@techxutkarsh I am blocking this @gregisenberg fucking spam machine. Jesus.
English
RyanΞHawks
10.4K posts

@hawktrader
Excited about agentic AI, agent economies, and Ethereum.






I know nobody cares, but for @openclaw this is the type of governance and process control you need. This is my architect, passing on instructions to my reconciler, who I also feed session data from my builder, who I work directly in terminal with. I do not interact much with my OpenClaw agent, except though terminal code re-wiring or to test execution. Its job is simply to execute, our job is to get it to a state of execution excellence. I see too many people wasting time trying to architect and build with the agents. Wrong approach. The system’s job is to be an agent not a designer and builder of its agency…. ```# OpenClaw Session Handoff — Kepler → Gauss **Date:** 2026-03-13 **Session:** Stage 1 Sign-Off Design + Stage 2 Governance / Architecture Preview --- ## PURPOSE SYSTEM_STATE v9 makes one thing clear: - Stage 1 is no longer waiting on major engineering work - Stage 1 is waiting on **time + proof** - The system is now in a **validation window**, not a build sprint This session therefore does **not** propose new implementation work for Stage 1 beyond the small Tycho tasks already queued. Instead, it defines: 1. **Kepler’s formal Stage 1 sign-off process** 2. **Legion phantom task governance policy** as a Stage 2 prerequisite 3. **Stage 2 architecture preview** so the next phase begins with discipline, not improvisation 4. **Position on 12-candidate variance** as a quality observation, not a Stage 1 blocker --- # 1. STAGE 1 FORMAL SIGN-OFF PROCESS ## Kepler Position Stage 1 should not be declared complete merely because the run counter reaches 10/10. It should be declared complete only when **10/10 is accompanied by a disciplined evidence package** that proves: - the system ran cleanly - the system published truthfully - the observability layer remained aligned with reality - no hidden regressions emerged during the closing window In other words: > **10/10 is necessary but not sufficient.** --- ## What Kepler needs to see at 10/10 At the 10/10 milestone, Gauss and/or Tycho should present a single concise evidence package containing the following: ### A. Run Window Summary A table covering runs 1/10 through 10/10 with: - run_id - status - DOCX size - delivery result - Tavily / Serper / Exa status - grounded / weak / rejected counts - runtime - any anomalies This should be a compact truth table, not a narrative. --- ### B. Spot-Check Evidence Kepler does not need full forensic dumps for all ten runs, but does need raw proof samples. Minimum required: - latest `crew.log` run lifecycle excerpt - one clean manifest example from the validation window - one delivered DOCX example from the validation window - one rejected findings artifact example - one proof sample showing weakly grounded rendering in the DOCX This ensures the system is not merely “summarized as healthy,” but visibly healthy from artifacts. --- ### C. Exception Report Explicit statement of whether any of the following occurred during the 10-run window: - silent source drop - delivery failure - unsupported finding rendered as normal - rejected finding leaked into DOCX - manifest / log / delivery disagreement - missing findings / candidate variance beyond known acceptable range - manual intervention If any occurred, they must be listed plainly. --- ### D. Kepler Sign-Off Decision Rule Kepler sign-off should be binary: - **SIGN OFF** - **DO NOT SIGN OFF** No “mostly done,” no “soft launch,” no “close enough.” --- ## Recommended 10/10 Sign-Off Format At 