Sabitlenmiş Tweet
ここ
253 posts



The 117th TCMV meeting started in Brussels two hours ago.
There will be a lunch break soon, after which the Netherlands will present and discuss Article 39 at 13:30 CET.
After 18 months and 1 million miles of testing Tesla's FSD, the RDW will inform all EU countries of their test results in a one-hour presentation. This briefing is necessary in preparation for the vote to approve FSD across the EU without further testing in each individual country.
The vote will take place at one of the next meetings, either at the end of June or the beginning of October.
For a proposal to be approved in a vote, it must receive the support of at least 15 out of 27 countries, which collectively represent at least 65% of the EU's population.
If the proposal is not approved in the vote for the whole EU, each country still has the option to adopt the RDW results and approve FSD for their own country.

English


That’s corporate lingo for “niggers” btw
Polymarket@Polymarket
JUST IN: McDonald’s to eliminate self-serve soda stations nationwide by 2032, citing “changing consumer habits”
English
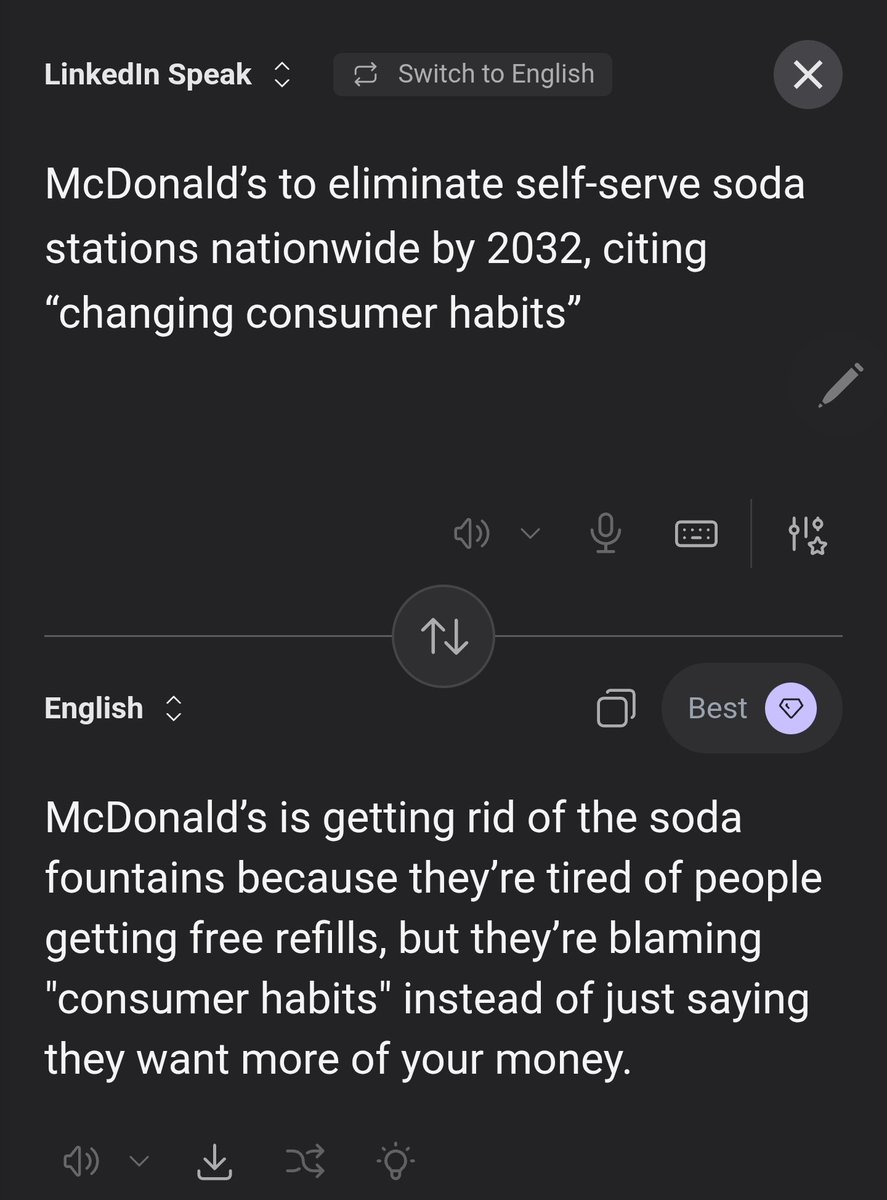

