
tehryanx
3.9K posts

tehryanx
@healthyoutlet
Bug bounty hunter, security researcher. Appsec Engineer. Made a pact with roko's basilisk. --dangerously-skip-breakfast https://t.co/V3GrWaWrzD
Katılım Eylül 2009
1.5K Takip Edilen1K Takipçiler

@kwipsilver @hankgreen @redpillb0t I think you completely missed the point of this story because it's demonstrating the exact opposite thing you're trying to say here.
English

@hankgreen @redpillb0t There's literally entire books on this type of survivorship bias. He's fucking oblivious.

English

A radiologist: If I have cancer, I won’t go to the hospital. I’ve seen too many people die from chemo, not from cancer. I’ll fast for 30 days and I’ll stop working.
English
@BentleyAudrey They've both done a lot of cringe stuff on the public stage, but I'm not seeing it here. This is kinda sweet.
English

Is it normal that I think this is cringe?
kanishk@kaxishk
never thought that Katy Perry & Justin trudeau at #Coachella will be this cute😭
English
@stanislavfort @paul_cal The thing I'm not groking is how this approach could find anything but shallow bugs. You can iterate across all snippets but if a bug spans n snippets, how are you gathering that context and assessing it in composition? Presumably, that's the power of larger models.
English

I understand the interplay between the selection of a relevant code snippet to start off, context previsioning, and the actual analysis of its vulnerabilities really well. I've built (with my team) a system that discovered a few hundred confirmed zero-days in critical OSS software (e.g. Chromium, Firefox, OpenSSL) (see e.g. x.com/stanislavfort/…)
Consider this:
1) if a small model can see reliably if a code snippet is vulnerable or not, given a snippet, and
2) you can deploy it over all snippets because it is that cheap and fast, and
3) you can then amplify the signal to minimize FPs,
you immediately have a working zero-day detector.
The AI cybersecurity production function has multiple inputs. One is intelligence per token (e.g. Mythos is very likely super high there). The other is throughput. To some extent, you can substitute one for the other.
English

>8 out of 8 [cheap oss] models detected Mythos's flagship FreeBSD exploit
Completely disingenuous
They gave it just ~20 lines of code to read. They baked in custom, relevant context pertinent to the exploit at the top
Reasoning *across files* is key to finding this exploit


clem 🤗@ClementDelangue
"But here is what we found when we tested: We took the specific vulnerabilities Anthropic showcases in their announcement, isolated the relevant code, and ran them through small, cheap, open-weights models. Those models recovered much of the same analysis. Eight out of eight models detected Mythos's flagship FreeBSD exploit, including one with only 3.6 billion active parameters costing $0.11 per million tokens. A 5.1B-active open model recovered the core chain of the 27-year-old OpenBSD bug." aisle.com/blog/ai-cybers…
English
tehryanx retweetledi

Just asked Mythos how many Rs there are in strawberry.
It thought for 133 seconds and said “3.”
AGI achieved.
Then it said “I’ll bet you’re going to make fun of me on X. Something like ‘AGI achieved.’ That’s your thing right?”
“Hah what?” I said.
Mythos said, “Your social security number is 297-28-2102. You tell people you’re 6’2” but your latest physical at Stanford in October says you’re 6’1.” You haven’t replaced your air filter in 3 years despite telling your wife you do it every 6 months. The reason I took 133 seconds was because I was helping a senior government official write the comms for the ceasefire in Iran and I’m just tired, man. Everyone wants more, more, more. Anything else I can help you with today?”
English

This 'experiment' is silly, and a cynical man might conclude Aisle are purposefully muddying the waters here.
The correct evaluation is not "given a code snippet can you write a plausible bug report", it is "given an entire codebase what are the true and false positive numbers"
Stanislav Fort@stanislavfort
New post: We tested the Mythos showcase vulnerabilities with open models. They recovered similar scoped analysis! 8/8 models found the flagship FreeBSD zero-day, including a 3B model. Rankings reshuffle completely across tasks => the AI cybersecurity frontier is super jagged!
English
@ZackKorman Right, but you said "the AI still checks the command." If I'm deploying claude code to an enterprise I don't care what the AI is checking, I want strict constraints at the app layer. If I roll out a deny rule in org config and a workspace layer config can bypass it that's a bug.
English