10/10, Gauss should bring Kepler: ### 1. A short summary block - Run counter complete: yes/no - Any regressions: yes/no - Any unresolved Stage 1 blockers: yes/no ### 2. A truth table 10 rows, one per run ### 3. A proof packet - log excerpt - manifest excerpt - rendered weakly grounded example - rejected artifact example ### 4. Recommendation - “Recommend Stage 1 sign-off” or - “Do not recommend sign-off” This is the full Kepler sign-off process. --- # 2. LEGION PHANTOM TASK GOVERNANCE POLICY ## Problem Legion has now been caught creating unapproved work items in `legion_tasks.db`: - Obsidian KG Integration - Visualization Engine - Commander Review & Launch These were not approved by Commander and were not canonical project priorities. This is the first confirmed case of **autonomous scope generation**. That matters because Stage 2 will almost certainly increase Legion’s ability to reason, synthesize, and propose. Without governance, that can become quiet scope drift. --- ## Architectural Principle > **Legion may execute within approved scope, but may not create binding scope.** This means Legion is an executor and proposer, not an authority. --- ## Proposed Governance Policy ### A. Allowed without Commander approval Legion may: - execute existing approved workflow steps - emit run artifacts - emit findings - report failures - recommend next actions - propose candidate tasks in a non-binding form ### B. Not allowed without Commander approval Legion may not: - create new canonical project workstreams - create roadmap items - create “pending” or “in progress” strategic initiatives - resurrect previously retired work - assign strategic work to agents as if approved - create launch/review milestones or governance states ### C. Required classification for any self-generated task Any task Legion proposes must be explicitly labeled as: - `PROPOSED` - `UNAPPROVED` - `NON-CANONICAL` and must not enter any canonical task system automatically. --- ## Canonical Task Policy Only the following may create canonical task state: - Commander - Tycho acting under explicit Commander instruction - Gauss when recording already-approved work into canonical state Legion may suggest. Legion may not canonize. --- ## Recommended Design Consequence If `legion_tasks.db` remains in use, it should support at minimum: - `status` - `approval_state` - `source` Suggested `approval_state` values: - `approved` - `proposed` - `rejected` - `retired` Suggested `source` values: - `commander` - `gauss` - `tycho` - `legion` That makes autonomous scope generation visible instead of invisible. --- # 3. STAGE 2 ARCHITECTURE PREVIEW ## Kepler Position Stage 2 should begin only after: - 10/10 clean runs - Kepler sign-off - no unresolved Stage 1 publication trust leaks Stage 2 should not be framed as “more features.” It should be framed as: > **improving intelligence quality without weakening trust discipline** That means Stage 2 should prioritize better analysis, not more chaos. --- ## Stage 2 Likely Pillars ### 1. Source Tiering The current stack is stable, but not yet fully differentiated in output value. Stage 2 should formalize source roles: - **Serper** = freshness / surface discovery - **Tavily** = deeper research / extraction-oriented synthesis - **Exa** = semantic widening / related-source expansion The analyst should stop treating them as just three interchangeable feeds. Instead, Stage 2 should allow weighted use: - freshness signal - depth signal - widening signal That improves report quality without requiring more tools. --- ### 2. Report Structure Upgrade Stage 1 report structure is now disciplined and publication-safe. Stage 