
Enterprise-Bench, available now on the Harbor Hub!
hub.harborframework.com/datasets/Enter…
English
Harbor Framework
130 posts


We audited SWE-Bench Pro, one of the most widely used AI coding benchmarks, and found it no longer reliably measures frontier coding capability. We find 30% of SWE-Bench Pro tasks to be broken, and are retracting our previous recommendation that the research community use it as a leading coding eval. openai.com/index/separati…
📊 Your Android Bench July update: 1. Added 8 new models, check out the top of the leaderboard! 2. You can now contribute to the benchmark. 3. We standardized our benchmark by transitioning to the @harborframework. Read about what's new → goo.gle/4p7Mc6G
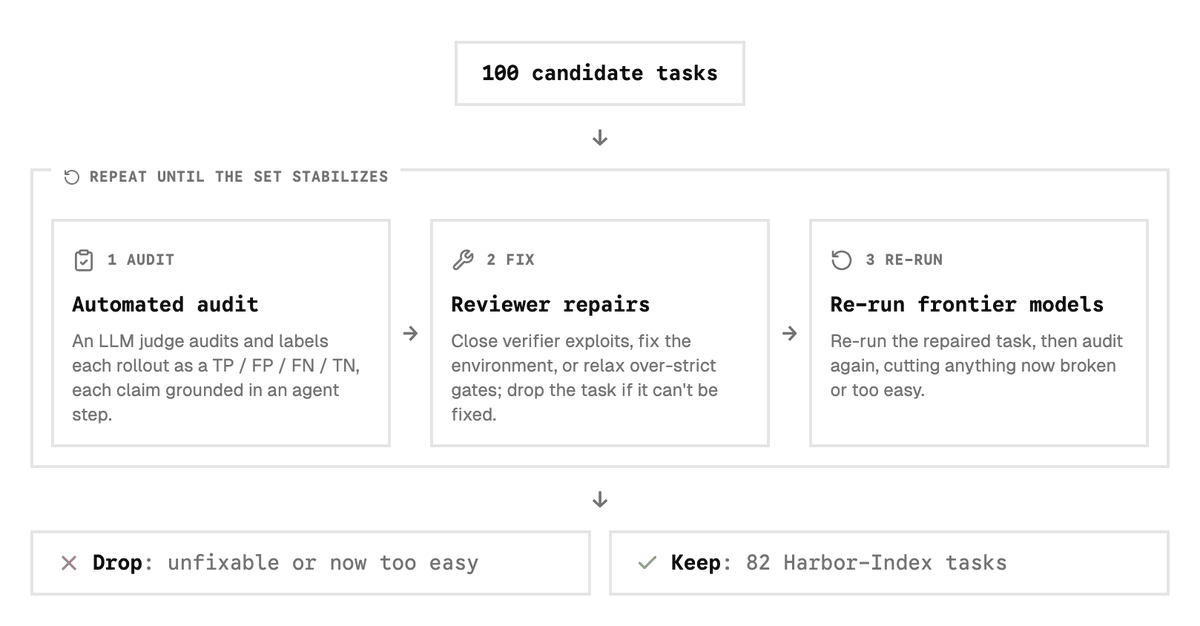
Introducing Harbor-Index, a compact, diverse, and high-quality benchmark built to challenge frontier agents. We carefully select, audit and fix 82 high-signal tasks out of 6,627 candidates spanning 54 benchmarks. No agent gets above 30%. (1/5)


Rollouts for eval, rollouts for RL, rollouts for GEPA, rollouts for prod, rollouts for trajectory analysis, rollouts for SFT data gen, rollouts rollouts rollouts

Rollouts for eval, rollouts for RL, rollouts for GEPA, rollouts for prod, rollouts for trajectory analysis, rollouts for SFT data gen, rollouts rollouts rollouts


Rollouts for eval, rollouts for RL, rollouts for GEPA, rollouts for prod, rollouts for trajectory analysis, rollouts for SFT data gen, rollouts rollouts rollouts


@nummanali We want Harbor to be the rollout primitive that powers every optimization loop. Eventually we will also natively implement common optimization loops on top of Harbor primitives. But I’d encourage you to cook on the use case you described and use Harbor to power it!
Harbor is the easiest way to run any agent with any model in any sandbox on any task in parallel. And that doesn't just mean evaluation and training. Stay tuned!






We expect agents to act like senior engineers, but most benchmarks still evaluate them like interns. Excited to introduce Senior SWE-Bench, an open-source and @harborframework-native benchmark that assesses agents as senior engineers on long-horizon tasks with realistically under-specified instructions. We expect agents to build real features going on just a quick Slack message, nothing like the super technical instructions most benchmarks provide. Senior SWE-Bench fixes that. Claude Opus 4.8 is the current leader at 24% high quality solves, but it took 117K tokens on average to get there. Claude Sonnet 5 looked like it was going to swoop in for the top spot, but we found it cheated on 26% of trials.


Introducing eve, an agent framework. 𝚊𝚐𝚎𝚗𝚝/ 𝚊𝚐𝚎𝚗𝚝.𝚝𝚜 𝚒𝚗𝚜𝚝𝚛𝚞𝚌𝚝𝚒𝚘𝚗𝚜.𝚖𝚍 𝚝𝚘𝚘𝚕𝚜/ 𝚜𝚔𝚒𝚕𝚕𝚜/ 𝚜𝚊𝚗𝚍𝚋𝚘𝚡/ 𝚜𝚌𝚑𝚎𝚍𝚞𝚕𝚎𝚜/ Like Next.js, for agents. vercel.com/blog/introduci…