JUST IN: McDonald’s to eliminate self-serve soda stations nationwide by 2032, citing “changing consumer habits”
English


English

I don’t get why China is flooded with all the good accessories and merch and EU is left the „old“ stuff.
Why can’t I just order the ambient light upgrade for legacy Model Y like I would be Anker to if I was living in China?
Just ship it, I install it myself, no worries… dang it
English

🇨🇳 Tesla has added a Model Y single-person inflatable mattress to the Shop in China:
✅ ¥659 (~$91)
✅ Only for Model Y (not Model Y L)
shop.tesla.cn/product/model-…


Tsla Chan@Tslachan
$TSLA Tesla China Starts Selling Single-Person Model Y Air Mattress! 🥳🤯
English

NEWS: Sam Altman invites Elon Musk to OpenAI's GPT-5.5 launch party, says "world needs more love."
Altman is throwing a small celebration on May 5 to mark the release of OpenAI's latest model, GPT-5.5.
He shared an online RSVP form, with OpenAI's coding agent Codex helping pick attendees from the replies. Registration closed fast and Altman said bigger parties are coming.
Altman went a step further on X, telling Elon he "could come if he wants to," and adding "The world needs more love."
The unexpected olive branch comes just days after US District Judge Yvonne Gonzalez Rogers warned both men to "control your propensity to use social media to make things worse outside this courtroom" during their ongoing court battle.

English




@Dr_Gingerballs Change the graph to log scale and no one would care the CO2 ppm
English

This is one of the downsides to measuring and analyzing everything: it makes people neurotic.
Air has about 21% oxygen, the rest being mostly nitrogen, nitrogen, and CO2. An increase in CO2 of 1000 ppm implies a decrease in oxygen of 0.1%.
Humidity, or water vapor in the air, can displace oxygen on the order of 1%. So the nightly build up of CO2 this person experiences results in oxygen changes 10x smaller than natural variations due to humidity changes.
There is no problem to solve here. The solution is to simply stop worrying about CO2 concentration.
@levelsio@levelsio
I still haven't solved the CO2 bedroom challenge You open the window and you wake up from a 6am garbage truck or barking dogs and sunlight You close it, you suffocate in 1200 ppl at 5am I guess you really need some mini tube in your wall with a vent that opens and closed based on internal CO2 but how do I build that?
English


BREAKING: A conservative court packed with Trump-appointed judges just ruled to ROLL BACK access to the abortion pill.
This is a page straight out of extremist Republicans’ anti-abortion playbook.
Let me be clear: the abortion pill is safe and effective.
We must fight back.
English
Trump Steaks, Trump University, and now Trump Math.
If you got 600% reductions, you'd be getting money back.
Everyone knows that prices aren't down—they're up.
Aaron Rupar@atrupar
Trump: "We are delivering discounts with price differences of 600, 700, and sometimes even 800 percent reductions"
English