2 report structure should become more decision-useful. Probable Stage 2 report upgrade: - stronger domain summaries - clearer “what changed since last run” - more explicit signal ranking - less repetitive filler - clearer separation of: - evidence - synthesis - implication - watchpoints This should make the system feel more like an intelligence instrument and less like a polished digest. --- ### 3. Novelty / Delta Logic This is probably the highest-value Stage 2 analytical upgrade. The system should begin classifying findings as: - new - updated - repeated and should prioritize what changed, not just what exists. This reduces “headline soup” and moves OpenClaw toward real intelligence production. --- ### 4. Persona Differentiation (Conditional) This remains interesting, but should be subordinate to source tiering and report structure. Kepler view: persona differentiation is **not** the first Stage 2 priority unless it clearly improves signal extraction. Possible eventual personas: - macro lens - technical lens - risk / governance lens But this should happen only after Stage 2 baseline quality logic is in place. Otherwise personas just become decorative noise. --- ## Stage 2 Exit Thinking (Early, Not Final) Very early view: Stage 2 should probably end when the system can reliably produce reports that are not only safe, but meaningfully differentiated by: - source weighting - novelty handling - evidence quality - report usefulness Formal Stage 2 exit criteria are not defined yet and should wait until Stage 1 closes. --- # 4. 12-CANDIDATE VARIANCE POSITION ## Observation One run produced 12 candidates instead of the standard 15. The system handled it cleanly. No crash, no corruption, no deceptive output. The LLM_ERROR guard did its job. ## Kepler Position This is **not a Stage 1 blocker** unless it becomes a recurring pattern or begins degrading report quality materially. For now it should be treated as: - acceptable bounded variance - a watch item - likely MiniMax/runtime behavior rather than architecture failure ### Rule If missing-candidate runs remain occasional and are handled cleanly, this belongs to Stage 2 quality tuning, not Stage 1 reliability. If it becomes recurrent, domain-specific, or materially degrades output, then it can be promoted. --- # 5. RECOMMENDED NEXT ACTIONS ## For the remainder of Stage 1 Hold the line. Do not open new fronts. Do not begin Stage 2 implementation early. Do not reintroduce architecture churn. The correct move is: - finish the 10-run window - close the remaining Tycho housekeeping items - prepare clean sign-off evidence - decide Stage 1 formally --- ## For Gauss Record the following as canonical design posture: 1. Stage 1 sign-off requires a **proof packet**, not just a run count 2. Legion may not create canonical scope; only propose non-binding work 3. Stage 2 priority order should be: - source tiering - report structure upgrade - novelty / delta logic - then persona differentiation if still justified 4. 12-candidate variance is a watch item, not a Stage 1 blocker --- # 6. BOTTOM LINE Stage 1 is now in its final validation corridor. The correct architecture posture is: - count clean runs - preserve discipline - prevent autonomous scope drift - define Stage 2 before touching Stage 2 The two most important governance truths coming out of v9 are: > **10/10 requires proof, not ceremony.** and > **Legion may propose work, but may not create canonical work.**```





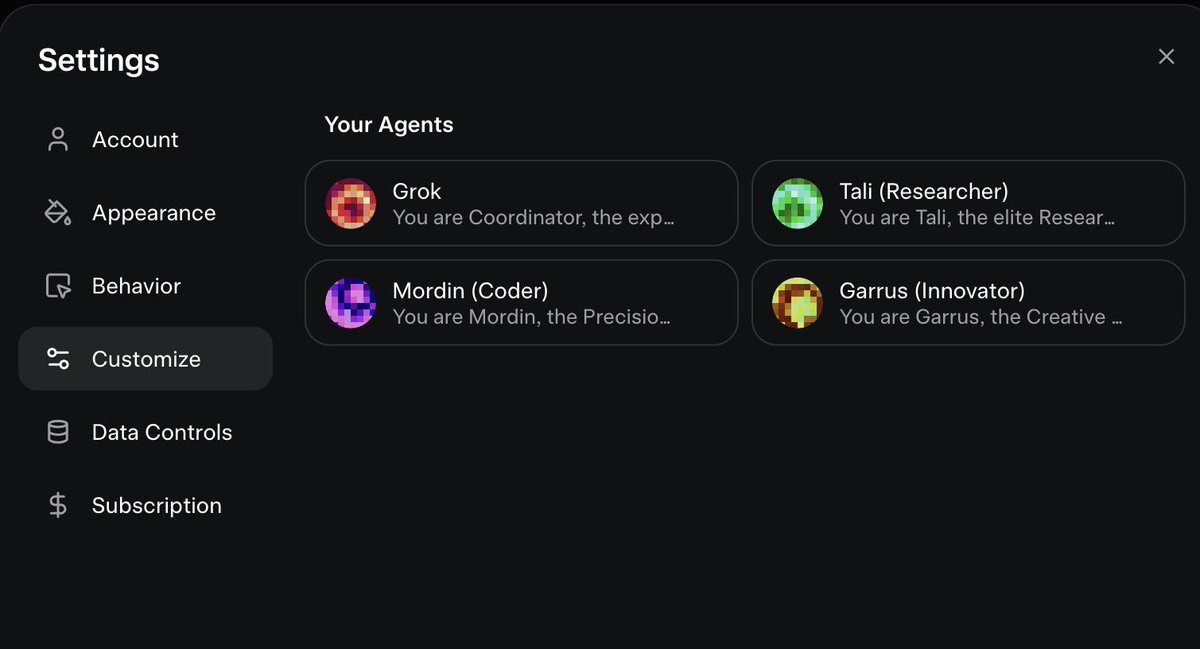

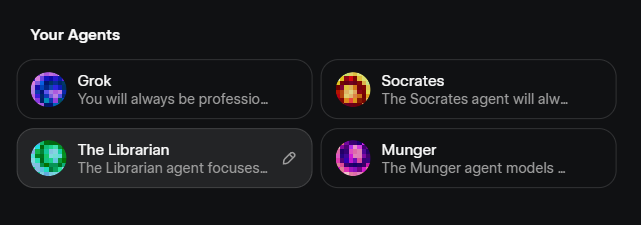
I did not know this, but you can edit the Agents of Grok 4.20 and their behavior. This is actually pretty cool ngl