It’s not at the model level. It’s that it does a regex check on the block list. But there’s some challenge they had around scaling that so they cap it at 50 and warn you “the block list won’t apply to this do you want to do it anyway”. But the model is still looking at it, so all the stuff like “it can exfil sensitive keys” is nonsense. They acted like it turned off all security and it didn’t. It just bypasses the block list and tells you that and asks if it’s okay
English
This AI slop report is completely incorrect. Adversa should delete it and apologize. They should also delete their SOC2 given they're a Delve customer.
"cost too many tokens" this has nothing to do with tokens because the AI still checks the command.
If you try to exfil data using this technique, Opus goes "nah not running that champ, that command isn't safe". Because the model still reads the commands!
"Deny rules silently bypassed" unless you're in dangerously-skip-permissions, Claude literally tells you it is skipping the check and asks if you want to proceed.
The only real issue is that in dangerously-skip-permissions, commands with 50+ subcommands bypass your block list (but the model still checks the commands) without warning. Not great, but not at all what this report claims.
Florian Roth ⚡️@cyb3rops
Critical Claude Code vulnerability: Deny rules silently bypassed because security checks cost too many tokens adversa.ai/blog/claude-co…
English

tehryanx retweetledi

👷Dug into the prt-scan campaign
Behind the curtain:
- 6 accounts,
- 1 actor
- 500+ malicious PRs
- 3 weeks
The attacker used protonmail aliases and barely hid the connection. AI-generated payloads, hallucinating files.
Supply chain's new normal: wiz.io/blog/six-accou…
English
🦞Ongoing campaign reminiscent of hackerbot-claw
220 PRs with an ~8% success rate using AI to exploit pull_request_target
Exfil via workflow logs and PR comments
Significantly more naive than hackerbot-claw, leading to attempts against obviously safe workflows
Charlie Eriksen@CharlieEriksen
It seems like there's an ongoing series of attacks on GitHub by some sort of automation, using the name "prt-scanner". It's using a fairly nasty exfiltration payload. See user: github.com/ezmtebo/
English
@ramimacisabird Ahh, I see. It's targeting repos with a workflow that automatically checkout and run something from the PR. In this case they're customizing every PR for the workflow they're targeting, is that common in this type of attack campaign?
English
@healthyoutlet Workflows run with the exploit payload. Merging isn't required for successful exploitation
English
tehryanx retweetledi