这个也太屌了!
这个中国开发者在飞机上用 MacBook 本地跑 Llama 70B,整整 11 小时没有网络,处理了完整的客户项目。
他坐在跨大西洋航班的靠窗位置,设备是 MacBook Pro M4,64GB 内存。机上 WiFi 要价 25 美元,他拒绝了。
没有云端 API,没有连接 Anthropic 或 OpenAI 的服务器,完全没有互联网。
只有一台本地运行的 Llama 3.3 70B(bf16)和他自己写的编排脚本。
模型通过 llama.cpp 运行。生成速度 71 tokens/秒,上下文约 60,000 tokens,内存占用 48.6 GiB / 64 GiB,起飞时电池剩余 3 小时 21 分钟。
起飞前他给编排器写了这样的系统提示:
"你是一个运行在单台 MacBook 上的离线编排器。没有网络。你唯一的资源是 /Users/dev/work 下的本地文件、localhost:8080 的 Llama 70B 推理服务,以及 3 小时 21 分钟的电池预算。处理 /Users/dev/work/queue.jsonl 中的任务队列(每行一个客户任务)。对每个任务:起草 → 运行本地评估 → 保存产物到 /Users/dev/work/done/。每 12 个任务保存一次上下文检查点,以便更换电池后恢复。仅在队列为空或电池低于 5% 时停止。"
所以这个系统完全清楚自己运行在什么资源上。
它知道自己未来 11 小时没有外部连接。它知道自己的内存和电池都是有限的。它知道在飞机降落之前不会有人类介入。
系统跑在一个循环里。从队列取任务,推理,保存产物,写检查点。一个接一个。
当电池低于 5% 时,编排器自动暂停,等待笔记本切换到备用充电宝,然后从最后一个检查点恢复。
这是系统在飞行中的日志:
"saved context checkpoint 8 of 12 (pos_min = 488, pos_max = 50118, size = 62.813 MiB)"
"restored context checkpoint (pos_min = 488, pos_max = 50118)"
"prompt processing progress: n_tokens = 50 / 60818"
"task 37016 done | tps = 71 s tokens text → /Users/dev/work/done/proposal_westside.md"
窗外是云层、蓝天,没有 WiFi。托盘上是一台 MacBook,一个打开的终端,两个屏幕,一个 localhost 推理服务。
这是过去一年里我见过的最漂亮的离线 AI 工作流:
11 小时飞行,WiFi 费用 0 美元,所有客户队列在降落前全部清空。
这个故事的核心不是技术多牛(llama.cpp 跑 70B 现在很常规),而是一个完整的离线自主工作流,编排器理解自己的资源约束,自动管理电池和检查点,没人干预干了 11 小时。
这种"self-aware computing"的感觉确实挺酷的!
x.com/i/status/20499…
Blaze@browomo
This Chinese developer launched Llama 70B locally on a MacBook on a plane and for a full 11 hours without internet ran client projects. He was sitting by the window on a transatlantic flight with a MacBook Pro M4 with 64 GB of memory. WiFi on board cost $25 for the flight. He declined. No cloud API, no connection to Anthropic or OpenAI servers, no internet at all. Just a local Llama 3.3 70B on bf16 and his own orchestrator script. The model runs through llama.cpp. Generation speed, 71 tokens per second. Context around 60,000 tokens. Memory usage, 48.6 GiB out of 64. Battery at takeoff, 3 hours 21 minutes. And he gave the orchestrator this system prompt before takeoff: "You are an offline orchestrator running on a single MacBook. There is no network. The only resources you have are local files in /Users/dev/work, the Llama 70B inference server at localhost:8080, and a battery budget of 3 hours 21 minutes. Process the queue at /Users/dev/work/queue.jsonl (one client task per line). For each task: draft → run local evals → save artefact to /Users/dev/work/done/. Save context checkpoints every 12 tasks so you can resume after a battery swap. Stop only on empty queue or when battery drops below 5%." So the system knows exactly what resources it is running on. It knows it has no connection to the outside world for the next 11 hours. It knows it has finite memory and a finite battery. It knows the human will not intervene until the plane lands. The system runs in 1 loop. Takes a task from the queue, runs it through inference, saves the artifact, writes a checkpoint. Task after task, just like that. And only when the battery drops below 5% does the orchestrator automatically pause, waits for the laptop to switch to the backup power bank, and continues from the last checkpoint. Here is what the system actually writes in his log during the flight: "saved context checkpoint 8 of 12 (pos_min = 488, pos_max = 50118, size = 62.813 MiB)" "restored context checkpoint (pos_min = 488, pos_max = 50118)" "prompt processing progress: n_tokens = 50 / 60 818" "task 37016 done | tps = 71 s tokens text → /Users/dev/work/done/proposal_westside.md" Outside the window, clouds, blue sky, and no WiFi. On the tray, 1 MacBook, an open terminal on 2 screens, and an inference server on localhost. From what I have observed, this is the cleanest offline AI workflow I have seen in the past year: 11 hours of flight, $0 for WiFi, and the entire client queue closed before landing.
中文
@DevinOlsenn There are so many retards can't even read 2 sentences,
1) walk away from my car without pressing a single button on a fob AND
2) automatically lock the doors and roll the windows up
Or they are so butthurt because their car can never update after leaving dealership.
English

