Fuli Luo@_LuoFuli
Two days ago, Anthropic cut off third-party harnesses from using Claude subscriptions — not surprising. Three days ago, MiMo launched its Token Plan — a design I spent real time on, and what I believe is a serious attempt at getting compute allocation and agent harness development right. Putting these two things together, some thoughts:
1. Claude Code's subscription is a beautifully designed system for balanced compute allocation. My guess — it doesn't make money, possibly bleeds it, unless their API margins are 10-20x, which I doubt. I can't rigorously calculate the losses from third-party harnesses plugging in, but I've looked at OpenClaw's context management up close — it's bad. Within a single user query, it fires off rounds of low-value tool calls as separate API requests, each carrying a long context window (often >100K tokens) — wasteful even with cache hits, and in extreme cases driving up cache miss rates for other queries. The actual request count per query ends up several times higher than Claude Code's own framework. Translated to API pricing, the real cost is probably tens of times the subscription price. That's not a gap — that's a crater.
2. Third-party harnesses like OpenClaw/OpenCode can still call Claude via API — they just can't ride on subscriptions anymore. Short term, these agent users will feel the pain, costs jumping easily tens of times. But that pressure is exactly what pushes these harnesses to improve context management, maximize prompt cache hit rates to reuse processed context, cut wasteful token burn. Pain eventually converts to engineering discipline.
3. I'd urge LLM companies not to blindly race to the bottom on pricing before figuring out how to price a coding plan without hemorrhaging money. Selling tokens dirt cheap while leaving the door wide open to third-party harnesses looks nice to users, but it's a trap — the same trap Anthropic just walked out of. The deeper problem: if users burn their attention on low-quality agent harnesses, highly unstable and slow inference services, and models downgraded to cut costs, only to find they still can't get anything done — that's not a healthy cycle for user experience or retention.
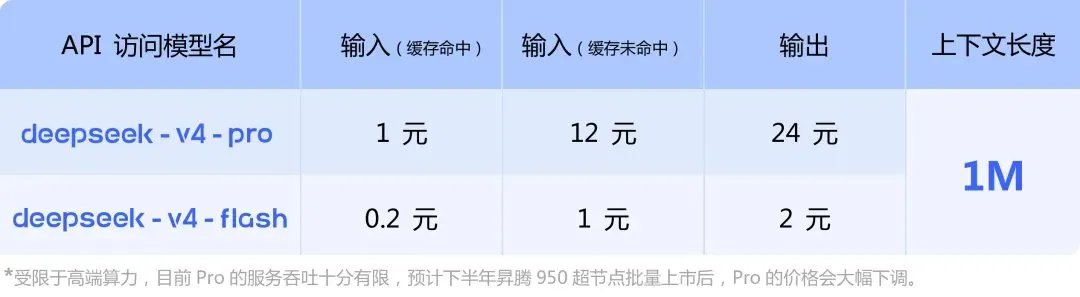
4. On MiMo Token Plan — it supports third-party harnesses, billed by token quota, same logic as Claude's newly launched extra usage packages. Because what we're going for is long-term stable delivery of high-quality models and services — not getting you to impulse-pay and then abandon ship.
The bigger picture: global compute capacity can't keep up with the token demand agents are creating. The real way forward isn't cheaper tokens — it's co-evolution. "More token-efficient agent harnesses" × "more powerful and efficient models." Anthropic's move, whether they intended it or not, is pushing the entire ecosystem — open source and closed source alike — in that direction. That's probably a good thing. The Agent era doesn't belong to whoever burns the most compute. It belongs to whoever uses it wisely.