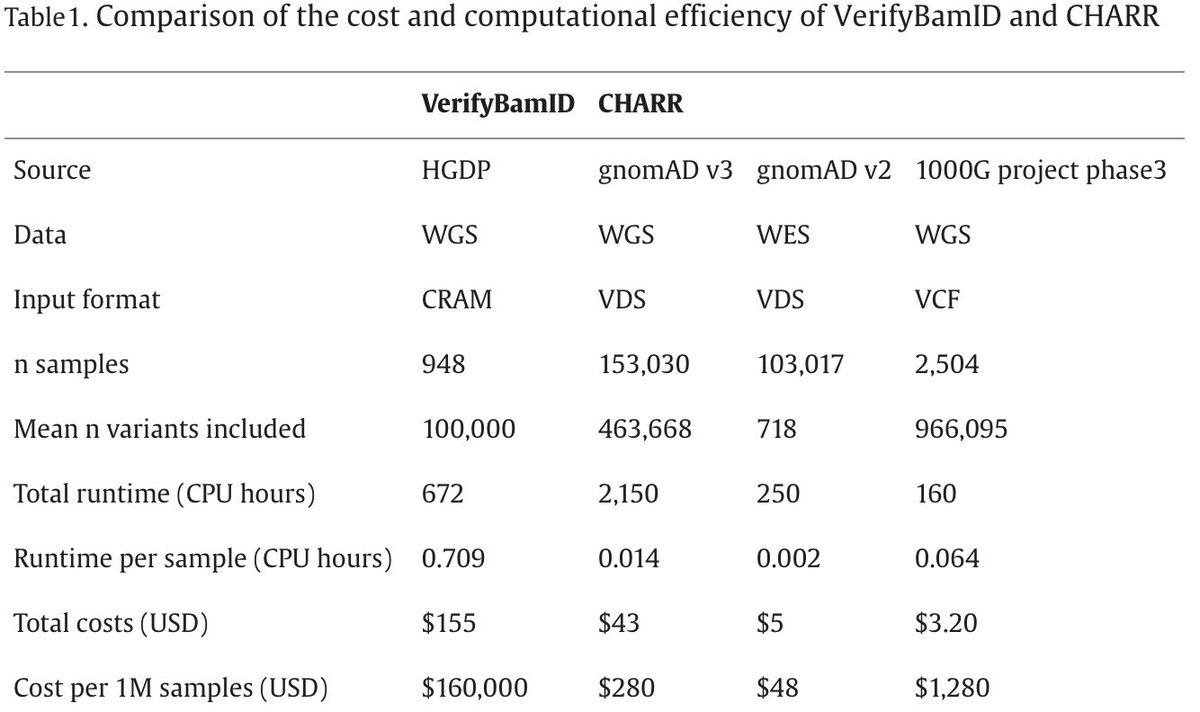
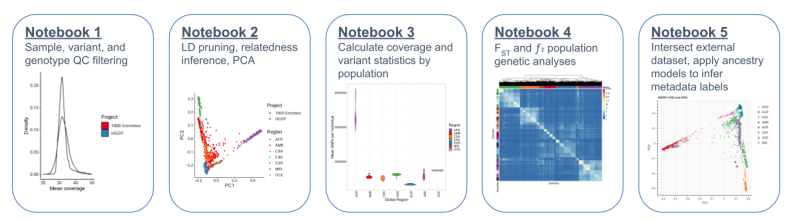
Sabitlenmiş Tweet

Hey all! We are running a survey to solicit broad-based feedback from users & *non-users* of Hail
Query. We'd like to hear from anyone who analyzes sequencing or genotype-chip datasets!
All questions optional, fully anonymous, & takes <=10min!
forms.gle/ucgu9h35UEkB68…
English