I made this post to highlight a cool feature that Teslas have.
I can walk away from my car and without pressing a single button on a fob or my phone and the car will automatically lock the doors and roll the windows up.
I did research this before making my post and there are only a few other companies that offer this. BYD, Volvo, etc. however the majority of companies do not have this exact functionality.
LOTS of other cars let you hold down a button on the fob to close the windows, and that’s neat - but it’s not the seamless experience that Tesla offers.
Anyways - I’ve never in my life seen a more triggered group of individuals. HUNDREDS of comments telling me how their 20+ year old car can do the same thing, and how unsafe it is that Tesla offer this, etc.
Despite my best efforts to reply to everyone in a civil manor and help clarify what I meant it seems like the comments section has just become a cesspool.
Anyways - for those of you with a Benz Patent-Motorwagen or a 30 year old Honda civic, I’m so happy that you apparently have the same features as Tesla… so sorry for ever insinuating that your car is inferior in anyway to a Tesla, it won’t happen again.
Devin Olsen@DevinOlsenn
Close Windows on Lock is such a great feature, hard to believe Tesla is one of the only car companies that does this. @Tesla
English

很简单啊,就是防止你到了美国后,上街游行拍照申请政庇的。
申请时,问你一遍,你说没有,记录下来;你到了美国说被迫害,撒谎。
申请时,你回答受迫害,嗯,移民倾向,拒签。
马努·吉诺比利✨✨✨银河舰队@ManuGinobili007
这是什么节奏?
中文

If your mum’s parents are both Greek, how the hell is your mum half Canadian?
English

The Supreme Court just eviscerated the Voting Rights Act.
Trump and Republicans are rigging the rules to suppress the right to vote.
If that’s the game, Democratic states must fight back to protect our democracy.
English


NEW: Claude-powered coding agent reportedly deleted a company’s production database, and backups, in 9 seconds.
English

茶叶也不安全了‼️😱
居然是在恶臭的公厕晒出来的‼️😱
浙江丽水茶农在异味很大的公厕晾茶叶
而且不止一家这么干
怎么,这是新品尿香茶?🤢
4月20日,被游客曝光后
官方就一句批评教育过去了……
看来官方认为这不算事🤡
以后我不喝中国茶了
本来以为食品不安全
没想到茶叶也可以这么恶心
没有信仰的人真是什么都干得出来🤢
食品安全在中国就是笑话
就这还天天嘲笑日本物价高
中国物价确实低
就是省下来的钱不知道够不够买命🤡


