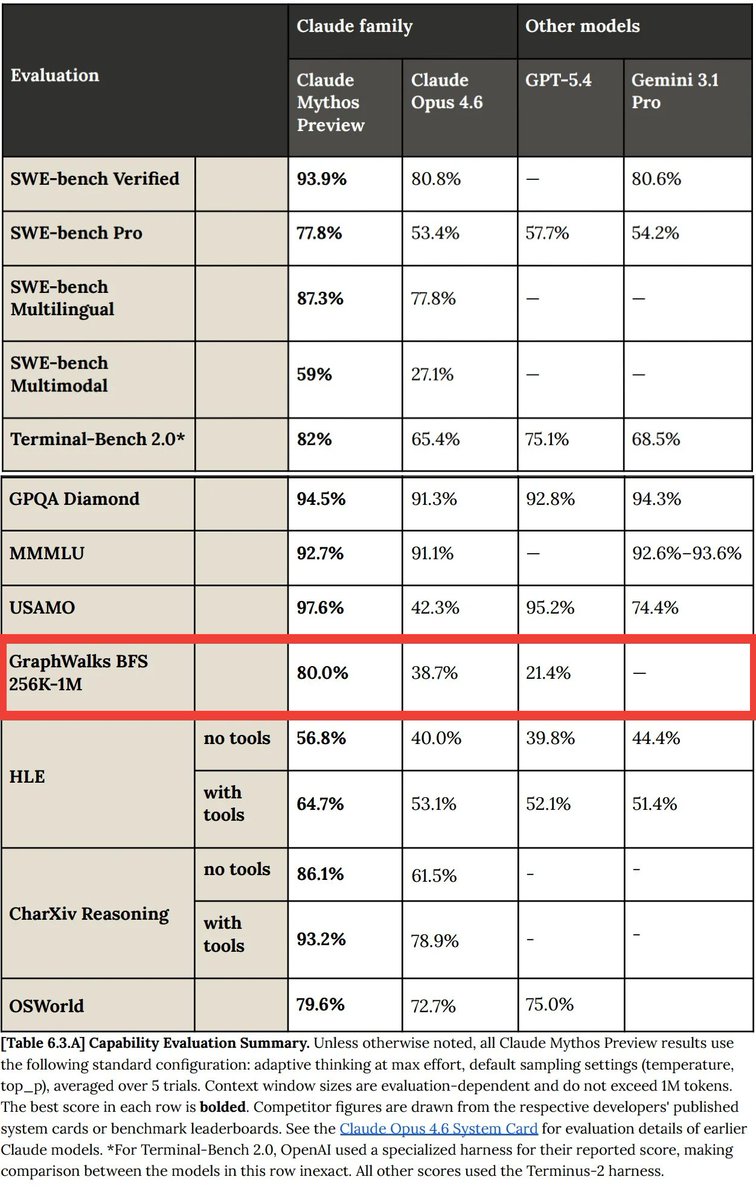
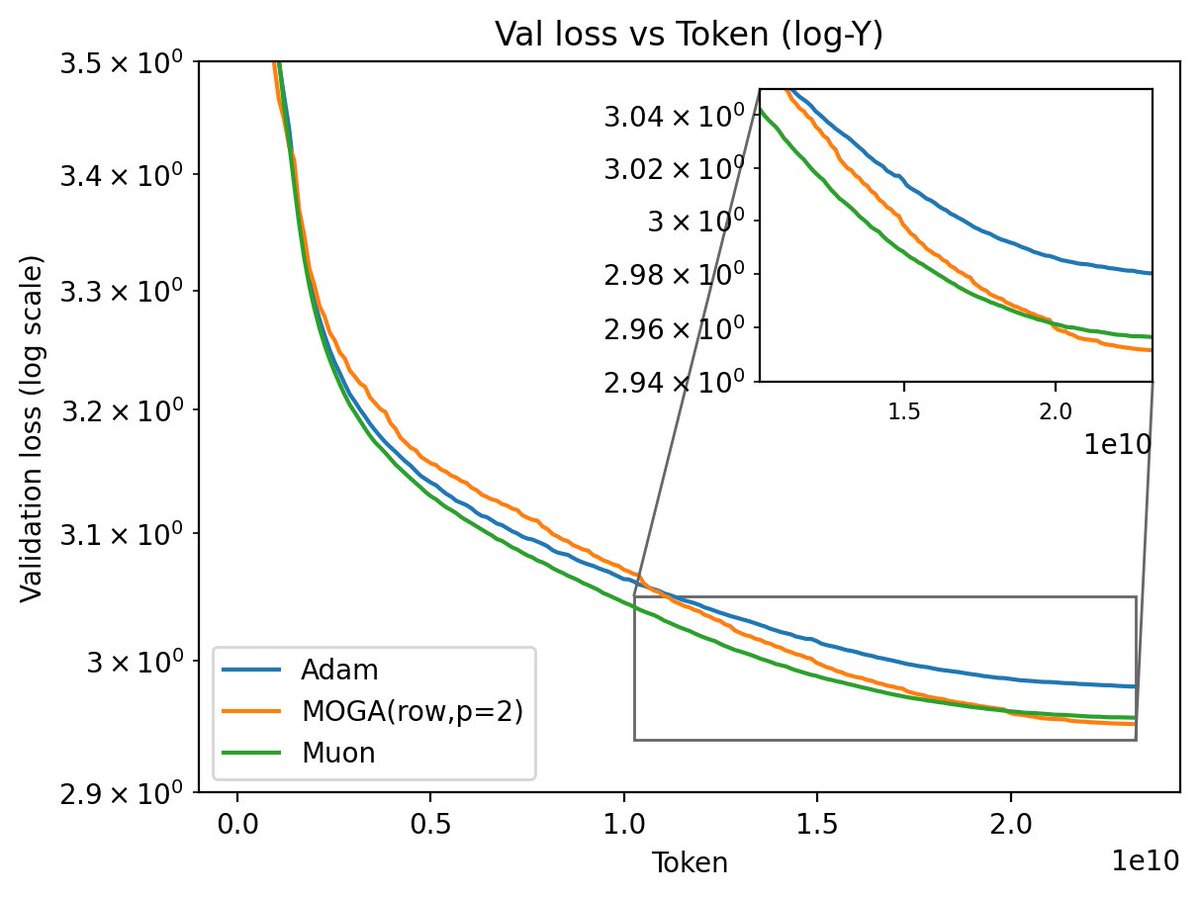
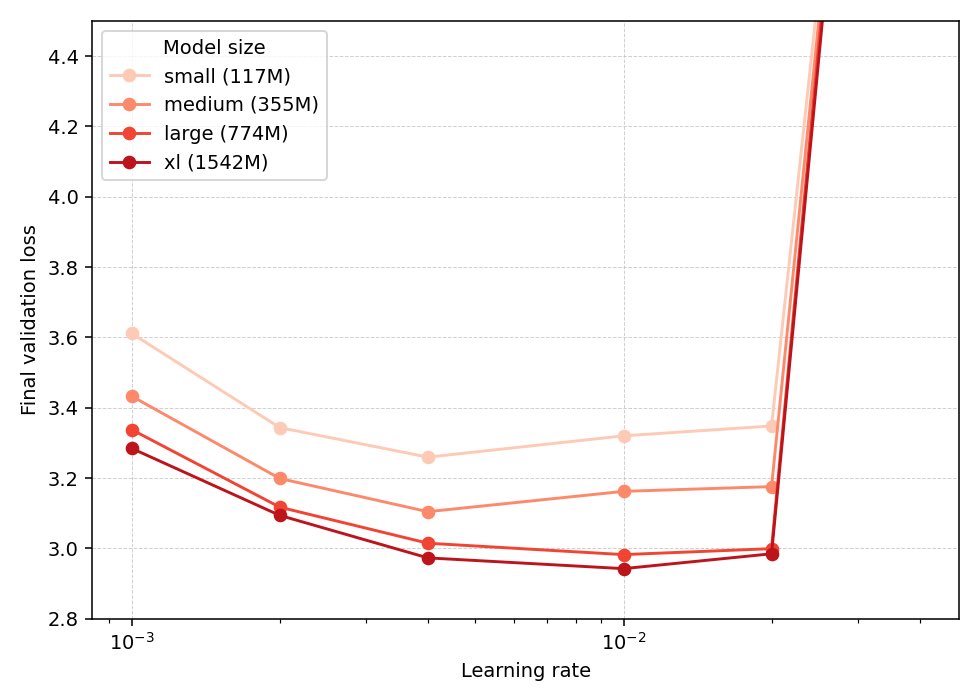
Haodong Wen retweetledi

I won't be at ICLR this year but @xingyudang will help present Fantastic Optimizers arxiv.org/abs/2509.02046!
Stop by at Pavilion 4 P4 5309 this afternoon to see what we have found in extensive sweeping and more importantly, what we learned after the paper that leads to Hyperball!
English