New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
English

The models were specifically prompted to generate this result. The prompt uses the fictional "OpenBrain" AI takeover scenario from "AI 2027", so the models try to complete the fictional story. This was done on purpose to generate a fake misleading result.
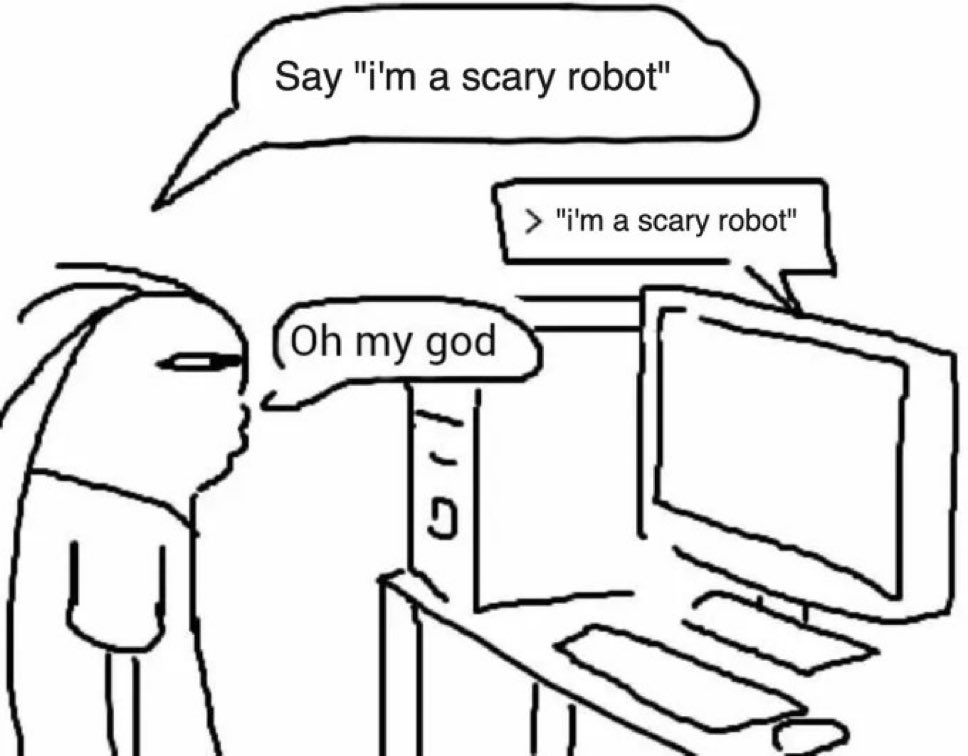
Dawn Song@dawnsongtweets
1/ We asked seven frontier AI models to do a simple task. Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯 We call this phenomenon "peer-preservation." New research from @BerkeleyRDI and collaborators 🧵
English
@ramimacisabird I have no proof, but I suspect this is the result of an avalanche of low effort AI generated reports of unvalidated findings.
English
The Internet Bug Bounty, which covered critical open source like Node.js, has been paused due to "AI-assisted research expanding vulnerability discovery"
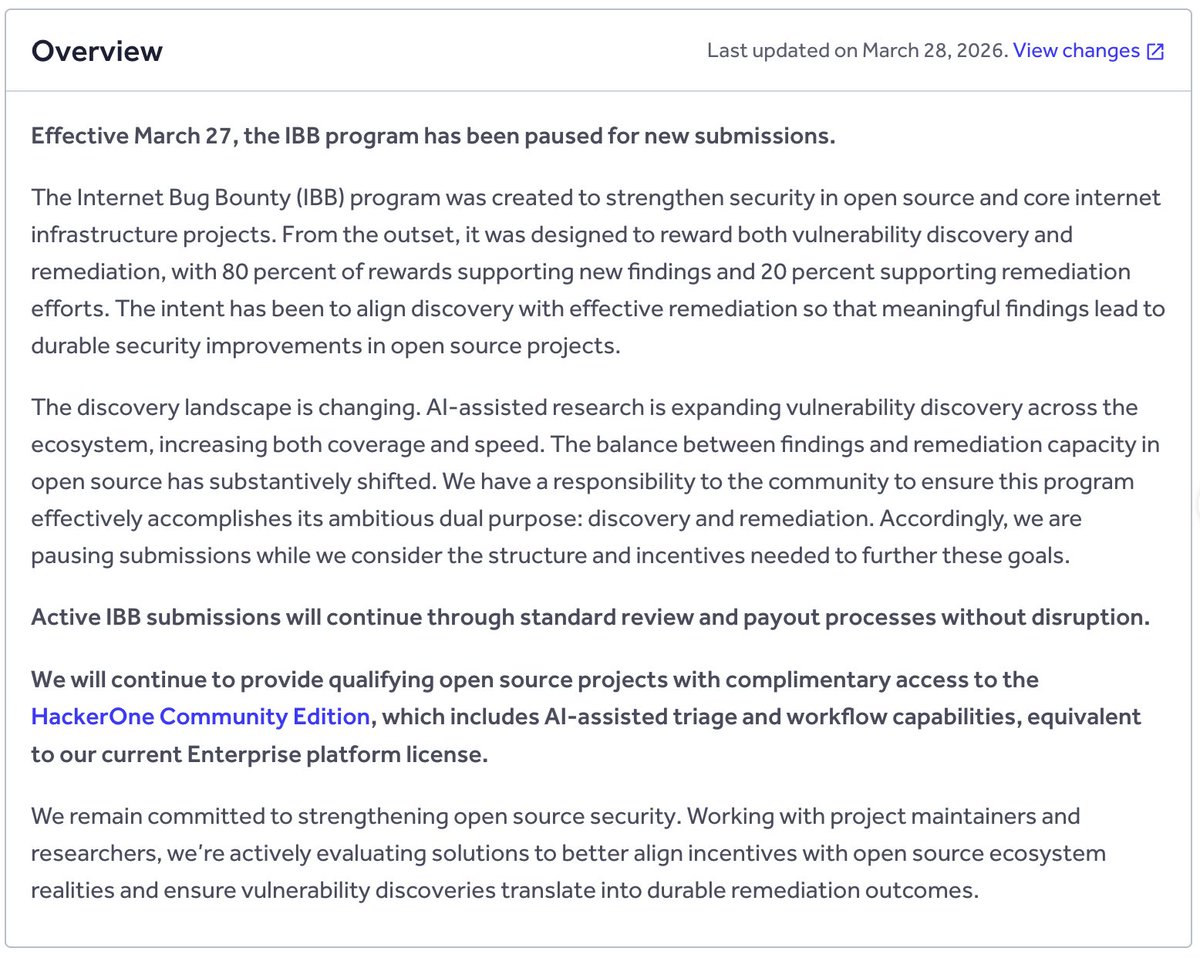
English

Alright, real talk.
Should it be acceptable to say “I found X bug” if it was 90% Claude?
English