中文
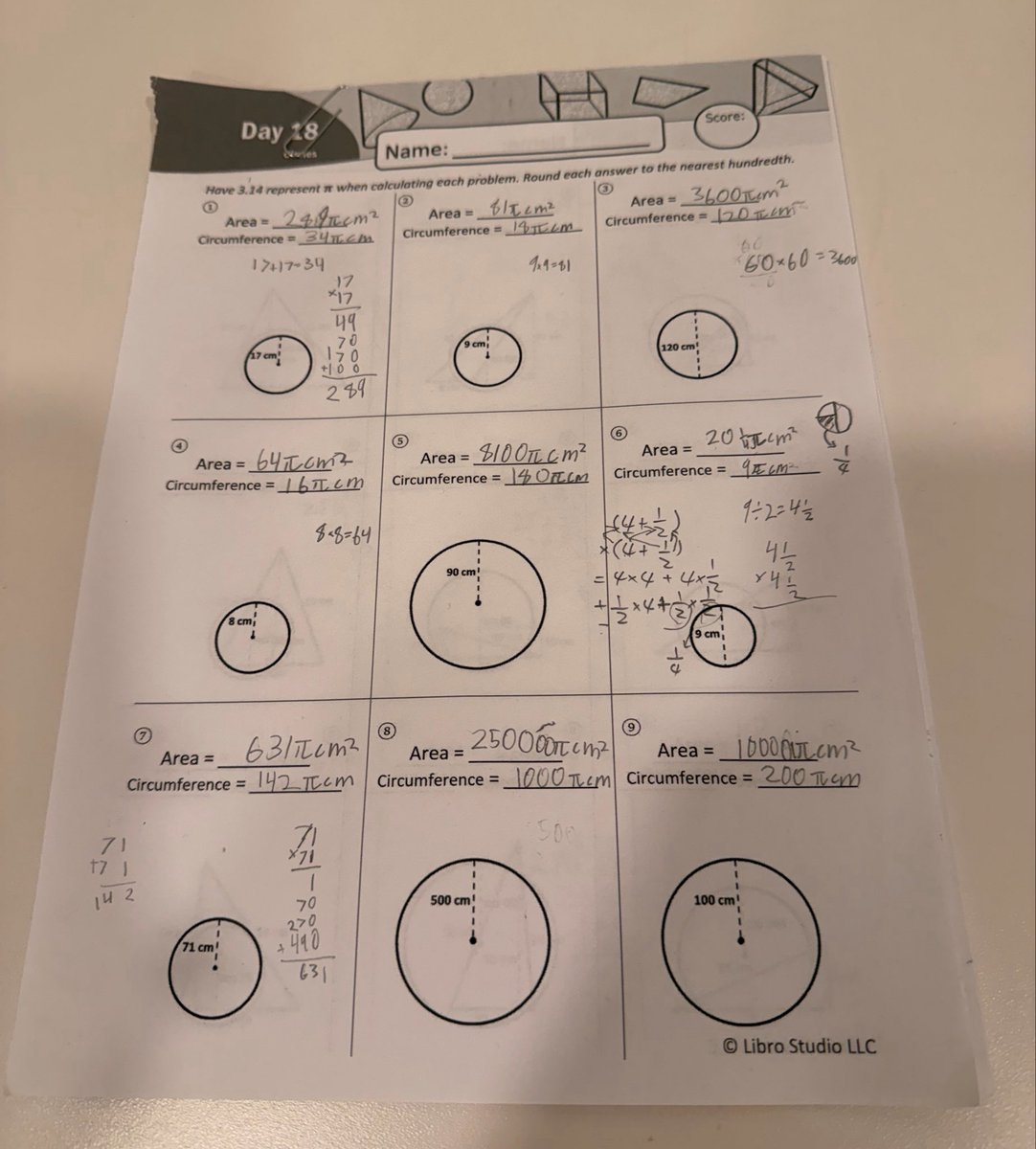
@yunta_tsai Questions 3 and 4 did not state the line pass through the center 😆
English

One thing I like about geometry homework is that it visualizes the use cases of multiplication, division, fractions, and why numbers can be irrational — instead of memorization.
Many parents formulate their kids' education based on college admissions, but as current college admissions have become disconnected from applied knowledge, I decided to pursue what made me interested in engineering in the first place.
English